
Journal of Geo-information Science >
Urban Hotspot Detection from the Data Stream of Taxi Pick-up and Drop-off based on Distributed Multistage Grid Clustering
Received date: 2022-10-05
Revised date: 2022-12-25
Online published: 2023-06-30
Supported by
Fund of Hubei Luojia Laboratory, China(220100010)
Key Science and Technology Program of Hubei Province, China(2020AAA004)
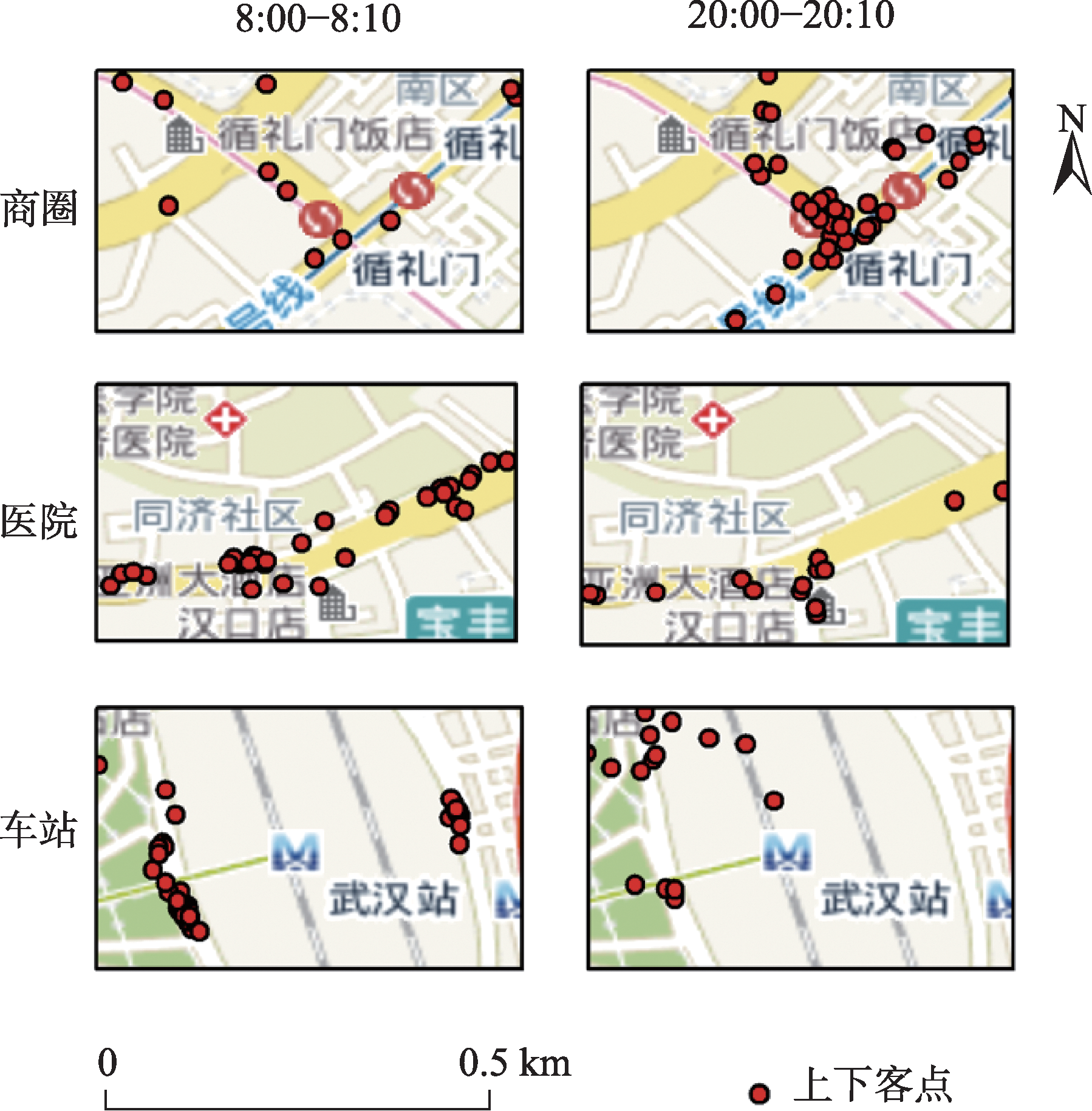
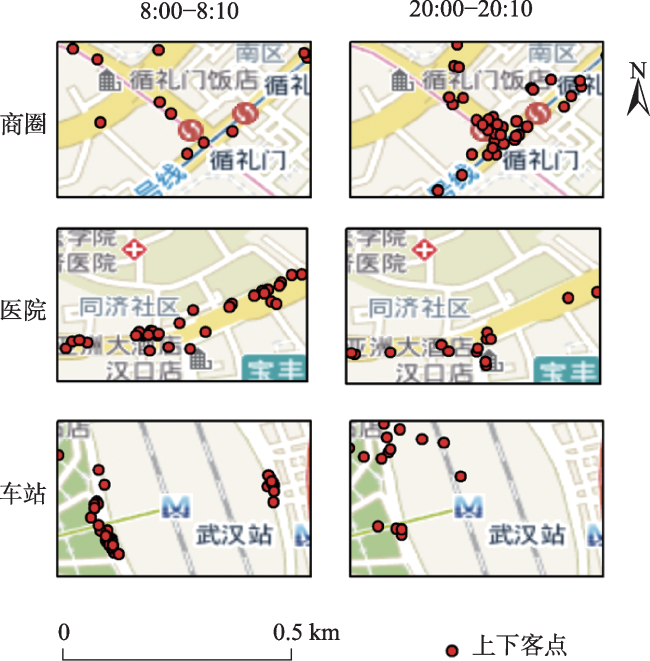
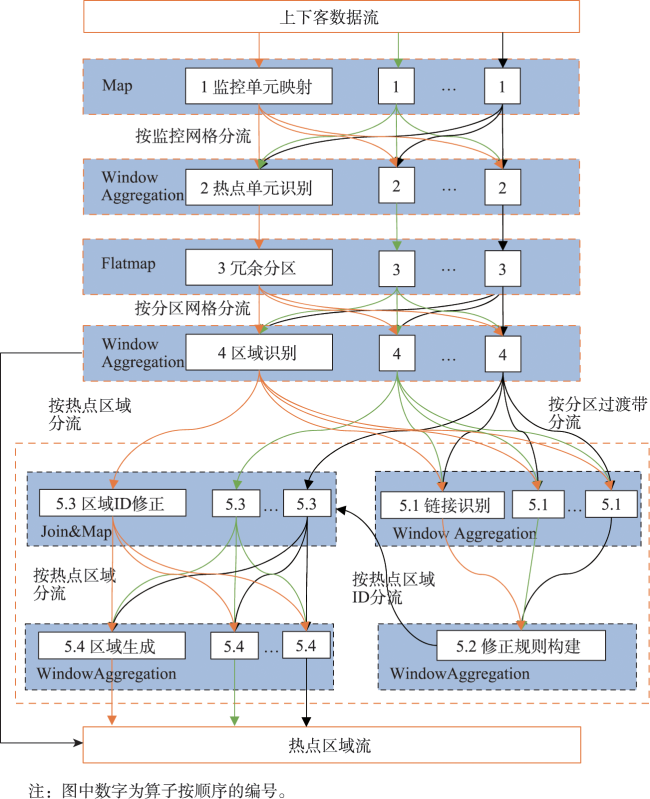
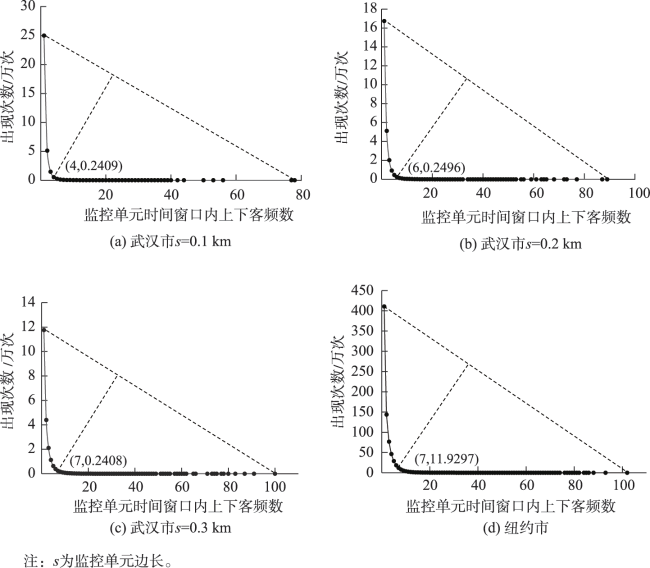
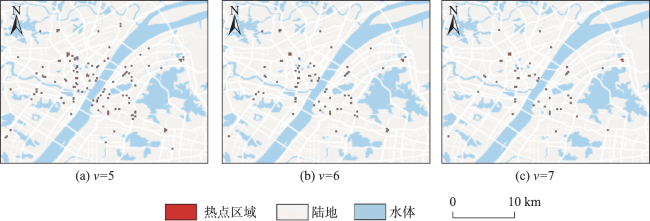
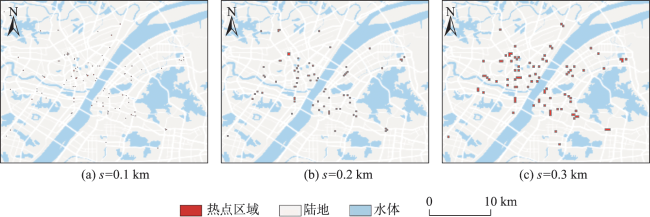
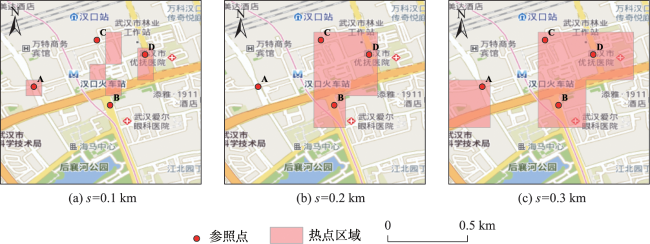
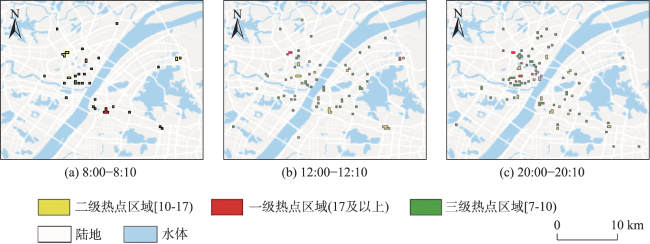
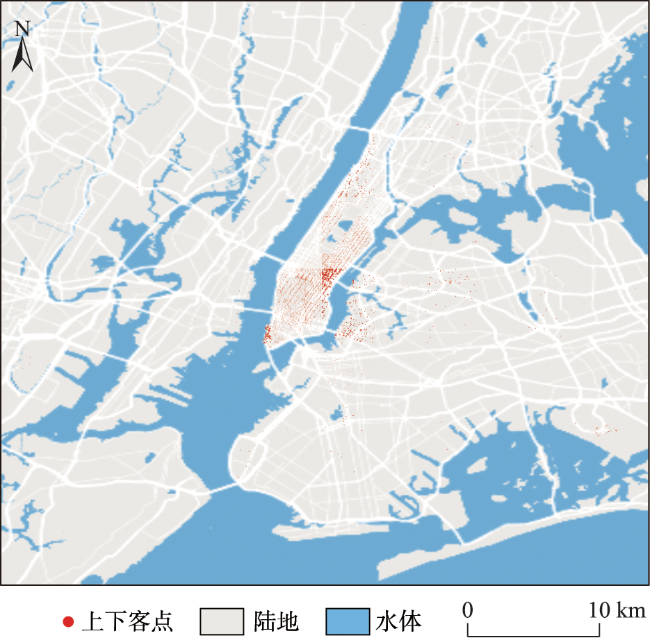
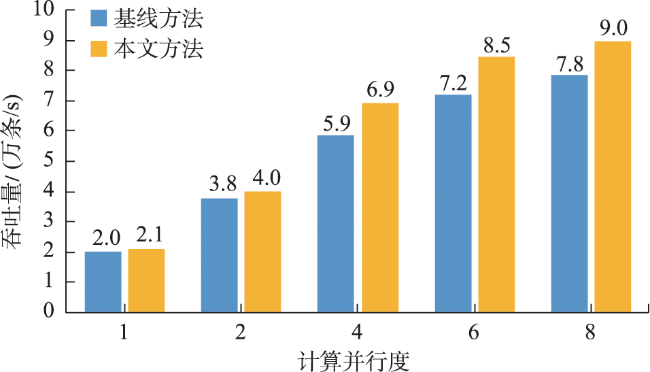
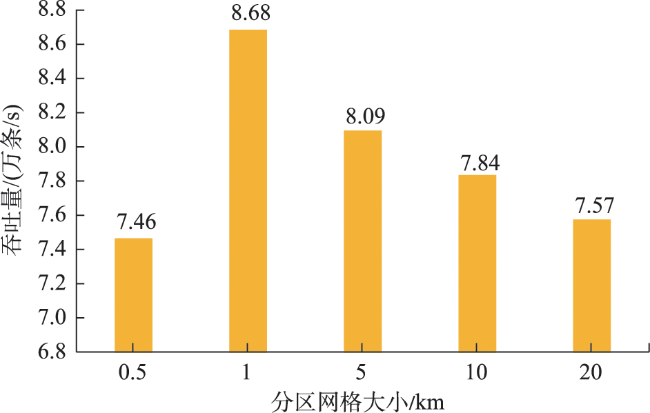
