
Journal of Geo-information Science >
Home Location Prediction Method for Social Network Users Integrating Text Topic and Social Relationship
Received date: 2023-09-07
Revised date: 2023-12-05
Online published: 2024-03-27
Supported by
National Natural Science Foundation of China(U19A2058)
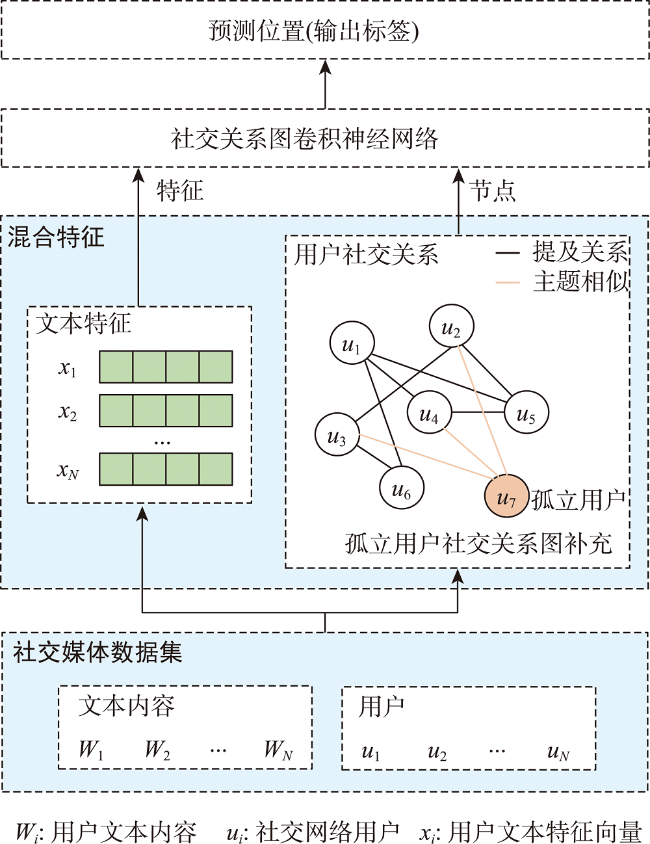
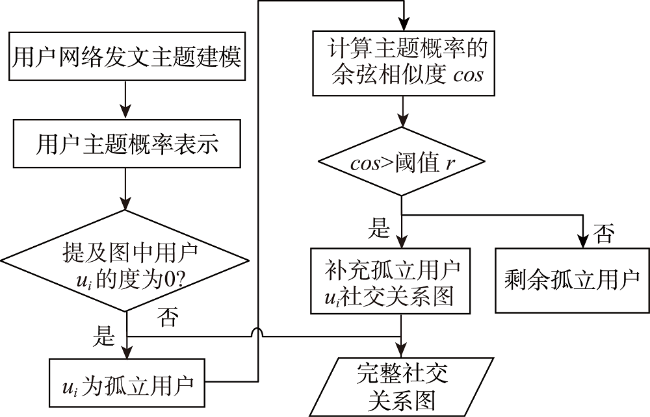
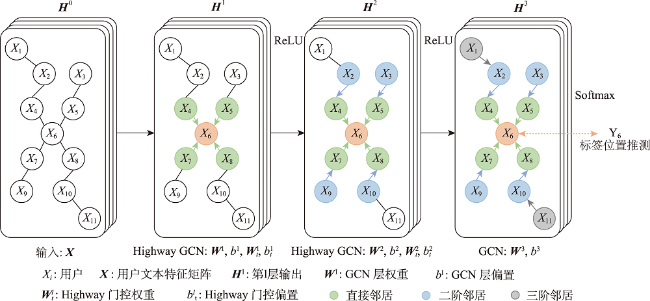
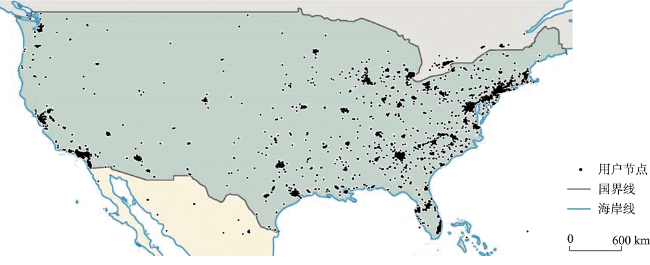
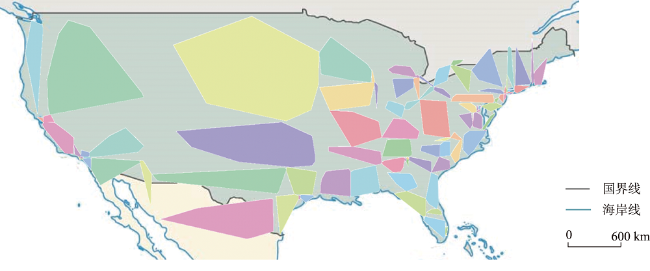
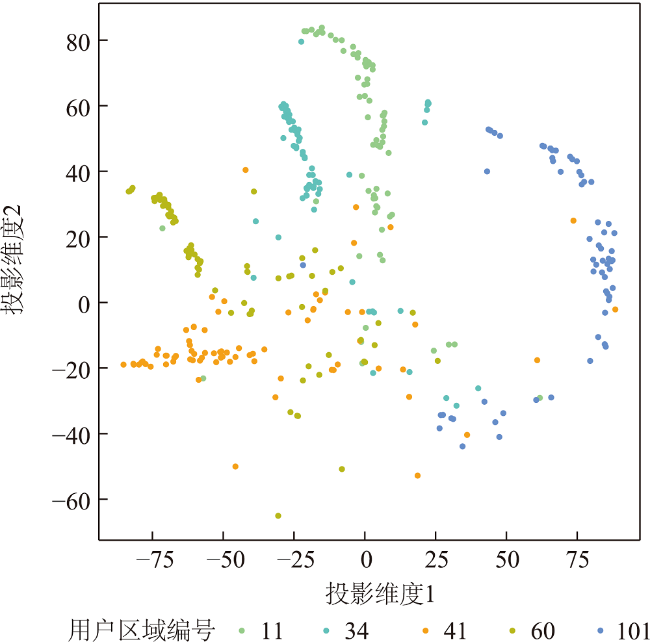
Prediction of users' geolocation plays an important role in location-based applications such as natural disaster monitoring, flu trend prediction, and targeted advertising promotion. Integrating multi-source information, mining user behavior characteristics, and analyzing user social attributes can help improve prediction accuracy and reduce distance error. Existing methods primarily rely on textual content and social networks for location prediction without considering the fusion of these two types of information, and have difficulty in predicting the locations of isolated users in social networks. Therefore, this paper proposes a home location prediction method for social network users integrating text topic and social relationship graph neural network. In the method, first, hybrid features are extracted from text content, using TF-IDF to obtain text feature vectors, and an initial social relationship graph is established based on the mentioned information between users. Then, to address the issue of isolated users in the user social relationship graph and difficulty in estimating their locations, a topic model is established to establish connections for isolated users based on topic vector similarity and supplement the social relationship graph. Finally, based on graph convolutional neural network, social relationship graph data are processed, and text features and network structure are jointly modeled to effectively predict users' geolocation. The effect of topic similarity threshold on prediction performance and graph size is explored on a real-world benchmark dataset GeoText. The experimental results show that our method is able to aggregate most of the user nodes belonging to the same class and increase the proportion of locatable users. The network constructed using multiple types of relationships can maintain the diversity of user relationships and can achieve better prediction accuracy of graph neural network. SRGCN outperforms the existing methods in terms of the average distance error, the median distance error, and the prediction accuracy, which indicates that the multi-view feature learning model is superior for geolocation prediction compared to models based on a single source of information. On the GeoText dataset, the Acc@161 of SRGCN is 1% higher than that of GCN method, and the average error distance is reduced by 16km, which indicates that the SRGCN method is more competitive than the existing best-performing method. Our experimental results demonstrate the effectiveness of SRGCN, which can improve the accuracy of home location prediction of users.
