
Journal of Geo-information Science >
Online Tracking Registration Method based on Indoor Space Layout Constraints
Received date: 2022-10-20
Revised date: 2022-12-13
Online published: 2023-06-30
Supported by
Natural Science Foundation of China(42071385)
Shandong Offshore Aerospace Equipment Technology Innovation Center Project(HHCXZX-2021-12)
Yantai Science and Technology Innovation Development Plan Key R&D Category(2022MSGY062)
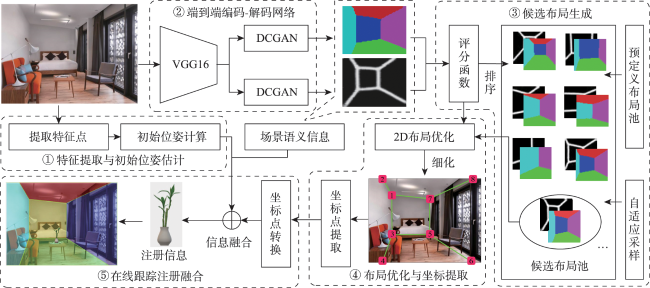
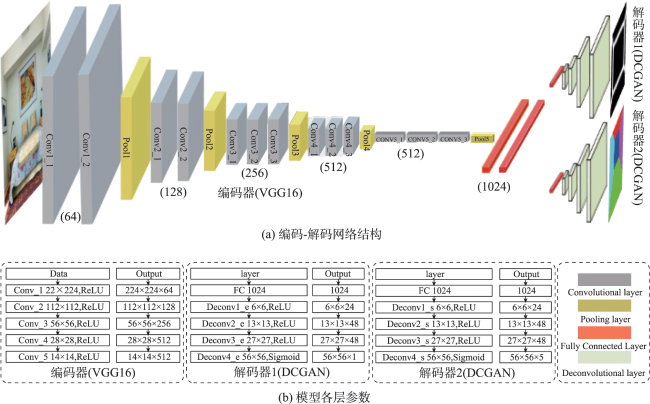
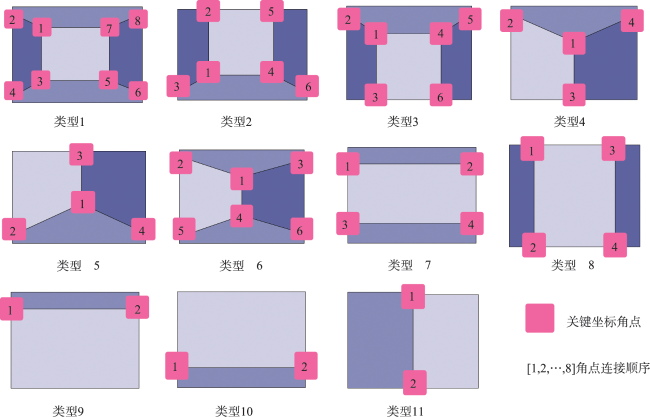
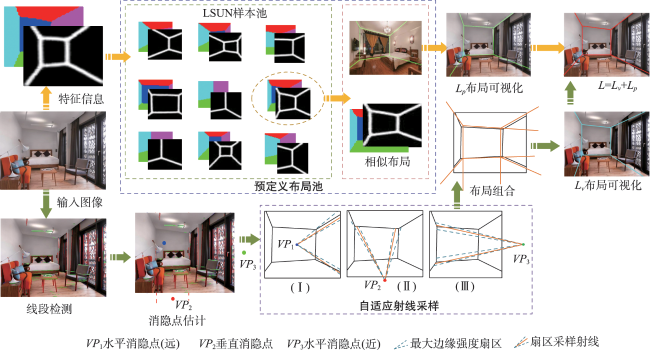
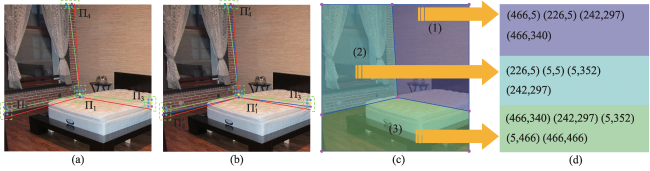
The integration of mobile augmented reality and geographic information system is becoming an ideal platform for spatial information visualization. Aiming at the problems of the inaccurate description of indoor spatial information location, weak reasoning spatial structure, and limited scene understanding ability in existing augmented reality tracking and registration techniques, this paper proposes an online learning tracking and registration method under spatial layout constraints. Firstly, the image feature matching algorithm is used to estimate the relative initial pose of the camera. Next, the end-to-end encoding-decoding network is used to extract the edge and semantic feature information of the indoor scene, and the 2D layout hypothesis is generated. Then the greedy strategy is used to refine the 2D layout hypothesis and extract the key coordinate point information of the corresponding layout. Finally, the semantic feature and the key coordinate point of the layout are taken as constraints to jointly optimize the initial pose of spatial information. In the complex indoor scene, the maximum position error of the registered virtual model is 9 cm, the maximum scaling error is 17%, and the maximum rotation error is 16 °. The experimental results show that the proposed method can add constraints to spatial information registration and achieve accurate registration in indoor scenes with a strong scene understanding ability.