Real-time identification of urban hotspot areas can improve the response ability of city managers on emergencies. With the development of the Internet of Things and communication technology, the starting and ending information of taxi trips can be uploaded to the data center in real-time, forming a massive and continuous data stream of pick-up and drop-off events. Taxi is a welcoming means of transportation, and have characteristics of all-weather operation, full regional coverage, and high spatial-temporal resolution, so its pick-up and drop-off data stream can be used as a high-quality data source for real-time identification of urban hotspots. However, the hotspots area identification methods aimed at historical data sets have a high delay and can’t meet the real-time requirement. At the same time, the existing clustering algorithm based on distributed streaming processing technology is difficult to meet all the requirements including low aggregation cost, good scalability, and supporting arbitrary shape cluster recognition when facing pick-up and drop-off streams. Based on the distributed stream processing technology, an urban hotspot area identification method suitable for taxi pick-up and drop-off data stream is designed in this study. By mapping the real-time pick-up and drop-off records to grid monitoring units, we can obtain the heat value of each monitoring unit for each time window, filter the monitoring units which have higher heat values than a specified threshold as hot units, and finally gather the hot units of same time window into hotspot areas. To avoid the performance bottleneck of the aggregation operator in distributed region identification, a multi-stage distributed hot area aggregating method is designed. The method is implemented on Apache Flink, and the pick-up and drop-off data stream is simulated with the historical taxi trip records from Wuhan and New York City. The results show that: (1) The spatial distribution and status of hotspots differ from time to time, which is related to citizens' activities at different times; (2) Using smaller monitoring units can get finer spatial positions of each hotspot area; (3) Our method can accurately identify the hotspot areas using different parameter pair of monitoring unit sizes and hotspot thresholds; (4) The method has excellent throughput which increases with the computing parallelism and reaches 90k/s with parallelism at 8. The proposed method can correctly capture the spatial distribution of urban hotspot areas of each period in real-time and has good performance and scalability.
