
Journal of Geo-information Science >
A Method for Analyzing Residents' Travel Characteristics Based on OD Flow Semantics and Spatio-temporal Semantic Clustering
Received date: 2023-02-25
Revised date: 2023-04-24
Online published: 2023-11-02
Supported by
Strategic Priority Research Program of the Chinese Academic of Science(XDA23100502)
Construction of University Discipline Alliance of Digital Economy of Fujian Province(闽教高〔2022〕15号)
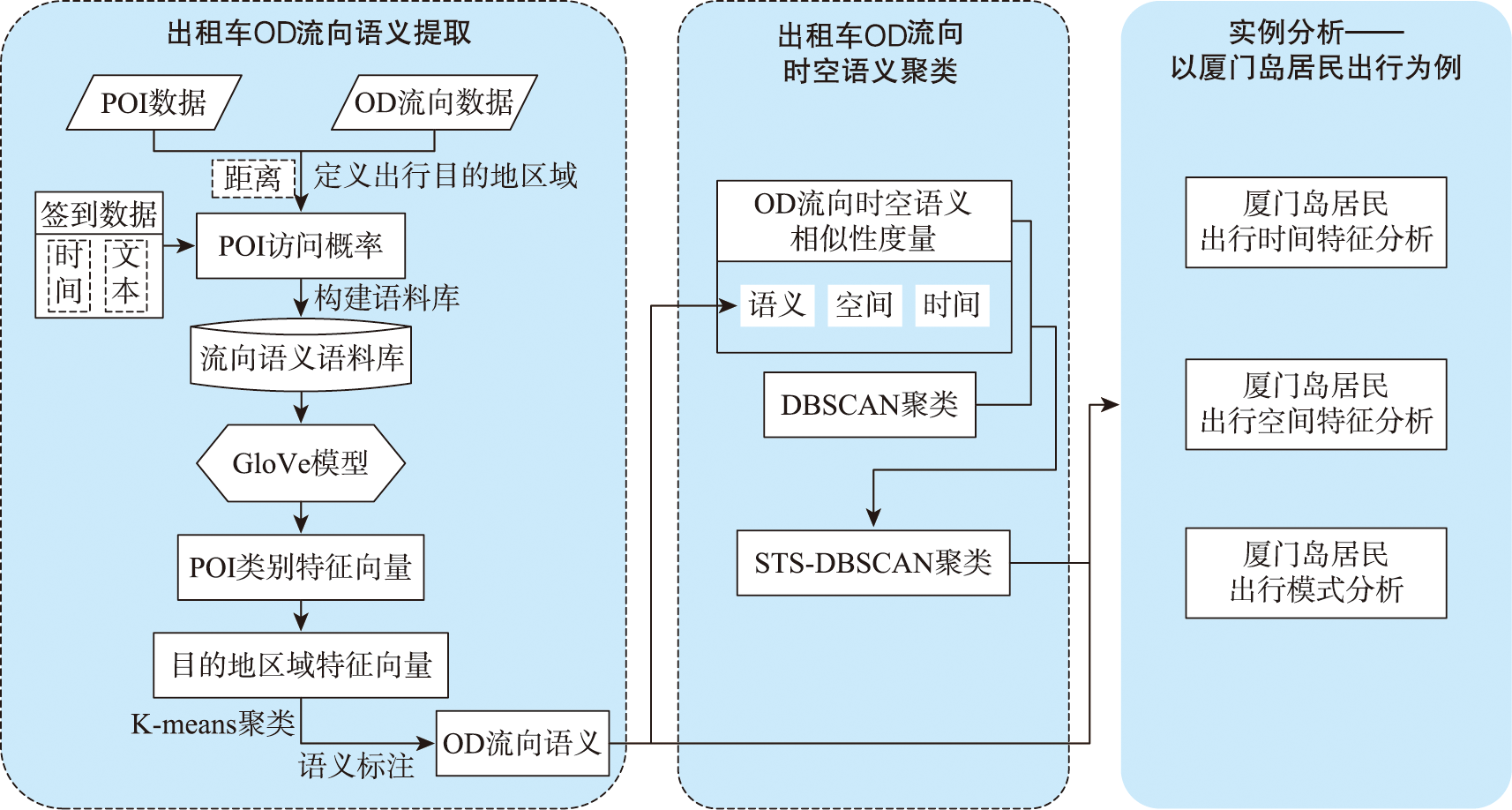
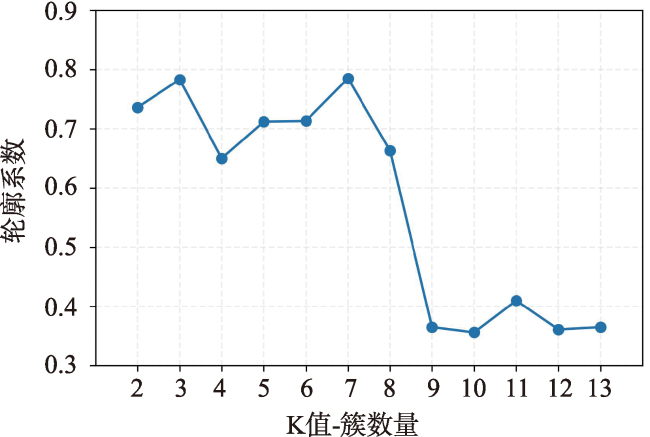
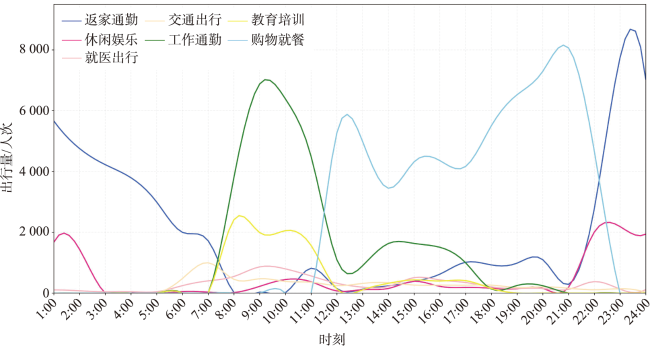
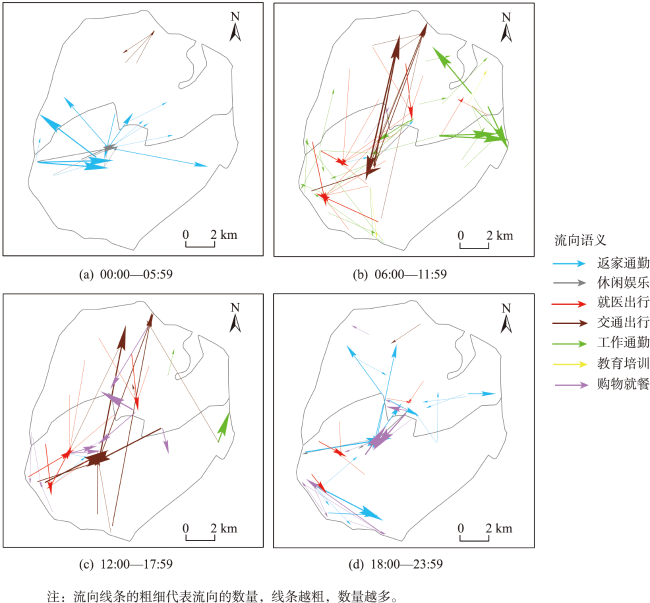
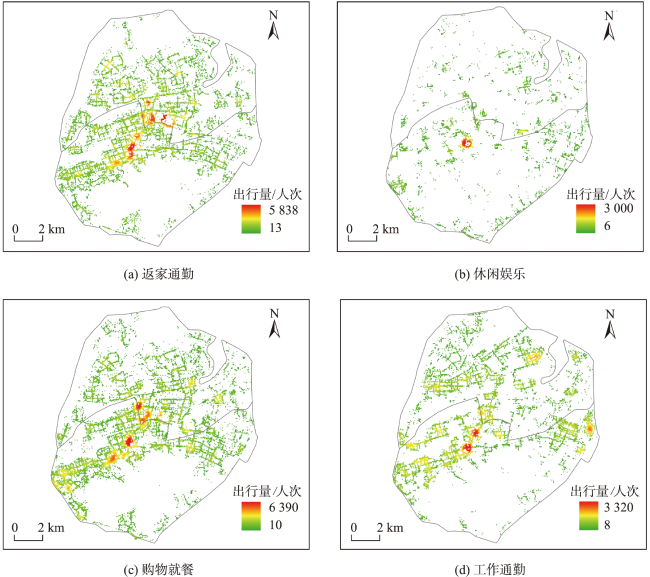
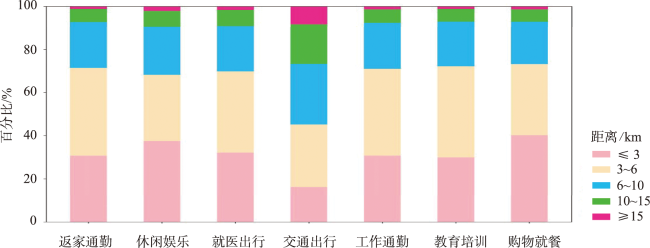
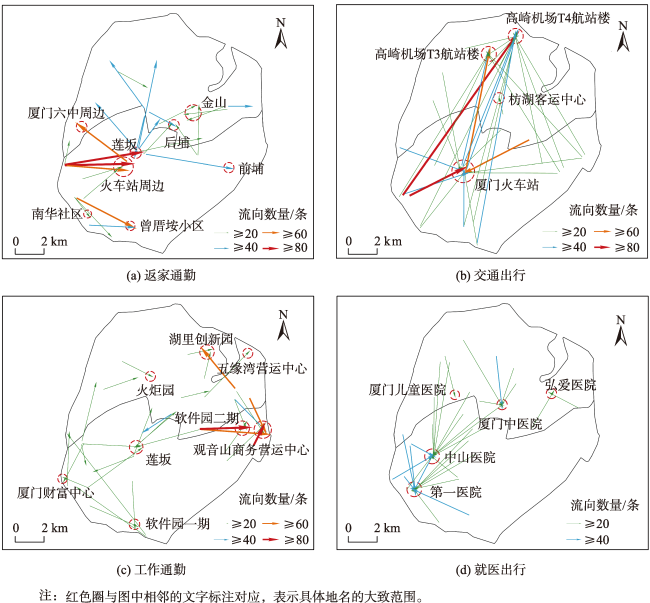
While rapid urbanization endows people with a modern life, it also brings many urban diseases such as traffic congestion and uneven distribution of resources. Taxi is one of the main transportation methods for urban residents. Taxi data effectively record the spatial and temporal information of residents' travel and can be widely used for residents' travel characteristics mining. Analyzing residents' travel characteristics is an important way