
Journal of Geo-information Science >
The Method of Extracting Names of Geo-science Data based on Regular Expressions
Received date: 2022-12-02
Revised date: 2023-04-07
Online published: 2023-07-14
Supported by
National Key Research and Development Program(2020YFE0200700)
Geoscientific data represent important supporting information in geoscientific and technological documents. A large number of geoscientific and scientific documents contain research data information, and the data name that reflects the basic content of data acts as the core information. Automatic extraction of research data names from geoscientific and technological documents is of great significance for promoting the sharing of high-quality geoscientific data, reproducing literature experiments and results, and realizing the correlation between scientific data and scientific and technological documents. It can potentially address the problem of insufficient utilization of data information in current geoscientific documents. Through reading a large number of geoscientific documents, this study analyzes the texts, structure characteristics, and expression characteristics of data names existing in paragraphs which describe the data source information, and proposes an automatic extraction method for the names of geoscientific data by summarizing the description rules of geoscientific data names. This method uses data category feature words as rule triggers, uses regular expressions to write extraction rules, and constructs a regular extraction rule library to complete the extraction of data name information from geoscientific documents. Finally, the name extraction program of geoscientific data is written in Java language, and the name information extraction from geoscientific data is carried out using geoscientific literature texts as the experimental data. The experimental results show that this method can effectively extract the name information of research data from geoscientific and scientific documents, with an accuracy of 62%.
CAO Qiaozhuoran , WANG Sisi , CHEN Zugang , LI Guoqing , LI Jing . The Method of Extracting Names of Geo-science Data based on Regular Expressions[J]. Journal of Geo-information Science, 2023 , 25(8) : 1601 -1610 . DOI: 10.12082/dqxxkx.2023.220945
表1 地学数据名称信息提取规则库Tab. 1 Extraction rules base of name information of geological data |
| 编号 | 数据名称实例 | 数据名称模式 | 正则表达式 |
|---|---|---|---|
