
Journal of Geo-information Science >
Application of the Decomposition Importance in the Road Network Auto-Selection of Volunteered Geographic Information for Map Generalization
Received date: 2022-08-03
Revised date: 2022-11-16
Online published: 2024-03-26
Supported by
National Natural Science Foundation of China(62101395)
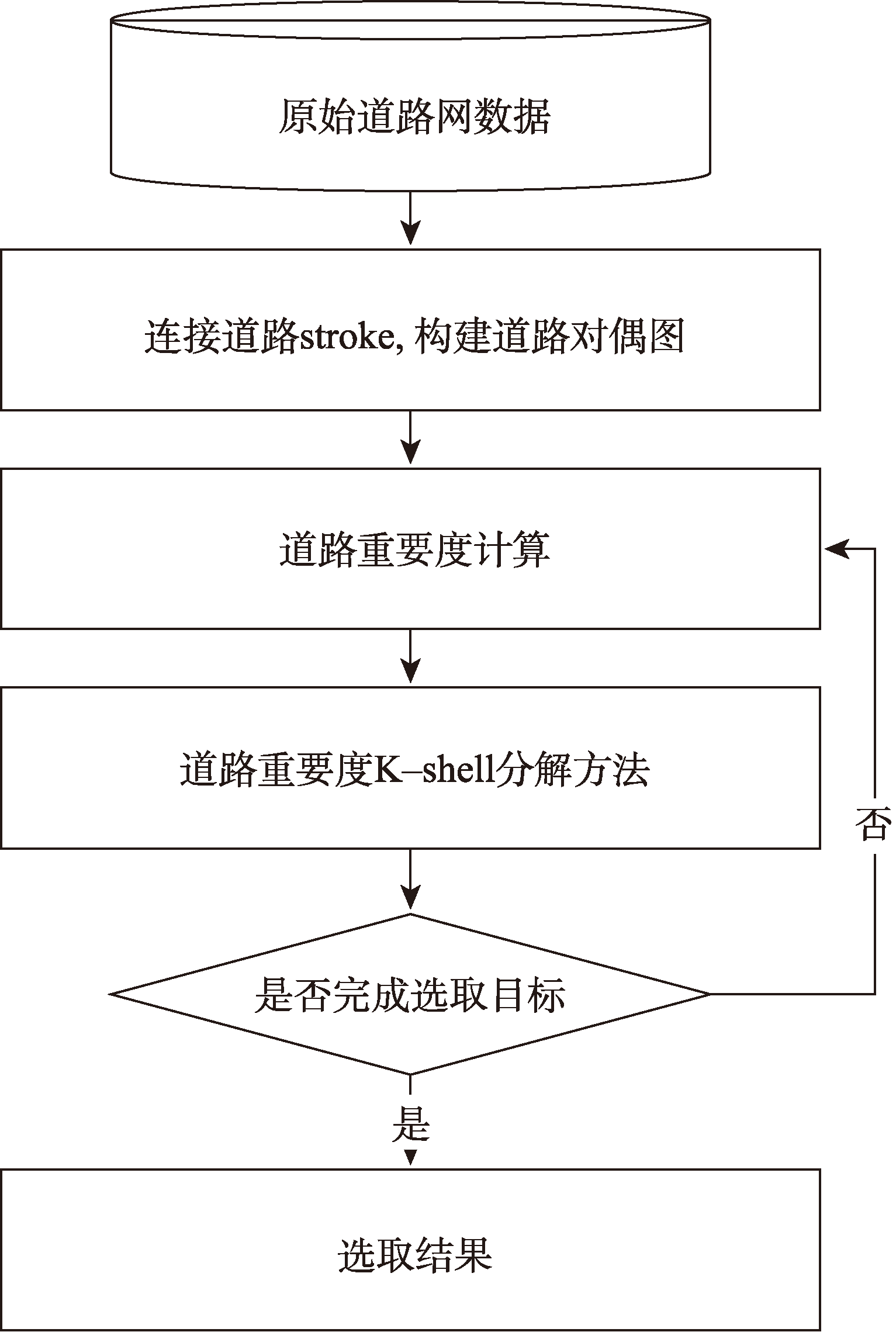
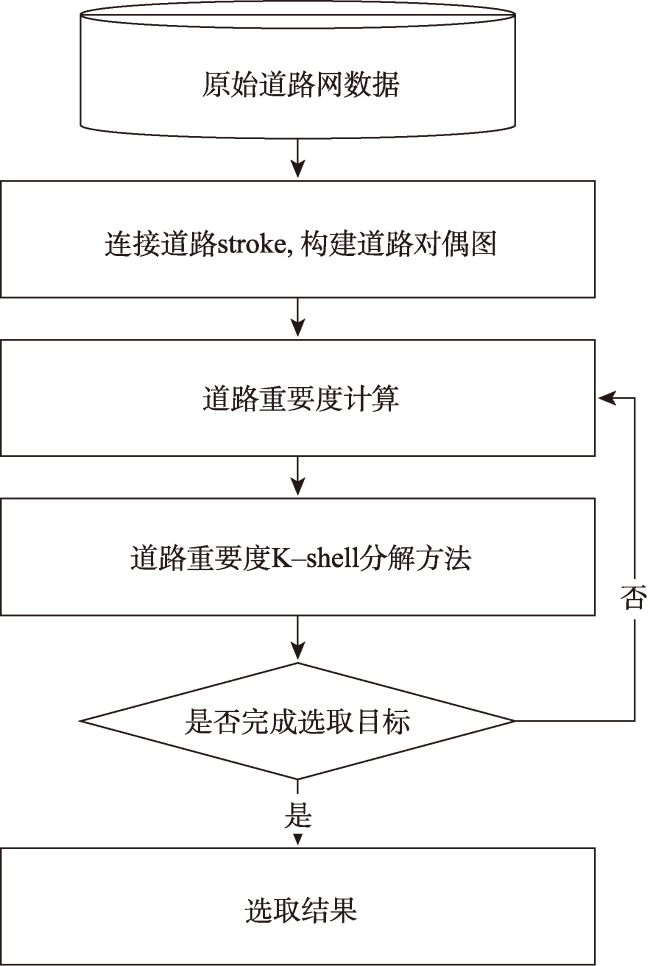
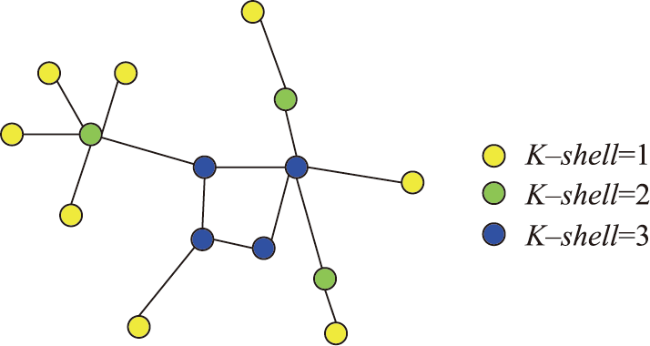
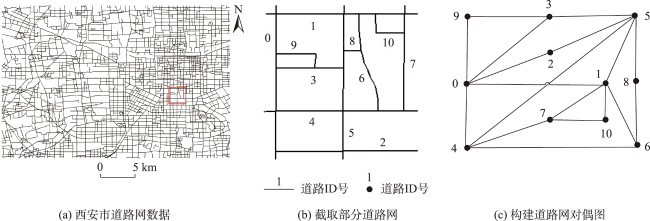
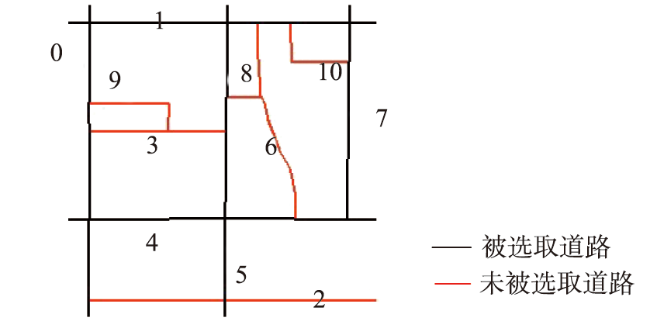
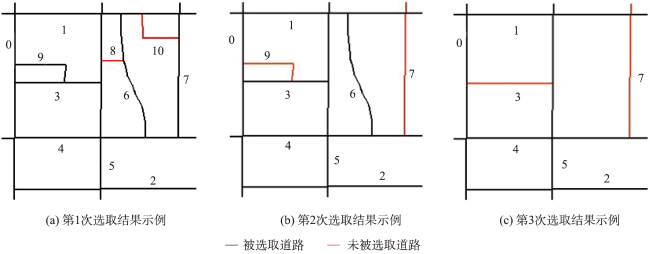
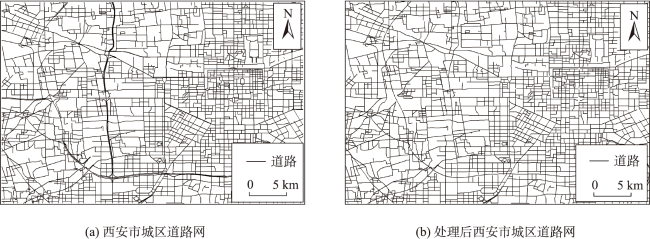
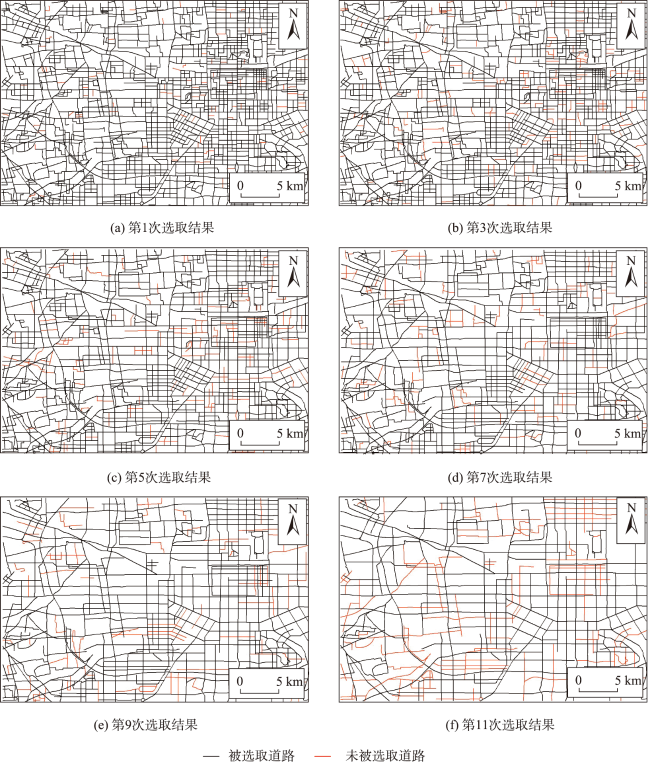
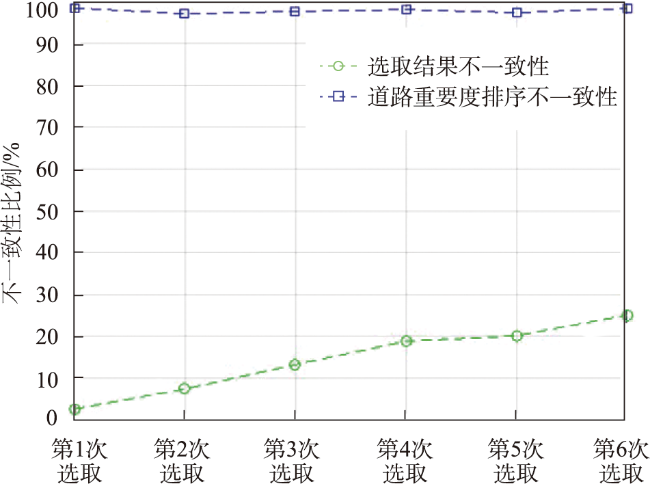
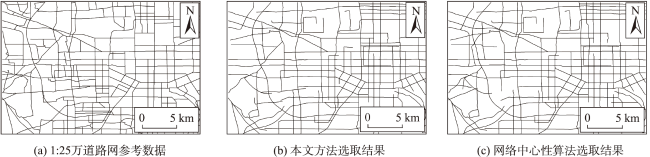
Volunteered geographic information has the characteristics of real time, wide coverage, rich information, and convenient access. It can be used as a good data input for the production and updating of worldwide geospatial data. However, due to the scale-free characteristics of this data, the details of volunteered geographic information road data are usually too