to solve and alleviate the increasingly prominent urban problems. At present, rich research results have been achieved in mining residents' travel characteristics using taxi OD flow data. Cluster analysis, which is based on taxi OD flow data, represents one of the primary methods for uncovering the travel characteristics of residents. But most of the studies ignore the semantic information of OD flow. Urban POI data is an important data support for semantic extraction of OD flow, and semantic information can be extracted by studying the relationship between OD flow and POI. To address the problem of insufficient consideration of semantic information in spatiotemporal clustering algorithms, a method for extracting semantics of OD flow based on Global Vectors (GloVe) model and density based spatiotemporal semantic clustering algorithm (STS DBSC AN, Spatial Temporal Semantic DBSCAN) is proposed in this paper. Firstly, OD flow semantics are extracted by combining POI visiting probability and GloVe model, the GloVe model not only fully considers the local geographic context information of POIs, but also takes into account its global statistical information in the corpus. Based on this, a spatiotemporal semantic similarity measurement rule for OD flow is proposed, which comprehensively considers temporal, spatial, and semantic information. Then, the DBSCAN clustering algorithm is improved according to the spatiotemporal semantic similarity measurement rule, and the spatiotemporal semantic clustering of OD flow data is realized. Finally, analysis of travel characteristics of residents in Xiamen island based on OD flow semantics and spatiotemporal semantic clustering, and a total of seven types of residents' travel semantics are extracted. Results show that: 1) Residents' travel semantics are influenced by the time factor, and the main residents’ travel semantics are different in different time periods; 2) residents' travel hotspots are mainly distributed in the central developed area of Xiamen Island; 3) seven typical residents' travel patterns are extracted from four main residents' travel semantics through spatiotemporal semantic clustering analysis. The results demonstrate that OD flow semantic and the spatiotemporal semantic clustering method can effectively mine the travel characteristics of urban residents.