WANG Haocheng , XIANG Longgang , GUAN Xuefeng , ZHANG Yeting . Urban Hotspot Detection from the Data Stream of Taxi Pick-up and Drop-off based on Distributed Multistage Grid Clustering[J]. Journal of Geo-information Science, 2023 , 25(7) : 1514 -1530 . DOI: 10.12082/dqxxkx.2023.220753
表1 符号定义Tab. 1 Symbol definition |
| 符号 | 定义 |
|---|---|
| 上下客数据流 | |
| 上下客记录 | |
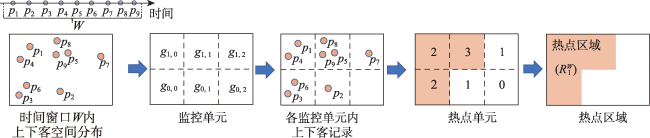
| 监控单元 | |
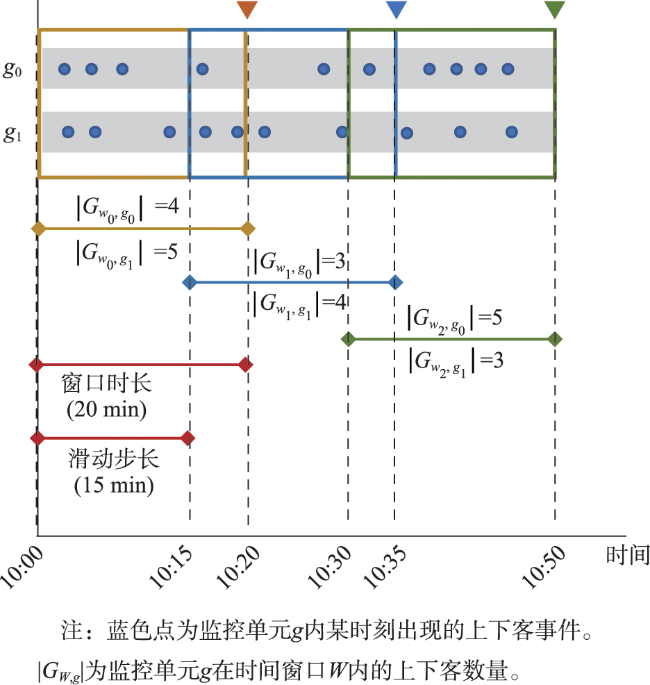
| 时间窗口 | |
| 热点阈值 | |
| 时段 下的热点监控单元 | |
| 时段 下ID为 的热点区域 |
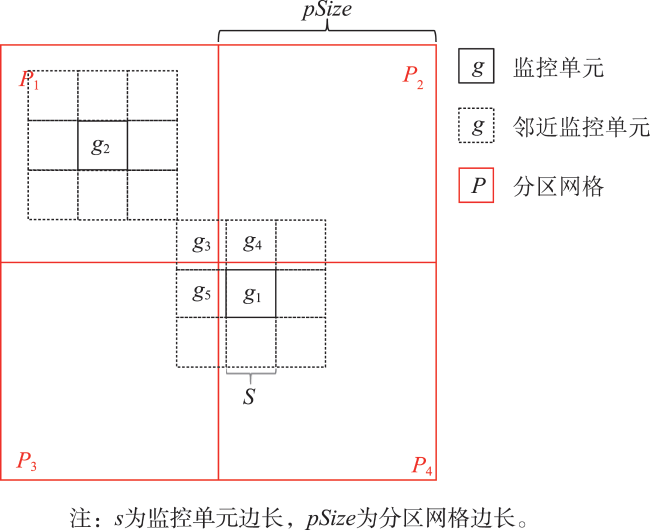
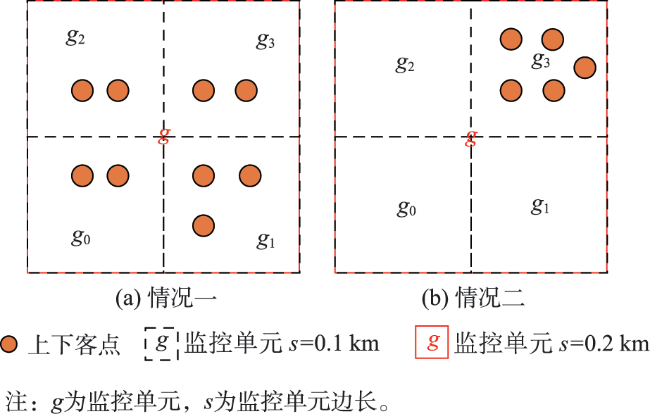
| 算法 1 冗余分区 |
|---|
| 输入:监控单元 分区网格大小 输出:分配至分区网格后的二元组 |
| 1 获取 所在分区网格 2 输出 并标记 已访问 3 遍历 的邻近监控单元 4 获取 所在分区网格 ,若 未被访问过 5 输出 6 标记 已访问 |
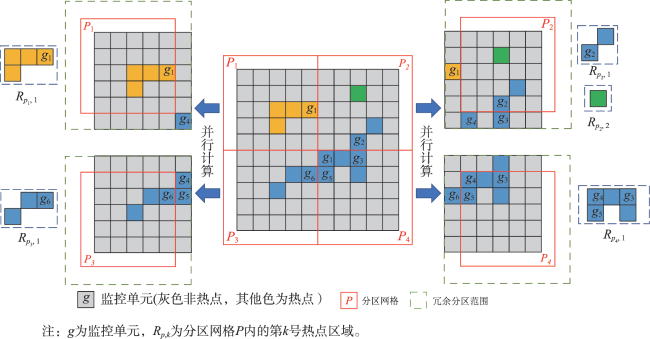
| 算法 2 区域识别 |
|---|
| 输入:热点单元子集 输出:全局区域流 子区域流 过渡带单元流 |
| 1 初始化 2 遍历 中的监控单元 3 若 为本地网格且未被访问过 4 自增 5 初始化新的区域 6 初始化flag为假 7 初始化栈Stack; 入栈 8 While 9 取栈顶 并将其加入 10 标记 已访问 11 遍历 的邻近单元,记为 12 若 且为未访问的本地单元 13 入栈 14 若 且为未访问的外来单元 15 获取 的原分区 16 置flag为真 17 若 :输出 至 18 否则,输出 至 19 若flag为假:输出 至 20 否则,输出 至 |
| 算法 3 链接识别 | |
|---|---|
| 输入: 内属于分区过渡带 、窗口 的数据集 输出:链接对数据流 | |