| 1 | 1980—2016年逐日最高气温、最低气温、太阳辐射和风速等数据 | 数据时间(最小粒度为年)跨度+(数据空间位置)+数据主题+数据类型 | (\\d{4}年?s?[-|—|~|到|至]?\\d{4}年){1}[/|\\u4E00-\\u9FA5|\\w|[(\\w|\\u4E00-\\u9FA5)|(\\w|\\u4E00- \\u9FA5)]|、:“”‘’'()《》〔〕…—~-]+(信息|数据|数据集|资料|图|产品|样本|模型){1}" |
| 2 | 北京市城六区范围内居住小区的数据 | 数据空间位置+数据主题+数据 类型 | ((\\w|\\u4E00-\\u9FA5)+(省|市|自治区|地区|特别行政区|流域|区域|高原|平原|区))*[\\w|\\u4E00-\\u9FA5 |[(\\w|\\u4E00-\\u9FA5)]|[(\\w|\\u4E00-\\u9FA5)]|:|、|“|”|.|-|—|/|\\+]+(数据|数据集|资料|图|产品|样本){1} |
| 3 | 1:5 000中国地形图 | 国家基本比例尺+制图区域+制图主题+(地)图 | (\\d:[\\d.\\d|\\d{1,}]*){1}[\\u4E00-\\u9FA5]*(图|图数据){1} |
| 4 | 人口自然增长率数据 | (数据空间位置)+数据主题+数据类型 | \\b[\\w|\\u4E00-\\u9FA5|[(\\w|\\u4E00-\\u9FA5)|(\\w|\\u4E00-\\ u9FA5)|∶|-|—|.||“|”|°|×|/ |:|&|-]]+(数据|数据集|资料|产品|样本|模型|信息){1} |
| 5 | 2017-1-1-2019-12-31所有Landsat8(USGSLandsat8SurfaceReflectanceTier1)影像 | 数据时间(最小粒度为日)跨度+(数据空间位置)+数据主题+数据类型 | (\\d{4}年?[—|-]\\d{1,2}月?[—|- ]?(\\d{1,2})?日?[-~到至和]?\\d{4}年?[-|~]\\d{1,2}月?[—|-]?(\\d {1,2})?日?){1}[\\u4E00-\\u9FA5 |\\w|、:“”‘'()《》 〔〕…—-,]+(信息|数据|数据集|资料|图|产品|样本){1} |
| 6 | 中国物候数据(1963—2009 年) | (数据空间位置)+数据主题+数据类型+括号后补充内容 | [\\u4E00-\\u9FA5|\\w|:]+(信息|数据|数据集|资料|图|产品|影像|样本|模型){1}\\(([^}]*)\\)| [\\u4E00-\\u9FA5|\\w|:]+(数据|数据集|资料|图|产品|影像|样本|模型){1}(([^}]*)) |
| 7 | Landsat5 MSS、Landsat5 TM、Landsat7 ETM+SLC -off遥感影像 | 多个传感器/卫星并列+影像类型数据 | [a-z|0-9]+([+-、])*[\\u4E00-\\u9FA5]*(影像|遥感数据|影像数据){1} |
| 8 | 2004—2011年覆盖西部冰川区的Landsat TM/ETM+遥感影像 | 数据时间(最小粒度为年)跨度+(数据空间位置)+传感器/卫星名称+影像类型数据 | ((\\d{4})*年*\\s*[-|—|~|到|至|和]*\\s*\\d{4}\\s*年){1}[\\u4E00- \\u9FA5|a-z|0-9|\\W]*(影像|遥感数据|影像数据){1} |
| 9 | 全国2000—2010年1 km网格土地利用数据 | 特定的空间位置+数据时间(最小粒度为年)跨度+数据主题+数据 类型 | (中国|全国|全球|我国|美国){0,1} (\\d{4}年)*[\\w|\\u4E00-\\u9FA5| (\\d{4}年*[-|—|~|到|至|和]*\\d {4}年)?]+(数据|数据集|资料|图|产品|影像|样本|模型){1} |
| 10 | Landsat TM/ETM+遥感影像 | 传感器名称/卫星名称+影像 | [(A-Z|0-9|\\S]*(影像){1} |
| 11 | 班轮运输能力指数 | (数据空间位置)+数据主题+指数/参数类数据 | \\b[\\w|\\u4E0-\\u9FA5|[(\\w|\\u4E00-\\u9FA5)|:|-|—|(\\w| \\u4E00-\\u9FA5)|.|、|“|”]]+(指数|参数){1} |
| 12 | 安徽省1980、1995、2000、2005、2010、2015年1:100万土地利用数据 | 数据空间位置+并列时间年份+数据主题+数据类型 | ([\\w|\\u4E00-\\u9FA5]+(省|市|自治区|地区|特别行政区|流域|区域|高原|平原|中国|我国|全球|流域))* (\\d{4}年*、){1,}[\\w|\\u4E0 0-\\u9FA5|[(\\w|\\u4E00-\\u9FA5)]|:]*(数据|数据集|资料|图|产品|样本|模型){1} |
| 13 | 1990年北京地区1 km×1 km高分辨率MODIS数据 | 数据年份+(数据空间位置)+数据主题+数据类型 | \\d{4}年[、:“”‘’'() 《》 〔〕…—~|(\\u4E00-\\u9FA5)|/|a-z |×|0-9]+(数据|数据集|资料|产品|影像|样本|模型){1} |
| 14 | LandsatETM、MODIS和高分遥感影像 | 多个传感器/卫星并列+中文并列词+传感器/卫星名称+影像主题+影像类型数据 | [a-z|0-9]+和[a-z|0-9]+([+-、])* [\\u4E00-\\u9FA5]*(影像|遥感数据|影像数据){1} |