KE Weiwen , WU Sheng , KE Rihong . A Method for Analyzing Residents' Travel Characteristics Based on OD Flow Semantics and Spatio-temporal Semantic Clustering[J]. Journal of Geo-information Science, 2023 , 25(11) : 2150 -2163 . DOI: 10.12082/dqxxkx.2023.230089
| 算法1 基于密度的OD流向时空语义聚类 |
|---|
| 输入:OD流向数据F={ },时间阈值 ,距离参数 ,密度阈值minpts,邻域半径Eps |
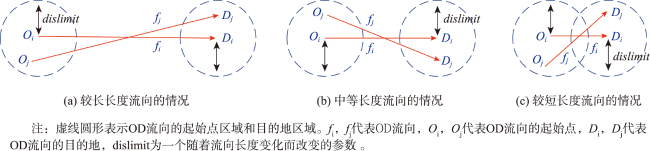
| 输出:时空语义相似的OD流向类簇C={ },噪声集合N={ }function STS_DBSCAN(F, , , minpts)//计算每一条流的长度dis ,参数dislimit,确定Eps-邻域并标记为unvisitedCalculate dis , dislimitif dislimit < Eps doEps=dislimitend if//寻找每条unvisited流的Eps-区域中满足所有合并条件的类簇并合并for in F doif 为unvisited标记 为visitedCalculate //计算Eps-邻域中流之间的相似性参数 if 且Eps-邻域中至少minpts个对象满足条件{ } , { } Celse { } { } N//标记 为噪声end ifend ifend for输出C,NUntil 所有的流标记为visitedend function |
表1 各聚类区域的POI密度和富集指数Tab. 1 POI density and enrichment factor in each cluster region |
| POI类别 | F1 | F2 | F3 | F4 | F5 | F6 | F7 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PD | EF | PD | EF | PD | EF | PD | EF | PD | EF | PD | EF | PD | EF | |||||||
| 商务住宅 | 16.20 | 2.30 | 7.20 | 1.32 | 4.60 | 1.16 | 5.78 | 1.53 | 6.86 | 1.03 | 7.87 | 1.39 | 8.56 | 1.41 | ||||||
| 购物服务 | 25.60 | 1.82 | 28.50 | 1.52 | 19.40 | 1.37 | 13.50 | 1.27 | 14.30 | 1.30 | 11.60 | 1.12 | 45.80 | 1.95 | ||||||
| 餐饮服务 | 24.80 | 1.73 | 29.30 | 1.58 | 25.60 | 1.50 | 23.20 | 1.57 | 17.50 | 1.34 | 15.20 | 1.24 | 43.90 | 1.89 | ||||||
| 公司企业 | 6.65 | 1.26 | 5.86 | 0.79 | 3.78 | 1.26 | 4.56 | 1.35 | 20.30 | 2.31 | 5.79 | 1.41 | 4.86 | 1.28 | ||||||
| 交通设施 | 0.76 | 1.13 | 0.71 | 1.03 | 0.82 | 1.20 | 1.28 | 2.03 | 0.97 | 1.57 | 0.70 | 1.11 | 0.68 | 1.05 | ||||||
| 医疗保健 | 3.08 | 1.33 | 1.85 | 0.73 | 6.65 | 1.88 | 1.10 | 0.77 | 1.23 | 0.95 | 1.04 | 0.85 | 0.96 | 0.71 | ||||||
| 休闲娱乐 | 5.03 | 1.42 | 17.20 | 1.83 | 2.62 | 1.02 | 3.87 | 1.18 | 2.08 | 0.98 | 3.23 | 1.12 | 10.10 | 1.56 | ||||||
| 科教文化 | 2.56 | 0.99 | 2.56 | 1.26 | 2.09 | 1.19 | 1.96 | 0.89 | 3.26 | 1.25 | 5.32 | 1.78 | 1.88 | 1.14 | ||||||
表2 3种不同方法提取的OD流向语义分布与微博签到数据Tab. 2 Semantics distribution of OD flow extracted by three different methods and weibo check-in data (%) |
| 返家通勤 | 休闲娱乐 | 就医出行 | 交通出行 | 工作通勤 | 教育培训 | 购物就餐 | |
|---|---|---|---|---|---|---|---|
| 微博签到数据 | 31.37 | 8.99 | 4.28 | 2.23 | 22.23 | 2.09 | 28.81 |
| 方法1 | 32.35 | 7.10 | 3.58 | 2.16 | 24.23 | 1.50 | 29.08 |
| 方法2 | 25.38 | 9.23 | 2.98 | 1.51 | 28.06 | 1.16 | 31.68 |
| 方法3 | 20.36 | 11.51 | 2.12 | 0.92 | 25.50 | 1.01 | 38.58 |
| [1] |
方志祥. 人群动态的观测理论及其未来发展思考[J]. 地球信息科学学报, 2021, 23(9):1527-1536.
