
Journal of Geo-information Science >
AED-Net: Semantic Segmentation Model for Landslide Recognition from Remote Sensing Images
Received date: 2023-04-03
Revised date: 2023-06-01
Online published: 2023-09-22
Supported by
National Natural Science Foundation of China(42171453)
National Key Research and Development Program of China(2022YFB3904200)
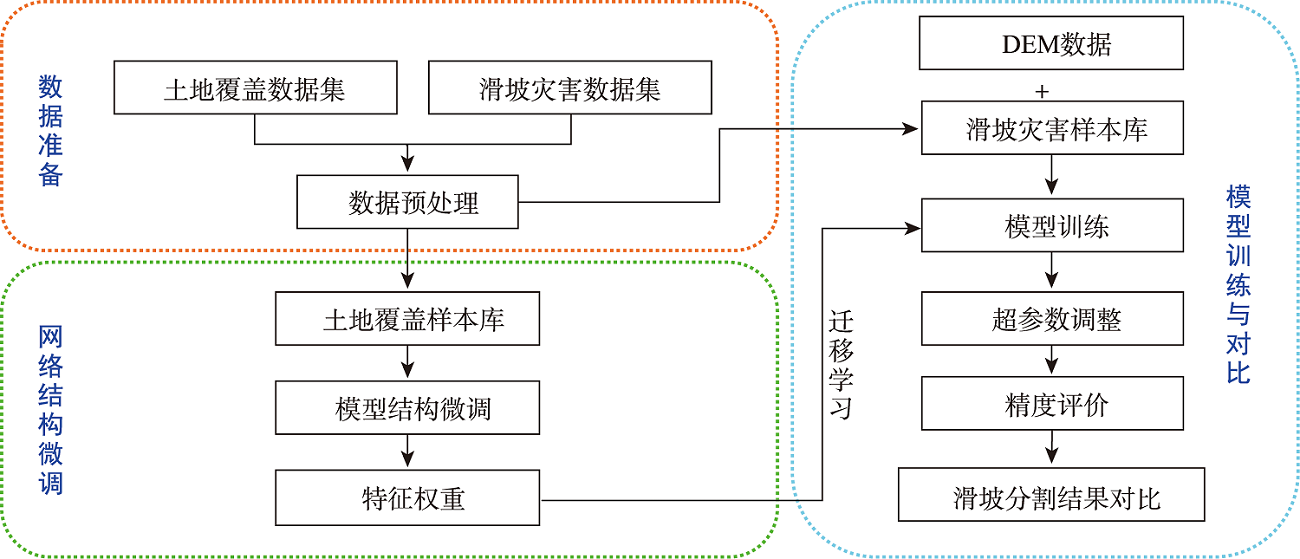
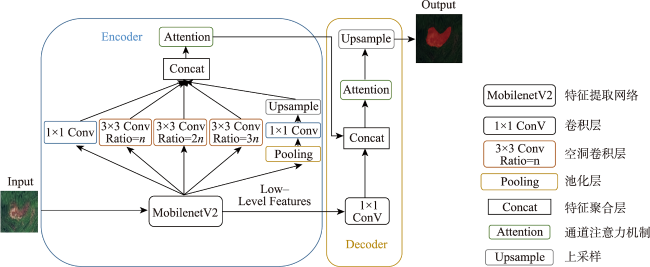
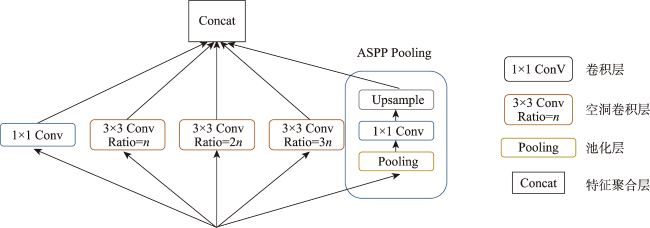
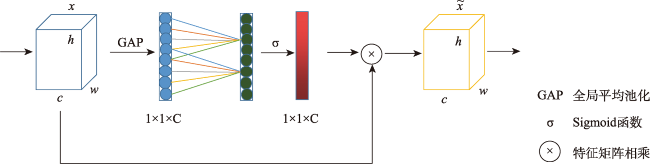
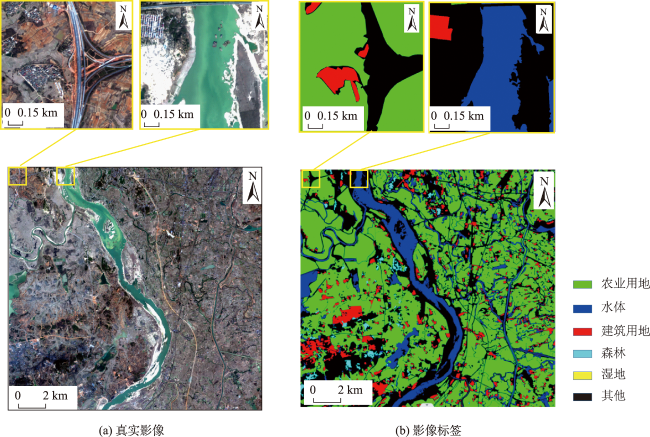
Remote sensing images contain rich semantic information and play an important role in landslide disaster monitoring. Traditional landslide recognition is mainly based on remote sensing visual interpretation and human-computer interaction recognition, which is time and labor consuming, with strong subjectivity and low extraction accuracy. Semantic segmentation, as an important task in deep learning, has played an important role in automatic recognition tasks using remote sensing images due to its end-to-end, pixel-level classification capability and has great potential in automatic recognition of landslides. The existing semantic segmentation models for landslides using remote sensing images usually lack the feature information of multi-scale ground objects, and the boundary will be blurred with the increase of network depth. In this paper, Attention combined with Encoder-Decoder Network (AED-Net) is proposed for landslide recognition. A shallow feature extraction network is used to alleviate the boundary ambiguity caused by deep neural network. Multi-scale feature extraction capability of convolution pool pyramid structure in void space