
Journal of Geo-information Science >
Automated Sheep Detection from UAV Images for the Application of Sheep Roundup
Received date: 2023-04-18
Revised date: 2023-07-28
Online published: 2023-11-02
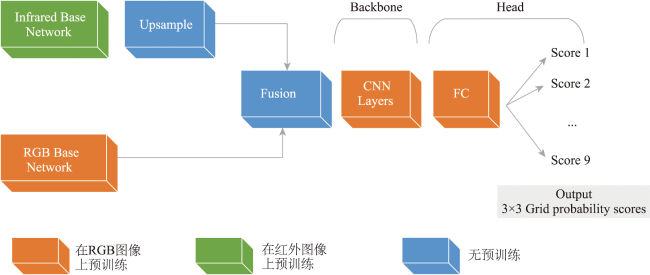
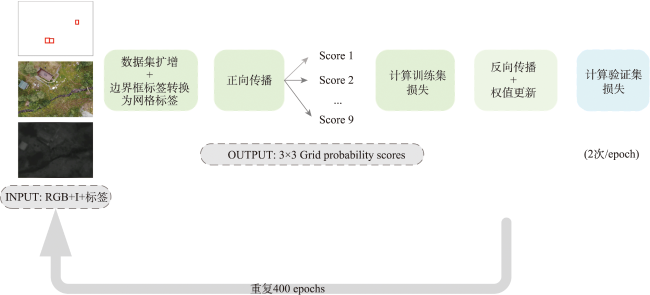
Each year, approximately 2.1 million sheep are released to graze freely in vast, forest-covered, and mountainous areas throughout Norway. At the end of the grazing season, farmers must find and round up their sheep. This can be a time consuming and challenging process because of the large area and cluttered nature of the sheep grazing environment. Existing technologies that help farmers find their sheep, such as bells, radio bells, electronic ear tags and UAVs, are limited by the cost, signal coverage, and low degree of automation, which cannot efficiently and automatically locate sheep in the wild. This study proposes an automatic sheep detection algorithm using UAV images. A model architecture using the ResNet and ResNeXt as the backbone networks is designed to address the automatic sheep detection task from UAV RGB and infrared images. Our study evaluates how well this model meets performance and processing speed requirements of a real-world application. We also compare models using fused RGB and infrared data to models using either RGB or infrared as input, and further explore the model complexity and generalization ability. Results show that fusion of RGB and infrared data yields better average precision results than using single RGB or infrared dataset in the model. The set of optimal solutions achieve average precision scores in the range of 69.6% to 96.3% with inference times ranging from 0.1 to 0.6 seconds per image. The most accurate network achieves a grid precision of 97.9% and a recall of 90.1%, at a confidence threshold of 0.5. This corresponds to the detection of 97.5% of the sheep in the validation dataset. These satisfactory results demonstrate the great potential of the proposed automatic sheep detection method using multi-channel UAV images for improving sheep roundup.

Key words: sheep roundup; object detection; deep learning; ResNet; ResNeXt; infrared images; RGB images; fusion
