
Journal of Geo-information Science >
Research on Chinese Fine-grained Geographic Entity Recognition Model based on Joint Lexicon Enhancement
Received date: 2022-07-01
Revised date: 2022-07-27
Online published: 2023-06-02
Supported by
Shandong Natural Science Foundation(ZR2021MD068)
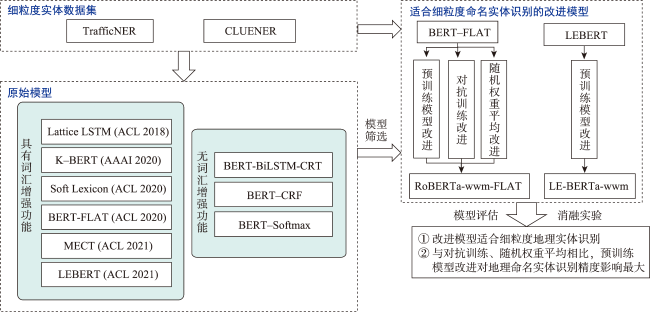
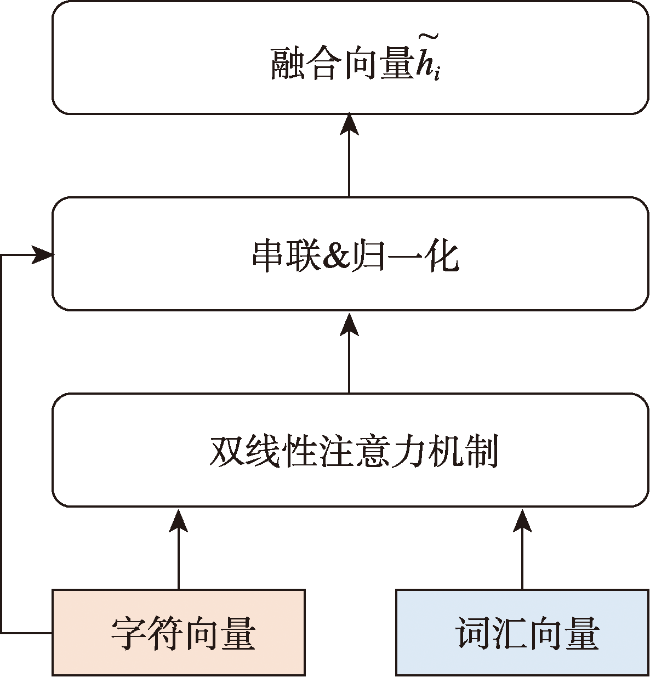
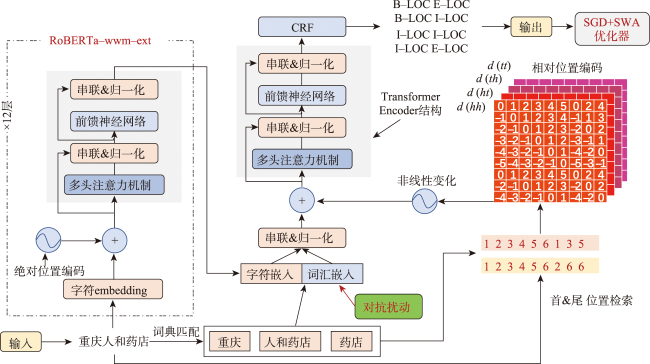
Named Entity Recognition (NER) is the basis of many researches in natural language processing. NER can be defined as a classification task. The aim of NER is to locate named entities from unstructured texts and classify them into different predefined categories. Compared with English, Chinese have the features of flexible formation and no exact boundaries. Because of the features of Chinese and the lack of high-quality Chinese named entity datasets, the recognition of Chinese named entities is more difficult than English named entities. Fine-grained entities are subdivisions of coarse-grained entities. The recognition of Chinese fine-grained named entities especially Chinese fine-grained geographic entities is even more difficult than that of Chinese named entities. It is a great hardship for Chinese geographic entity recognition to take both accuracy and recall rate into account. Therefore, improving the performance of Chinese fine-grained geographic entities recognition is quite necessary for us. In this paper we proposed two Chinese fine-grained geographic entity recognition models. These two models are based on joint lexical enhancement. Firstly, we injected the vocabulary into the experimental models. The vocabulary was considered as the 'knowledge' in the models. Then we explored the appropriate fine-grained named entity recognition method based on vocabulary enhancement. And we found two models, BERT-FLAT and LEBERT, that were suitable for fine-grained named entity recognition. Secondly, to further improve the performance of these two models in fine-grained geographical named entities recognition, we improved the above two models with lexical enhancement function in three aspects: pre-training model, adversarial training, and stochastic weight averaging. with these improvements, we developed two joint lexical enhancement models: RoBERTa-wwm-FLAT and LE-RoBERTta-wwm. Finally, we conducted an ablation experiment using these two joint lexical enhancement models. We explored the impacts of different improvement strategies on geographic entity recognition. The experiments based on the CLUENER dataset and one microblog dataset show that, firstly, compared with the models without lexical enhancement function, the models with lexical enhancement function have better performance on fine-grained named entities recognition, and the F1-score was improved by about 10%; Secondly, with the improvements of pre-training model, adversarial training, and stochastic weight averaging, the F1-score of the fine-grained geographic entity recognition task was improved by 0.36%~2.35%; Thirdly, compared with adversarial training and stochastic weight averaging, the pre-trained model had the greatest impact on the recognition accuracy of geographic entities.