is utilized. Combined with the feature restoring ability of the encoder-decoder structure, the boundary information is restored, and the channel attention mechanism is used to enhance the key feature learning ability of the model. The focal-loss function is used to alleviate the imbalance of positive and negative samples. In our study, firstly, the GID-5 data set is used to conduct comparative tests on the expansion rate setting of void convolutions and the selection of channel attention mechanism in the model to get the optimal solution. Then, the feature weight is transferred to the semantic segmentation task for landslide disaster by using transfer learning method, and the hyperparameter discussion and ablation experiment are carried out. The resulting model achieves the optimal segmentation performance on the landslide disaster data set of Bijie City, with a Pixel Accuracy (PA) of 95.58%, the Mean Pixel Accuracy (MPA) of 89.24%, and the Mean Intersection over Union (MIoU) of 82.68%. Compared with classical semantic segmentation networks such as PSP-Net, Attention U-Net, DeeplabV3+ with ECA attention mechanism, and semantic segmentation models such as PA-Fov and LandsNet for classfifying landslide disasters, the pixel accuracy of our model increases by 0.73%~1.97%. The average pixel accuracy of all categories increases by 1.0%~2.84%, and the average interaction ratio increases by 2.25%~5.11%. Moreover, the edge information of landslide image is smoother and the multi-scale landslide segmentation accuracy is better than other deep learning models, which demonstrates the effectiveness of the proposed model in semantic segmentation of landslides from remote sensing images.