CHENG Jun , DING Linfang , FAN Hongchao . Automated Sheep Detection from UAV Images for the Application of Sheep Roundup[J]. Journal of Geo-information Science, 2023 , 25(11) : 2281 -2292 . DOI: 10.12082/dqxxkx.2023.230202
表1 模型训练配置参数Tab. 1 Model training configuration parameters |
| 输入类型 | 学习率 | 批大小 | 训练总轮数/次 |
|---|---|---|---|
| Infrared | 0.000 10 | 32 | 400 |
| RGB | 0.000 07 | 8 | 400 |
| RGB+I | 0.000 05 | 8 | 400 |
表2 各数据集图像数量Tab. 2 The number of images in each dataset after sampling (张) |
| 数据集 | 合计 | 生长环境 | 羊的品种 | ||||
|---|---|---|---|---|---|---|---|
| 散养 | 圈养 | 1 | 2 | 3 | |||
| 训练集 | 229 | 123 | 106 | √ | √ | ||
| 验证集 | 64 | 59 | 5 | √ | √ | ||
| 测试集T1:Klæbu | 106 | 0 | 106 | √ | |||
| 测试集T2:Orkanger | 116 | 0 | 116 | √ | |||
| 合计 | 515 | 182 | 333 | √ | √ | √ | |
表3 各数据集中按照羊的颜色和生长阶段分组的羊的数量Tab. 3 The number of sheep in each dataset after sampling grouped by sheep color and sheep life stage (只) |
| 数据集 | 合计 | 羊的颜色 | 生长阶段 | |||||
|---|---|---|---|---|---|---|---|---|
| 白色 | 灰色 | 黑色 | 棕色 | 羊羔 | 成年羊 | |||
| 训练集 | 277 5 | 155 5 | 878 | 257 | 85 | 0 | 277 5 | |
| 验证集 | 435 | 237 | 175 | 18 | 5 | 0 | 435 | |
| 测试集T1:Klæbu | 147 4 | 142 2 | 2 | 28 | 22 | 409 | 106 5 | |
| 测试集T2:Orkanger | 123 6 | 196 | 167 | 627 | 246 | 608 | 628 | |
| 合计 | 592 0 | 341 0 | 122 2 | 930 | 358 | 101 7 | 490 3 | |
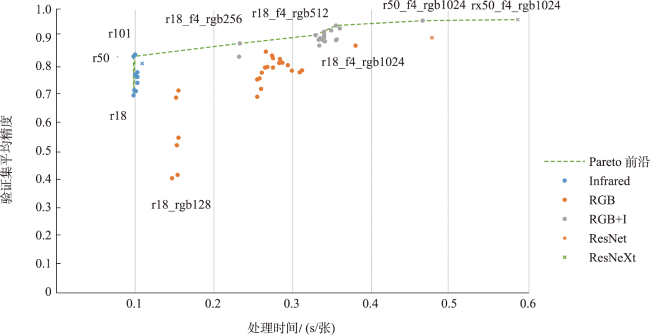
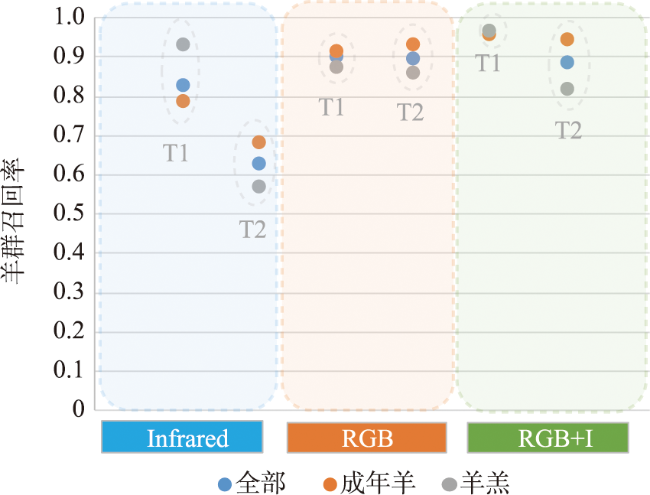
表4 pareto前沿模型的平均精度、准确率、召回率和处理时间结果Tab.4 Average precision, precision, recall and inference time results for models on the pareto front. The best values are highlighted in bold. |
| 模型 | 融合深度 | RGB尺寸 | 平均精度 | 处理时间/s | 格网 | 羊群召回率 | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| 训练集 | 验证集 | 测试集T1 | 测试集T2 | 准确率 | 召回率 | |||||
| I_r18 | - | - | 0.808 | 0.696 | 0.682 | 0.487 | 0.096 | 0.759 | 0.505 | 0.721 |
| I_r50 | - | - | 0.893 | 0.833 | 0.585 | 0.385 | 0.098 | 0.846 | 0.726 | 0.871 |
| I_r101 | - | - | 0.882 | 0.840 | 0.620 | 0.339 | 0.100 | 0.844 | 0.689 | 0.856 |
| RGB+I_r18 | 4 | 256 | 0.983 | 0.879 | 0.912 | 0.652 | 0.233 | 0.834 | 0.807 | 0.925 |
| RGB+I_r18 | 4 | 512 | 0.985 | 0.908 | 0.924 | 0.708 | 0.329 | 0.839 | 0.835 | 0.948 |
| RGB+I_r18 | 4 | 1 024 | 0.991 | 0.942 | 0.939 | 0.804 | 0.355 | 0.901 | 0.858 | 0.960 |
| RGB+I_r50 | 4 | 1 024 | 0.990 | 0.959 | 0.940 | 0.810 | 0.465 | 0.959 | 0.873 | 0.968 |