CAO Xingwen , WU Mengquan , ZHENG Xueting , ZHENG Hongwei , LI Yingxiang , ZHANG Anan . Online Tracking Registration Method based on Indoor Space Layout Constraints[J]. Journal of Geo-information Science, 2023 , 25(7) : 1418 -1431 . DOI: 10.12082/dqxxkx.2023.220806
表1 特征点检测结果Tab. 1 Experimental result in detecting features |
| 编号 | 特征点数/个 | 特征检测/ms | 计算描述符 /ms | 特征匹配 /ms |
|---|---|---|---|---|
| 图像1 | 138 | 16.13 | 15.48 | 140.74 |
| 图像2 | 128 | 15.23 | 14.02 | 134.62 |
| 图像3 | 161 | 25.87 | 22.20 | 161.13 |
| 图像4 | 143 | 18.62 | 17.41 | 141.58 |
表3 在线跟踪注册定量评估结果Tab. 3 Online tracking registration quantitative evaluation results |
| 物体(PS/R) | Avg. RMSE Position/m | Avg. RMSE Scaling/% | Avg. RMSE Rotation/° | ||||||
|---|---|---|---|---|---|---|---|---|---|
| x | y | z | x | y | z | y | |||
| 转椅(15/7) | 0.04 | 0.03 | 0.02 | 9 | 7 | 11 | 8 | ||
| 书籍(31/13) | 0.02 | 0.01 | 0.03 | 16 | 12 | 14 | 9 | ||
| 桌子(12/5) | 0.10 | 0.07 | 0.09 | 8 | 10 | 17 | 11 | ||
| 沙发(9/5) | 0.08 | 0.07 | 0.09 | 7 | 10 | 14 | 12 | ||
| 电脑(25/8) | 0.02 | 0.03 | 0.02 | 9 | 13 | 11 | 6 | ||
| 时钟(17/4) | 0.01 | 0.02 | 0.02 | 6 | 5 | 8 | 7 | ||
| 柜子(23/6) | 0.04 | 0.06 | 0.04 | 13 | 7 | 17 | 16 | ||
表4 注册过程时间开销明细Tab. 4 Computation time details for registration process (ms) |
| 场景 | 注册时间 | ||||
|---|---|---|---|---|---|
| 初始位姿 | 布局生成 | 布局优化 | 姿态优化 | 总注册时间 | |
| 场景Ⅰ | 312.30 | 134.26 | 23.94 | 21.73 | 492.23 |
| 场景Ⅱ | 310.56 | 135.17 | 24.11 | 19.52 | 489.36 |
| 场景Ⅲ | 335.44 | 138.13 | 36.47 | 44.37 | 554.41 |
| 场景Ⅳ | 327.72 | 135.79 | 36.56 | 38.26 | 538.33 |
| 场景Ⅴ | 322.46 | 136.68 | 35.93 | 37.19 | 532.26 |
| 平均时间 | 321.70 | 136.01 | 31.40 | 32.21 | 521.32 |
| [1] |
杜清运, 刘涛. 户外增强现实地理信息系统原型设计与实现[J]. 武汉大学学报·信息科学版, 2007, 32(11):1046-1049.
[
|
| [2] |
别勇攀, 关庆锋, 姚尧. 基于边云协同的AR空间分析计算框架[J]. 地球信息科学学报, 2020, 22(6):1383-1393.
[
|
| [3] |
|
| [4] |
孙敏, 陈秀万, 张飞舟, 等. 增强现实地理信息系统[J]. 北京大学学报(自然科学版), 2004, 40(6):906-913.
[
|
| [5] |
|
| [6] |
邓晨, 游雄, 张威巍, 等. 基于2D地图的城市户外ARGIS视觉辅助地理配准技术[J]. 测绘学报, 2019, 48(10):1305-1319.
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
张一, 姜挺, 江刚武, 等. 特征法视觉SLAM逆深度滤波的三维重建[J]. 测绘学报, 2019, 48(6):708-717.
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}