JIANG Weijie , ZAHNG Chunju , XU Bing , LUO Chenchen , ZHOU Han , ZHOU Kang . AED-Net: Semantic Segmentation Model for Landslide Recognition from Remote Sensing Images[J]. Journal of Geo-information Science, 2023 , 25(10) : 2012 -2025 . DOI: 10.12082/dqxxkx.2023.230171
表1 GID-5数据集中不同膨胀率下模型性能对比Tab. 1 Model performance comparison under different expansion rates in the GID-5 dataset (%) |
| 膨胀率 | PA | MPA | MIOU |
|---|---|---|---|
| 2 | 85.67 | 82.24 | 70.91 |
| 4 | 83.16 | 78.23 | 66.56 |
| 6 | 84.09 | 80.13 | 70.19 |
| 8 | 84.81 | 81.37 | 69.06 |
注:表中加粗数值表示最优模型结果。 |
表2 不同注意力机制影响下GID-5数据集分割精度Tab. 2 The segmentation accuracy of GID-5 data sets which affected by different attention mechanisms (%) |
| 模型 | PA | MPA | IoU | ||||
|---|---|---|---|---|---|---|---|
| 建筑用地 | 农业用地 | 森林 | 湿地 | 水体 | |||
| Without-Attention | 85.64 | 79.44 | 77.16 | 72.35 | 59.73 | 57.20 | 84.53 |
| With-CBAM | 85.06 | 82.21 | 75.55 | 71.0 | 56.61 | 63.79 | 84.37 |
| With-SE | 85.78 | 81.82 | 77.29 | 71.95 | 58.86 | 63.25 | 83.21 |
| With-ECA | 87.41 | 85.24 | 77.53 | 72.88 | 60.25 | 64.11 | 86.86 |
注:表中加粗数值表示最高精度。 |
表3 迁移学习对滑坡分割结果的影响Tab. 3 The influence of transfer learning on the results of landslide segmentation |
| 模型 | F-Score |
|---|---|
| 不使用迁移学习 | 0.842 |
| 迁移学习 | 0.886 |
表4 不同Batch Size下模型分割滑坡的性能Tab. 4 Performance of model segmentation landslide under different batch sizes (%) |
| Batch Size | PA | MPA | MIoU |
|---|---|---|---|
| 2 | 94.44 | 81.43 | 79.84 |
| 4 | 94.45 | 84.4 | 80.75 |
| 8 | 95.47 | 88.57 | 81.56 |
| 16 | 95.58 | 89.24 | 82.68 |
表5 不同学习率下分割滑坡的性能Tab. 5 Performance of segmentation landslide under different learning rates (%) |
| 学习率 | PA | MPA | MIoU |
|---|---|---|---|
| 1e-2 | 91.72 | 78.59 | 69.90 |
| 1e-3 | 95.11 | 89.68 | 81.55 |
| 1e-4 | 95.48 | 89.04 | 82.34 |
| 5e-5 | 95.17 | 89.42 | 81.63 |
| 1e-5 | 95.48 | 89.8 | 82.68 |
表6 消融实验结果Tab. 6 Results of ablation experiment |
| Focal-loss | Encoder-ECA | Decoder-ECA | MIoU/% | |
|---|---|---|---|---|
| 1 | × | × | × | 80.56 |
| 2 | √ | × | × | 81.28 |
| 3 | √ | × | √ | 81.88 |
| 4 | √ | √ | × | 82.04 |
| 5 | √ | √ | √ | 82.68 |
表7 不同模型的滑坡分割性能比较Tab. 7 Comparison of landslide segmentation performance of different models (%) |
| [1] |
许嘉慧, 孙德亮, 张虹. 多尺度滑坡灾害生态风险评价与风险管理研究──以三峡库区万州-巫山段为例[J/OL]. 生态学报, 2023(11):1-10.
[
|
| [2] |
许强, 董秀军, 李为乐. 基于天-空-地一体化的重大地质灾害隐患早期识别与监测预警[J]. 武汉大学学报·信息科学版, 2019, 44(7):957-966.
[
|
| [3] |
|
| [4] |
|
| [5] |
梅伟, 顾世祥, 刘鑫, 等. 基于滑坡大变形过程的滑坡定量风险评估方法[J]. 武汉大学学报·工学版, 2022, 55(5):443-453.
[
|
| [6] |
|
| [7] |
|
| [8] |
胡芳驰, 樊雅婧. 遥感影像滑坡灾害识别应用研究[J]. 农业灾害研究, 2021, 11(4):98-99.
[
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}