| RGB+I_rx50 | 4 | 1 024 | 0.993 | 0.963 | 0.945 | 0.823 | 0.586 | 0.979 | 0.901 | 0.975 |
注:加粗字体表示最优解。 |
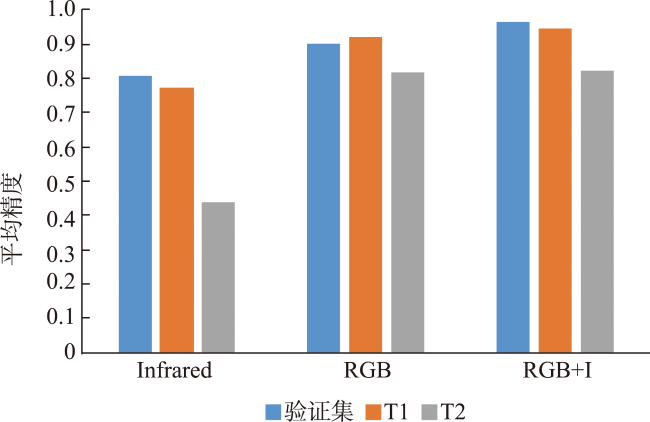
表5 按模型backbone和输入类型分组的模型测试结果Tab. 5 Result of models grouped by model backbone and input type |
| 模型Backbone | 输入 | 平均精度 | 处理时间/s | |||
|---|---|---|---|---|---|---|
| 训练集 | 验证集 | 测试集T1 | 测试集T2 | |||
| ResNet18 | Infrared | 0.880 | 0.741 | 0.705 | 0.435 | 0.100 |
| RGB | 0.925 | 0.817 | 0.843 | 0.708 | 0.285 | |
| RGB+I | 0.991 | 0.942 | 0.939 | 0.804 | 0.355 | |
| ResNet50 | Infrared | 0.893 | 0.833 | 0.585 | 0.365 | 0.098 |
| RGB | 0.936 | 0.871 | 0.852 | 0.801 | 0.380 | |
| RGB+I | 0.990 | 0.959 | 0.940 | 0.810 | 0.465 | |
| ResNeXt50 | Infrared | 0.909 | 0.808 | 0.770 | 0.440 | 0.109 |
| RGB | 0.970 | 0.899 | 0.918 | 0.818 | 0.477 | |
| RGB+I | 0.993 | 0.963 | 0.945 | 0.823 | 0.586 | |
| [1] |
Norske Leksikon S. Sauehold i norge[EB/OL]. 2019, https://snl.no/sau.
|
| [2] |
Smartbjella. Smartbjella[EB/OL]. 2019, https://smartbjella.no/
|
| [3] |
findmy. findmy[EB/OL]. 2019, https://www.findmy.no/
|
| [4] |
Telespor. Elektronisk overvÅking av husdyr[EB/OL]. 2019, https://telespor.no/.
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
范红超, 李万志, 章超权. 基于Anchor-free的交通标志检测[J]. 地球信息科学学报, 2020, 22(1):88-99.
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
祝宁华, 郑江滨, 张阳. 无人机航拍野生动物智能检测与统计方法综述[J]. 航空工程进展, 2023, 14(1):13-26.
|
| [20] |
赵建敏, 李雪冬, 李宝山. 基于无人机图像的羊群密集计数算法研究[J]. 激光与光电子学进展, 2021, 58(22):220-229.
[
|
| [21] |
|
| [22] |
|
| [23] |
李柯泉, 陈燕, 刘佳晨, 等. 基于深度学习的目标检测算法综述[J]. 计算机工程, 2022, 48(7):1-12.
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
梁华, 宋玉龙, 钱锋, 等. 基于深度学习的航空对地小目标检测[J]. 液晶与显示, 2018, 33(9):793-800.
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
龙怡灿, 雷蓉, 董杨, 等. 基于YOLOv5算法的飞机类型光学遥感识别[J]. 地球信息科学学报, 2022, 24(3):572-582.
[
|
| [35] |
PyTorch. From research to production[EB/OL]. 2019, https://pytorch.org/
|
| [36] |
DroneZon. Top mavic 2 enterprise review and faqs - thermal, dual spotlight,loudspeaker and beacons mounts[EB/OL]. 2019, https://www.dronezon.com/drone-reviews/mavic-2-enterprise-review-with-spotlights-loudspeaker-beacon-faqs/
|
| [37] |
Labelbox. Labelbox homepage[EB/OL]. 2019, https://labelbox.com/
|
/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}