表2 数据名称信息抽取实验结果(部分)Tab. 2 Experiment results of data name information extraction (Part of all results) |
| 文献标题 | 专家提取结果 | 本研究提取结果 | 对应的提取规则 |
|---|---|---|---|
| 1998—2012 年中国耕地复种指数时空差异及动因 | 耕地面积数据,农作物播种面积数据,农民人均经营耕地、农村居民家庭人均经营纯收入、成灾受灾比数据,人口非农业化比重数据 | [本文所用的耕地面积数据, 农作物播种面积数据, 农民人均经营耕地、农村居民家庭人均经营纯收入、成灾受灾比数据, 人口非农业化比重数据, 香港、澳门和台湾地区由于数据] | \b[\\w|\\u4E00-\\u9FA5|[(\\w|\\u4E00-\\u9FA5)|:|-|—|(\\w|\\u4E00-\\u9FA5)|.|、|“|”]]+(数据|数据集|资料|产品|样本|模型){1} |
| 2000—2010年广州市住房产权管理角色变化分析 | 广州市“五普”和“六普”中的住房来源数据 | [数据来源于广州市“五普”和“六普”中的住房来源数据] | \\b[\\w|\\u4E00-\\u9FA5|[(\\w|\\u4E00-\\u9FA5)|:|-|—|(\\w|\\u4E00-\\u9FA5)|.|、|“|”]]+(数据|数据集|资料|产品|样本|模型){1} |
| 2004—2011年中国省域生态补偿差异分析 | 中国各省的森林面积、草地面积、农田(农用地)面积、湿地面积、荒漠面积(沙化土地)、河流和湖泊面积以及各省的相关经济社会数据 | [本文需要获得中国各省的森林面积、草地面积、农田(农用地)面积、湿地面积、荒漠面积(沙化土地)、河流和湖泊面积以及各省的相关经济社会数据] | \\b[\\w|\\u4E00-\\u9FA5|[(\\w|\\u4E00-\\u9FA5)|:|-|—|(\\w|\\u4E00-\\u9FA5)|.|、|“|”]]+(数据|数据集|资料|产品|样本|模型){1} |
| 1961—2010年中国十大流域水分盈亏量时空变化特征 | 全国743个站1961—2010年的月平均气温、平均最高气温、平均最低气温、平均相对湿度、平均风速、月日照时数、月降水量等气候要素站点观测资料 | [1961—2010年的月平均气温、平均最高气温、平均最低气温、平均相对湿度、平均风速、月日照时数、月降水量等气候要素站点观测资料] | (\\d{4}年?s?[-|—|~|到|至|和]?\\d{4}年){1}[\\u4E00-\\u9FA5|\\w|[(\\w|\\u4E00-\\u9FA5)|(\\w|\\u4E00-\\u9FA5)]|、:“”‘’'()《》 〔〕…—~-]+(信息|数据|数据集|资料|图|产品|样本|模型){1} |
| 水量统一调度以来黄河内蒙古河段耗水量分析 | 1999—2011年黄河引退水资料,1999—2011年黄河干流和有关支流不同时间尺度的水文数据 | [引退水资料, 黄河干流和有关支流不同时间尺度的水文数据] | \\b[\\w|\\u4E00-\\u9FA5|[(\\w|\\u4E00-\\u9FA5)|:|-|—|(\\w|\\u4E00-\\u9FA5)|.|、|“|”]]+(数据|数据集|资料|产品|样本|模型){1} |
表3 抽取结果统计Tab. 3 Statistics of extraction results |
| 2015年 | 2020年 | ||
|---|---|---|---|
| 统计指标 | 统计结果 | 统计指标 | 统计结果 |
| 标准数据名称 信息项数(M) | 278 | 标准数据名称 信息项数(M) | 334 |
| 抽取数据名称 信息项数(N) | 430 | 抽取数据名称 信息项数(N) | 472 |
| 正确抽取信息 项数(K) | 247 | 正确抽取信息 项数(K) | 316 |
| 准确率(P)/% | 57 | 准确率(P)/% | 67 |
| 抽全率(R)/% | 89 | 抽全率(R)/% | 95 |
| F值(F) | 0.69 | F值(F) | 0.79 |
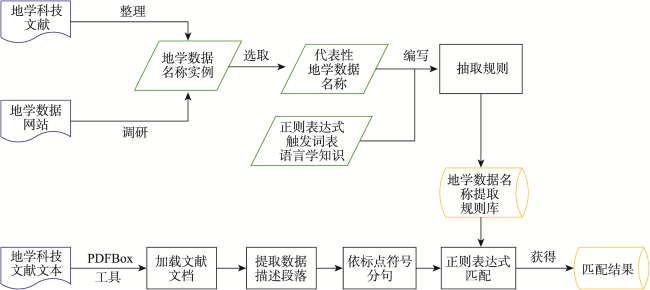
尽管如此,出于对文献格式框架严谨与规范的考虑,地学科技文献在行文结构上具有一些共性特征。科技文献中的每一章节都明确地展示了特定的信息[7]。科技文献全文由标题、作者、摘要、关键词、引言、正文、结论、致谢和参考文献9个部分组成。在地学科技文献中,作者通常会专门撰写一个介绍和说明研究数据的段落,从中可以获取研究数据名称信息。这个段落大多出现在文献正文的前部位置,例如引言后的第二或者第三个写作段落。此类段落多以“研究数据”“研究区与资料”“研究概况”“数据来源”“数据收集与处理”等标签作为段落标题或小标题。这些标签信息可以用于识别定位,确定需要进行提取的文本内容范围。这部分文本小标题多以论文的1、2级标题编号开头(例如“1.”或“2.2”等),格式上左起顶格书写,小标题中包含关键词“研究区”“数据”或“资料”等。根据这些特征模式编写正则表达式,截取此类小标题和下一个小标题之间的文本,即可获取包含文献研究数据名称信息的段落。这样,待处理的文本范围,就从文献全文缩小到某一个段落,可大幅度提高提取效率。
| [1] |
冷伏海, 白如江, 祝清松. 面向科技文献的混合语义信息抽取方法研究[J]. 图书情报工作, 2013, 57(11):112-119.