complex, which is far beyond the needs for spatial vector data production and is thus difficult to be directly applied to geospatial data production. When calculating the road importance, the existing road network automatic selection algorithm sorts the importance of all roads to be selected and selects them from the largest to the smallest according to the importance. These methods usually ignore the influence of road network structure changes which could affect the road importance in the selection process. Therefore, this paper proposes an automatic selection algorithm of road network based on hierarchical decomposition of importance. Aiming at the characteristics of rich details and free scale of volunteered geographic information road network, this paper proposes a road network selection algorithm based on hierarchical decomposition. Compared with the previous algorithms based on the ranking and selection of road importance, the essence of this algorithm is that it considers the impact of the ranking of road importance caused by the changes in road network structure after deleting some roads in the process of gradual downsizing. It adopts the strategy of gradual decomposition and multiple calculations to reduce this impact by repeatedly calculating the road importance. The selection process of this algorithm is shown as follows. Firstly, we calculate the importance of all nodes and remove some road nodes with the least importance. Secondly, whether the selection results meet the requirements are judged. If the requirements are not met, we will recalculate the importance of all new nodes and repeat the judgement steps until all road nodes are sorted, so as to obtain the importance ranking of all roads and complete the selection of road network. The experimental results show that the algorithm selected in this paper is better than the network centric method, which means that the decomposition selection strategy is more consistent with the reference data. In addition, the algorithm in this paper is beneficial to the infinite selection of road network. However, this algorithm needs to manually set the selection step size, and the step size setting has a certain impact