LI Fadong , WANG Haiqi , KONG Haoran , LIU Feng , WANG Zhihai , WANG Qiong , XU Jianbo , SHAN Yufei , ZHOU Xiaoyu , YAN Feng . Research on Chinese Fine-grained Geographic Entity Recognition Model based on Joint Lexicon Enhancement[J]. Journal of Geo-information Science, 2023 , 25(6) : 1106 -1120 . DOI: 10.12082/dqxxkx.2023.220464
表1 CLUENER数据集与TrafficNER数据集数据详情Tab. 1 CLUENER dataset and TrafficNER dataset data details |
| 数据集 | 数据类型 | 数据来源 | 实体标签类别 | 文本数量/条 |
|---|---|---|---|---|
| CLUENER | 新闻文本 | CLUENER | 10 | 12 091 |
| TrafficNER | 社交文本 | 网络爬虫 | 4 | 4000 |
表2 细粒度地理命名实体筛选词类别Tab. 2 Fine-grained geographic named entity filter word categories |
| 类别 | 实体示例 | |
|---|---|---|
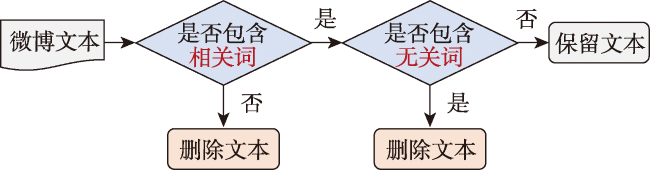
| 相关词 | 事故触发词 | 发生、碰撞等 |
| 方位词 | 向东、东侧等 | |
| 道路特征词 | 路、街、交叉口等 | |
| 地名特征词 | 院、馆、楼等 | |
| 无关词 | 事发地点模糊 | 高速、乡道、国道等 |
| 交通宣传 | 整治、开展、咨询等 | |
| 非现实车祸 | 女主、男主、电影等 | |
| 情绪宣泄 | 人生、情绪、厌倦等 | |
| 统计文本 | 一季度、增幅等 |
表3 CLUENER数据集数据标签Tab. 3 CLUENER dataset data labels |
| 实体名称 | 实体示例 | 实体数量/条 |
|---|---|---|
| 地址(address) | XX省XX市XX区XX街XX门牌号 | 3 193 |
| 书名(book) | 小说、教材书、杂志等 | 1 283 |
| 公司(company) | XX公司、XX集团、XX银行等 | 3 263 |
| 政府(government) | 中央行政机关以及地方行政机关 | 2 041 |
| 游戏(game) | 常见的游戏 | 2 612 |
| 电影(movie) | 电影、记录片等 | 1 259 |
| 姓名(name) | 一般为人名 | 4 112 |
| 组织机构(organization) | 篮球队、足球队、乐团、社团等 | 3 419 |
| 职位(position) | 职称等 | 3 477 |
| 景点(scene) | 常见的旅游地点 | 1 661 |
表4 环境配置详情Tab. 4 Environment Configuration Details |
| 项目 | 详情 |
|---|---|
| GPU | GTX 1650 GTX 1080Ti |
| 内存 | 16 GB 128 GB |
| 操作系统 | Windows 11 Window server 2012 |
| CUDA | 11.2 10.0 |
| 编程语言 | Python3.7 |
| 深度学习框架 | Pytorch-gpu 1.7.1 Pytorch-gpu 1.4.0 TensorFlow-gpu 1.14.0 |
表5 基于词汇增强细粒度实体识别结果Tab. 5 Fine-grained entity Recognition results based on vocabulary enhancement |
| 方法 | TrafficNER | CLUENER | |||||
|---|---|---|---|---|---|---|---|
| Precision/% | Recall/% | F1-score/% | Precision/% | Recall/% | F1-score/% | ||
| LEBERT | 94.40 | 94.85 | 94.55 | 80.70 | 84.32 | 82.45 | |
| BERT-FLAT | 94.36 | 94.61 | 94.47 | 83.88 | 82.50 | 83.03 | |
| Lattice LSTM | 87.58 | 86.99 | 88.18 | 71.04 | 67.71 | 69.33 | |
| K-BERT | 88.00 | 87.20 | 87.60 | 79.20 | 82.50 | 80.80 | |
| Soft Lexicon | 87.17 | 88.11 | 87.63 | 75.76 | 73.44 | 74.58 | |
| MECT | 88.06 | 88.93 | 88.49 | 76.75 | 77.25 | 77.00 | |
| BERT-Softmax | 89.76 | 89.46 | 89.10 | 79.42 | 79.92 | 79.67 | |
| BERT-BiLSTM-CRF | 88.73 | 90.75 | 89.73 | 66.81 | 76.92 | 71.51 | |
| BERT-CRF | 89.99 | 90.82 | 90.40 | 79.81 | 80.96 | 80.38 | |
表6 基于词汇增强联合模型的细粒度地理实体识别结果Tab. 6 Results of fine-grained geographic entity recognition based on lexicon enhanced joint model (%) |