GAO Jiayuan , XIONG Wei , CHEN Luo , OUYANG Xue , YANG Kaijun . Home Location Prediction Method for Social Network Users Integrating Text Topic and Social Relationship[J]. Journal of Geo-information Science, 2024 , 26(2) : 488 -498 . DOI: 10.12082/dqxxkx.2024.230536
表1 数据集介绍Tab. 1 Introduction to the dataset |
| 数据集 | 推文数/条 | 训练集用户数/个 | 验证集用户数/个 | 测试集用户数/个 | 边数量/条 | 孤立用户数/个 |
|---|---|---|---|---|---|---|
| GeoText | 377 504 | 5 685 | 1 895 | 1 895 | 77 155 | 424 |
表2 孤立用户补充关系图对推测性能和图规模的影响Tab. 2 Effect of isolated users relationship graph on prediction performance and graph size |
| 主题相似度阈值 | 平均距离 误差/km | 位置推测 准确度/% | 边/条 |
|---|---|---|---|
| 0.60 | 533 | 60.11 | 94 745 |
| 0.65 | 545 | 59.53 | 92 157 |
| 0.70 | 540 | 60.21 | 90 374 |
| 0.75 | 542 | 59.79 | 88 522 |
| 0.80 | 545 | 59.79 | 85 899 |
| 0.85 | 557 | 59.89 | 84 782 |
| 0.90 | 530 | 60.58 | 81 256 |
| 0.95 | 525 | 60.05 | 79 084 |
表3 地理位置推测算法的性能比较Tab. 3 Performance comparison of geographic location prediction algorithms |
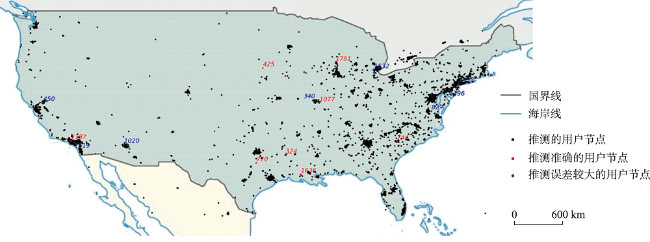
图6 位置推测效果存在差异的用户地理分布情况注:不同颜色的充填表示不同国家,红色数字表示推测准确的用户编号,蓝色数字表示推测误差较大的用户编号。该图基于自然资源部标准地图服务网站下载的审图号为GS(2016)1663号的标准地图制作,底图无修改。 Fig. 6 Geographical distribution of users with differences in geolocation prediction performance |
表4 位置推测效果存在差异的用户基本信息Tab. 4 Basic information of users with differences in geolocation prediction performance |
| 用户标识 | 编号 | 真实位置(经度,纬度)/(°,°) | 发文数/条 | 社交关系数/条 | 距离误差/km |
|---|---|---|---|---|---|
| USER_542aa1fb | 1493 | (-74.010, 40.707) | 63 | 22 | 0.00 |
| USER_7b70c03a | 1632 | (-83.690, 42.255) | 38 | 33 | 0.49 |
| USER_af6729de | 340 | (-90.335, 38.779) | 22 | 5 | 2.07 |
| USER_49d4be2e | 1619 | (-117.890, 33.917) | 72 | 35 | 4.46 |
| USER_f4f9f786 | 1196 | (-75.072, 39.940) | 31 | 14 | 7.85 |
| USER_1e0d7389 | 450 | (-121.457, 38.487) | 23 | 21 | 13.39 |
| USER_5a99377b | 829 | (-77.107, 37.507) | 58 | 41 | 40.17 |
| USER_ccabb575 | 1020 | (-112.239, 33.624) | 21 | 35 | 80.84 |
| USER_ecd38bdd | 1077 | (-89.906, 38.425) | 38 | 16 | 251.16 |
| USER_16073bdf | 744 | (-81.036, 34.009) | 36 | 13 | 361.24 |
| USER_74fb72f0 | 1187 | (-118.277, 34.095) | 58 | 5 | 801.79 |
| USER_05ed473f | 324 | (-93.758, 32.421) | 26 | 13 | 997.28 |
| USER_a868f330 | 1636 | (-92.035, 30.208) | 31 | 22 | 1 170.69 |
| USER_25fcdff0 | 1781 | (-88.055, 43.098) | 22 | 0 | 1 919.77 |
| USER_1a6770ba | 770 | (-97.098, 31.526) | 47 | 39 | 2 188.55 |
| USER_665890a8 | 425 | (-96.355, 42.4775) | 29 | 0 | 3 697.02 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
刘乐源, 代雨柔, 曹亚男, 等. 在线社交网络中用户地理位置预测综述[J/OL]. 计算机研究与发展, 2023:1-29 [2023-11-24.]
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
乔亚琼, 罗向阳, 马江涛, 等. 基于多种提及关系的社交媒体用户位置推断[J]. 通信学报, 2020, 41(12):72-81.
[
|
| [28] |
|
| [29] |
|
| [30] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}