on the selection results. In the next step of research, more extensive and in-depth experiments are needed to explore more reasonable step size settings and further study the quantitative evaluation mechanism of road selection results.
XIONG Shun , DU Qingyun , MA Chao , LIU Pingzhi , JIANG Danni . Application of the Decomposition Importance in the Road Network Auto-Selection of Volunteered Geographic Information for Map Generalization[J]. Journal of Geo-information Science, 2024 , 26(1) : 135 -143 . DOI: 10.12082/dqxxkx.2024.220569
表1 第一次分解道路节点的重要度及其变化Tab. 1 The result of first road select and the changes of road importance |
| 首次道路节点重要度 | 第一次分解后重新计算道路节点重要度 | 排序变化 | ||||
|---|---|---|---|---|---|---|
| 重要度排序 | 重要度 | 道路ID | 重要度排序 | 重要度 | 道路ID | |
| 1 | 1.561 9 | 0 | 1 | 1.489 2 | 0 | 不变 |
| 2 | 1.500 4 | 5 | 2 | 1.348 8 | 4 | 上升 |
| 3 | 1.488 1 | 1 | 3 | 1.240 8 | 5 | 下降 |
| 4 | 1.438 9 | 4 | 4 | 1.197 6 | 1 | 下降 |
| 5 | 0.787 0 | 7 | 5 | 0.765 6 | 2 | 上升 |
| 6 | 0.725 5 | 2 | 6 | 0.708 4 | 3 | 上升 |
| 7 | 0.700 9 | 6 | 7 | 0.657 6 | 7 | 不变 |
| 8 | 0.577 9 | 3 | 8 | 0.638 8 | 6 | 下降 |