|
| [2] |
郑晓琳, 刘启亮, 刘文凯, 等. 智能卡和出租车轨迹数据中蕴含城市人群活动模式的差异性分析[J]. 地球信息科学学报, 2020, 22(6):1268-1281.
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
李佳蓉, 夏昊, 张迎, 等. 城市居民出行O/D时空分布特征的轨迹数据提取[J]. 测绘科学, 2020, 45(2):150-158.
|
| [7] |
|
| [8] |
|
| [9] |
张晗, 邬群勇. 基于LDA和优化蚁群的OD流向时空语义聚类算法[J]. 地球信息科学学报, 2022, 24(5):837-850.
|
| [10] |
|
| [11] |
|
| [12] |
彭卉, 杜云艳, 易嘉伟, 等. 基于手机数据的北京市城市与近郊交互模式挖掘[J]. 地球信息科学学报, 2019, 21(1):97-106.
|
| [13] |
|
| [14] |
|
| [15] |
郭茂祖, 陈加栋, 张彬, 等. 融合空间偏好和语义的个体活动识别方法[J]. 国防科技大学学报, 2022, 44(3):57-66.
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
/
| 〈 |
|
〉 |
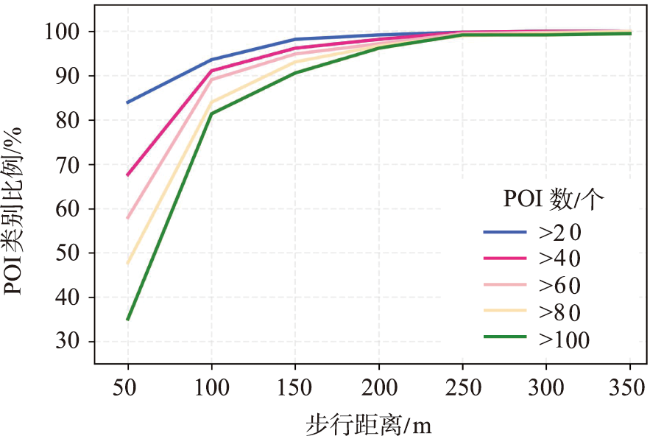
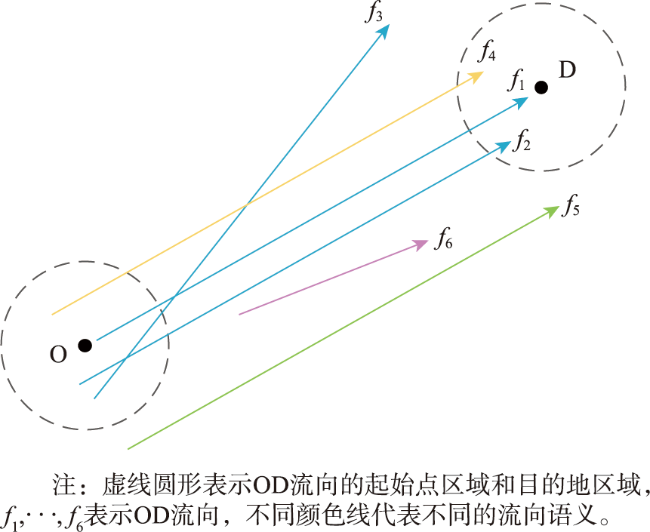
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}