[
|
| [2] |
徐雷, 秦翠玉, 李娇. 科技文献数据化及组织呈现路径研究[J]. 中国图书馆学报, 2022, 48(3):25-42.
[
|
| [3] |
邬伦, 刘瑜. 地理信息系统:原理、方法和应用[M]. 北京: 科学出版社, 2001.
[
|
| [4] |
李军, 周成虎. 地学数据特征分析[J]. 地理科学, 1999, 19(2):158-162.
[
|
| [5] |
|
| [6] |
郑影, 李大辉. 面向微博内容的信息抽取模型研究[J]. 计算机科学, 2014, 41(2):270-275.
[
|
| [7] |
敖龙, 谢海先. 科技文献信息抽取方法浅析[J]. 高校图书馆工作, 2022, 42(2):24-27.
[
|
| [8] |
秦彦霞, 张民, 郑德权. 神经网络事件抽取技术综述[J]. 智能计算机与应用, 2018, 8(3):1-5,10.
[
|
| [9] |
|
| [10] |
|
| [11] |
肖明, 曾莉. 信息抽取技术及其发展[J]. 西南民族大学学报(自然科学版), 2021, 47(6):633-639.
[
|
| [12] |
代建华, 彭若瑶, 许路, 等. 基于深度神经网络的信息抽取研究综述[J]. 西南师范大学学报(自然科学版), 2022, 47(4):1-11.
[
|
| [13] |
苏韶生, 杨勇, 程敏婷, 等. 基于规则库的电子病历信息抽取研究[J]. 中国数字医学, 2014(7):12-13,51.
[
|
| [14] |
乔磊, 李存华, 仲兆满, 等. 基于规则的人物信息抽取算法的研究[J]. 南京师大学报(自然科学版), 2012, 35(4):134-139.
[
|
| [15] |
张萌, 陈佳惠, 孙然然, 等. 基于规则的城市轨道交通安全事件信息抽取及其知识元表示[J]. 科学技术与工程, 2021, 21(15):6435-6440.
[
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
王志飞, 谢雁鸣, 王永炎. 正则表达式在上市中药文献信息提取中的应用[J]. 中国中药杂志, 2011, 36(20): 2888-2890.
[
|
| [23] |
朱丽萍, 刘蔷, 苏斐, 等. 科技文献的实验语料句抽取方法[J]. 计算机工程与设计, 2016, 37(11):3086-3091.
[
|
| [24] |
陶玥, 余丽, 张润杰. 科技文献中短语级主题抽取的主动学习方法研究[J]. 数据分析与知识发现, 2020, 4(10):134-143.
[
|
| [25] |
吴骋, 徐蕾, 秦婴逸, 等. 中文电子病历多层次信息抽取方法的探索[J]. 中国数字医学, 2020, 15(6):29-31.
[
|
| [26] |
牛承志, 骆鑫, 赵丹. 临床科研数据抽取研究[J]. 医学信息学杂志, 2020, 41(7):25-28.
[
|
| [27] |
霍娜, 吕国英. 基于规则匹配的灾难性追踪事件信息抽取的研究[J]. 电脑开发与应用, 2012, 25(6):7-9,13.
[
|
| [28] |
丁晟春, 王莉, 刘梦露. 基于规则的动物卫生事件舆情信息抽取研究[J]. 计算机应用与软件, 2018, 35(9):56-62.
[
|
| [29] |
熊志斌, 朱剑锋, 尹成国. 正则表达式在旅游突发事件信息抽取中的应用[J]. 软件, 2015, 36(11):15-17,22.
[
|
| [30] |
|
| [31] |
王志飞, 李晓君, 郭霞珍, 等. 正则表达式在中医文献研究中的应用初探[J]. 中国中医药信息杂志, 2010, 17(3):98-99.
[
|
| [32] |
庞正其. 科技论文中标点符号应用常见问题分析和探讨[J]. 今传媒, 2022, 30(6):72-74.
[
|
| [33] |
唐永广. 4论文中标点符号的几点用法[J]. 西华师范大学学报(哲学社会科学版), 1988(4):373-374.
[
|
| [34] |
段连平. 科技文献中标点符号的特殊用法[J]. 科技与出版, 2009(11):31-32.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}