| 9 | 0.430 3 | 9 | 9 | 0.528 0 | 9 | 不变 |
| 10 | 0.418 0 | 10 | ||||
| 11 | 0.331 9 | 8 | ||||
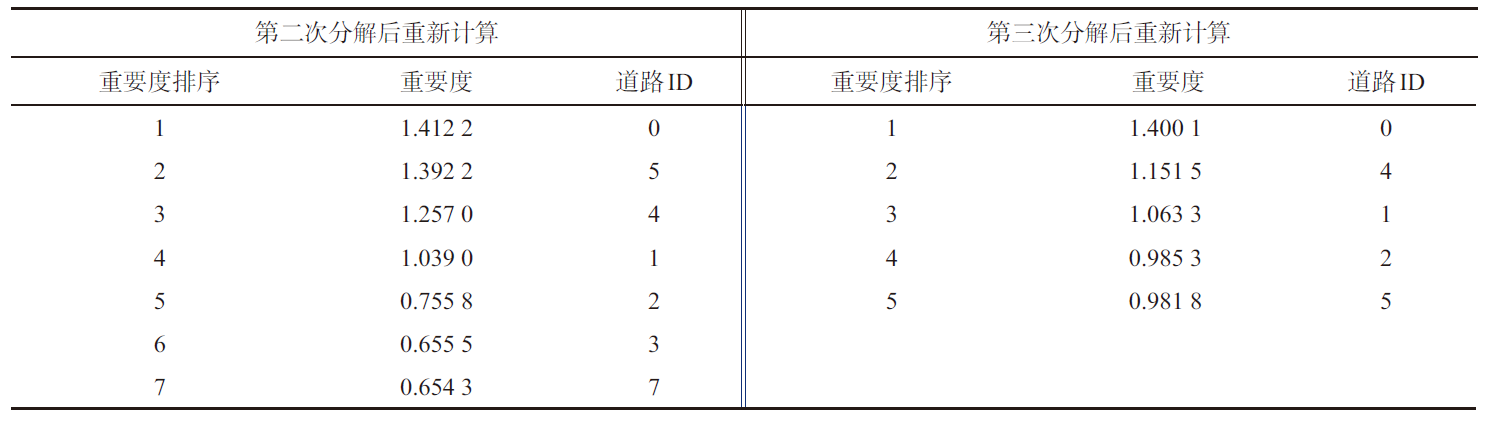
表2 第二次分解及第三次分解道路节点的重要度及其变化Table 2 The results of senond and third road select and the changes of road importance |
 |
| [1] |
马超, 孙群, 徐青, 等. 自发地理信息可信度及其评价[J]. 地球信息科学学报, 2016, 18(10):1305-1311.
[
|
| [2] |
寇培颖, 牛铮, 刘正佳, 等. 基于自发地理信息的“一带一路”区域陆路交通状况分析[J]. 地球信息科学学报, 2018, 20(8):1074-1082.
[
|
| [3] |
|
| [4] |
|
| [5] |
郭漩, 钱海忠, 王骁, 等. 多源道路智能选取的本体知识推理方法[J]. 测绘学报, 2022, 51(2):279-289.
[
|
| [6] |
马京振, 孙群, 温伯威, 等. 结合轨迹数据的混合多特征道路网选取方法[J]. 武汉大学学报·信息科学版, 2022, 47(7):1009-1016.
[
|
| [7] |
邓敏, 陈雪莹, 唐建波, 等. 一种顾及道路交通流量语义信息的路网选取方法[J]. 武汉大学学报·信息科学版, 2020, 45(9):1438-1447.
[
|
| [8] |
刘佩, 袁林辉, 张康, 等. 基于RBF神经网络的OSM道路网智能选取[J]. 地理信息世界, 2019, 26(3):8-13.
[
|
| [9] |
袁林辉, 刘凯, 刘佩, 等. 径向基函数神经网络用于小比例尺道路网选取[J]. 测绘科学, 2019, 44(3):8-14,20.
[
|
| [10] |
马超, 孙群, 陈换新, 等. 加权网页排序算法在道路网自动选取中的应用[J]. 武汉大学学报·信息科学版, 2018, 43(8):1159-1165.
[
|
| [11] |
|
| [12] |
|
| [13] |
李木梓, 徐柱, 李志林, 等. 基于层次随机图的道路选取方法[J]. 地球信息科学学报, 2012, 14(6):719-727.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}