| 1 初始化以 为键、区域ID为值的 2 对 中的每一个 3 若 5 否则 7 对 中的每一个 8 若在 中可得键为 的值 9 输出 至 | |
| 算法 4 修正规则构建 |
|---|
| 输入: 时间窗口 中接收的链接对数据集 输出:修正规则流 |
| 1 初始化以区域ID为键和值的Map 2 对 中每个链接对 3 若Map中没有键为 或 的条目 4 Map.put 5 Map.put 6 否则,若Map仅有键为 的条目 7 令 8 9 否则,若Map仅有键为 的条目 10 令 11 12 否则: 13 ; 14 若 : 15 对Map中的每个条目 16 当 17 = 18 输出 至 |
表3 集群软件版本Tab. 3 Deployment details of experimentation clusters |
| 软件名称 | 版本 |
|---|---|
| Java | JDK 1.8.0_261 |
| Apache Flink | 1.13.3 |
| Apache Kafka | 2.6.0 |
| Apache Zookeeper | 3.6.2 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
吴华意, 黄蕊, 游兰, 等. 出租车轨迹数据挖掘进展[J]. 测绘学报, 2019, 48(11):1341-1356.
[
|
| [5] |
唐炉亮, 郑文斌, 王志强, 等. 城市出租车上下客的GPS轨迹时空分布探测方法[J]. 地球信息科学学报, 2015, 17(10):1179-1186.
[
|
| [6] |
唐炉亮, 阚子涵, 刘汇慧, 等. 网络空间中线要素的核密度估计方法[J]. 测绘学报, 2017, 46(1):107-113.
[
|
| [7] |
羊琰琰. 基于出租车GPS数据的热点区域识别及寻客推荐模型研究[D]. 北京交通大学, 2020.
[
|
| [8] |
谷岩岩, 焦利民, 董婷, 等. 基于多源数据的城市功能区识别及相互作用分析[J]. 武汉大学学报·信息科学版, 2018, 43(7):1113-1121.
[
|
| [9] |
|
| [10] |
王宇环, 靳诚, 杜家禛. 基于多源数据的成都市居民出行热点时空特征分析[J]. 南京师范大学学报(工程技术版), 2020, 20(2):80-87.
[
|
| [11] |
|
| [12] |
周勍, 秦昆, 陈一祥, 等. 基于数据场的出租车轨迹热点区域探测方法[J]. 地理与地理信息科学, 2016, 32(6):51-56,127.
[
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}