| 方法 | 实体类别 | TrafficNER | CLUENER | ||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-score | Precision | Recall | F1-score | ||
| LE-RoBERTa-wwm | 全部实体 | 94.62 | 94.98 | 94.72 | 82.27 | 84.02 | 83.09 |
| 地名 | 93.65 | 95.34 | 94.49 | 74.93 | 77.61 | 76.25 | |
| 机构名 | 95.90 | 95.10 | 95.50 | 79.09 | 78.06 | 78.57 | |
| LEBERT | 全部实体 | 94.40 | 94.85 | 94.55 | 80.70 | 84.32 | 82.45 |
| 地名 | 94.00 | 95.37 | 94.68 | 73.94 | 77.67 | 75.76 | |
| 机构名 | 95.36 | 96.41 | 95.88 | 78.54 | 79.02 | 78.78 | |
| RoBERTa-wwm-FLAT | 全部实体 | 94.72 | 93.77 | 94.23 | 84.65 | 84.67 | 84.57 |
| 地名 | 93.90 | 94.48 | 94.19 | 77.42 | 78.14 | 77.78 | |
| 机构名 | 96.00 | 92.69 | 94.32 | 80.69 | 75.31 | 77.91 | |
| BERT-FLAT | 全部实体 | 94.36 | 94.61 | 94.47 | 83.88 | 82.50 | 83.03 |
| 地名 | 93.48 | 94.19 | 93.83 | 75.72 | 75.50 | 75.61 | |
| 机构名 | 94.80 | 94.21 | 94.50 | 82.44 | 69.74 | 75.56 | |
| BERT-Softmax | 全部实体 | 89.76 | 89.46 | 89.10 | 79.42 | 79.92 | 79.67 |
| 地名 | 86.16 | 89.86 | 87.97 | 66.85 | 65.42 | 66.12 | |
| 机构名 | 81.01 | 88.48 | 84.58 | 79.89 | 79.02 | 79.45 | |
| BERT-BiLSTM-CRF | 全部实体 | 88.73 | 90.75 | 89.73 | 66.81 | 76.92 | 71.51 |
| 地名 | 88.20 | 88.81 | 88.50 | 53.32 | 73.19 | 61.69 | |
| 机构名 | 86.46 | 91.24 | 88.79 | 59.67 | 69.75 | 64.32 | |
| BERT-CRF | 全部实体 | 88.73 | 90.75 | 89.73 | 66.81 | 76.92 | 71.51 |
| 地名 | 88.20 | 88.81 | 88.50 | 53.32 | 73.19 | 61.69 | |
| 机构名 | 86.46 | 91.24 | 88.79 | 59.67 | 69.75 | 64.32 | |
表7 消融实验结果Tab. 7 Ablation results (%) |
| 方法 | 实体类别 | TrafficNER | CLUENER | ||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-score | Precision | Recall | F1-score | ||
| RoBERTa-wwm-FLAT | 地名 | 93.90 | 94.48 | 94.19 | 77.42 | 78.14 | 77.78 |
| 机构名 | 96.00 | 92.69 | 94.32 | 80.69 | 75.31 | 77.91 | |
| RoBERTa-wwm-FLAT (w/o SWA) | 地名 | 93.62 | 94.59 | 94.10 | 78.65 | 76.20 | 77.41 |
| 机构名 | 95.06 | 92.97 | 94.00 | 83.57 | 69.26 | 75.74 | |
| RoBERTa-wwm-FLAT (w/o FGM) | 地名 | 93.40 | 94.35 | 93.87 | 75.61 | 78.32 | 76.94 |
| 机构名 | 95.22 | 92.07 | 93.62 | 82.60 | 70.84 | 76.27 | |
| RoBERTa-wwm-FLAT (w/o PTM) | 地名 | 93.83 | 93.51 | 93.67 | 77.38 | 75.38 | 76.37 |
| 机构名 | 94.52 | 92.76 | 93.63 | 84.13 | 71.80 | 77.48 | |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
李玉森, 张雪英, 袁正午. 面向GIS的地理命名实体识别研究[J]. 重庆邮电大学学报(自然科学版), 2008, 20(6):719-724.
[
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
乐小虬, 杨崇俊, 刘冬林. 空间命名实体的识别[J]. 计算机工程, 2005, 31(20):49-50,53.
[
|
| [28] |
|
| [29] |
|
| [30] |
毛波, 滕炜. 基于条件随机场与规则改进的复杂中文地名识别[J]. 武汉大学学报(工学版), 2020, 53(5):447-454.
[
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}