
Journal of Geo-information Science >
Classification of Textured 3D Mesh Models Based on Multiview 2D Mapping
Received date: 2023-09-02
Revised date: 2023-10-20
Online published: 2024-03-31
Supported by
National Natural Science Foundation of China(41871227)
Shenzhen Science and Technology Program(JCYJ20220818101617037)
Shenzhen Science and Technology Program(JCYJ20230808105201004)
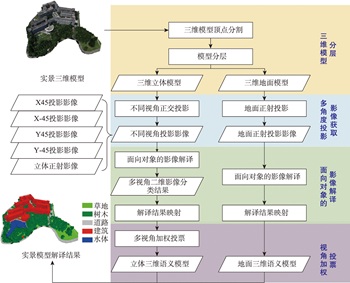
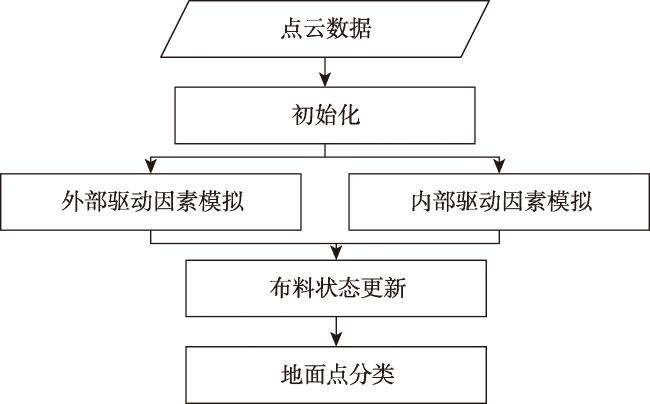
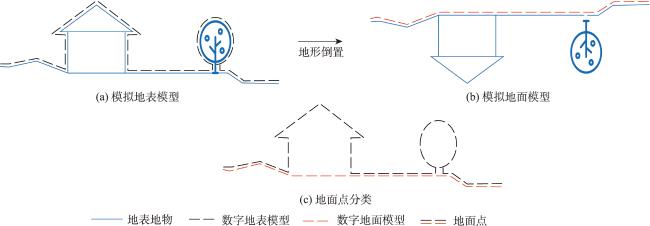
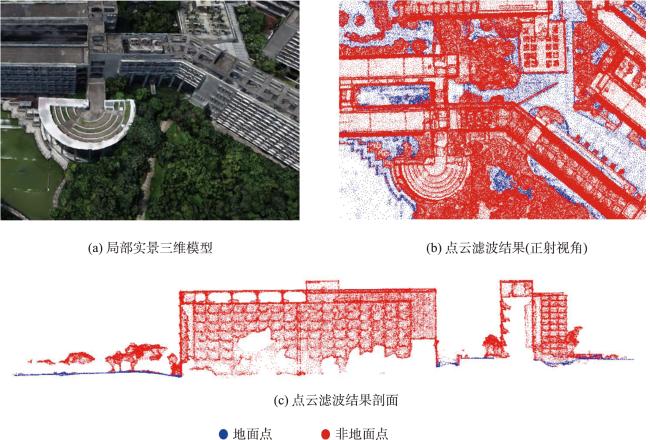
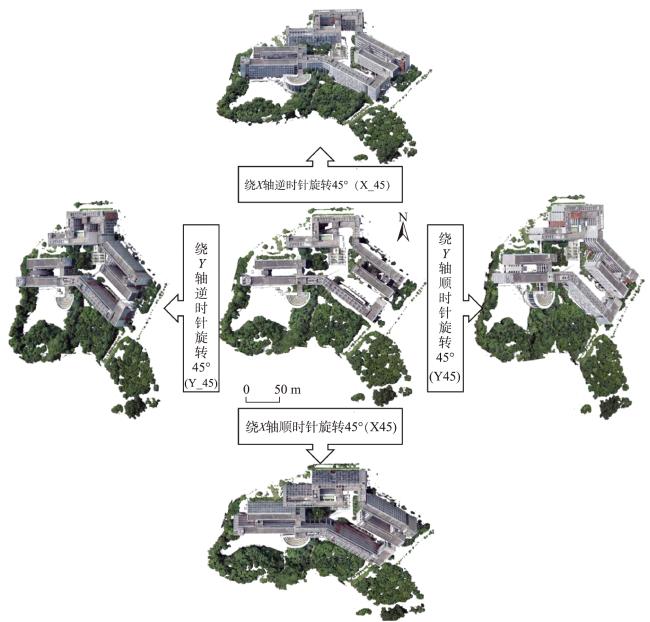
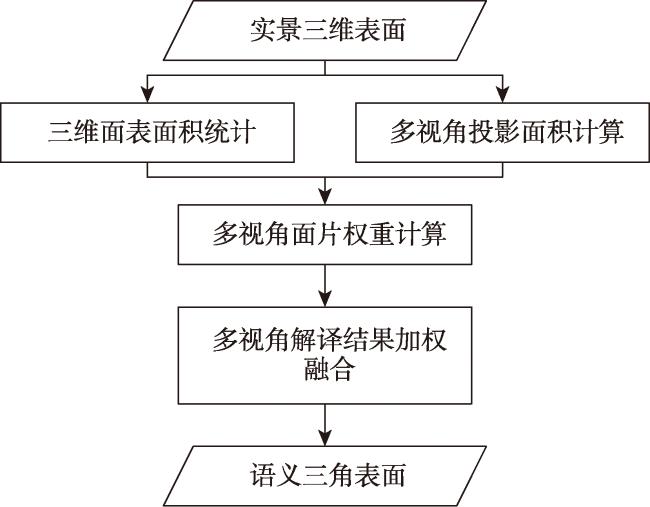
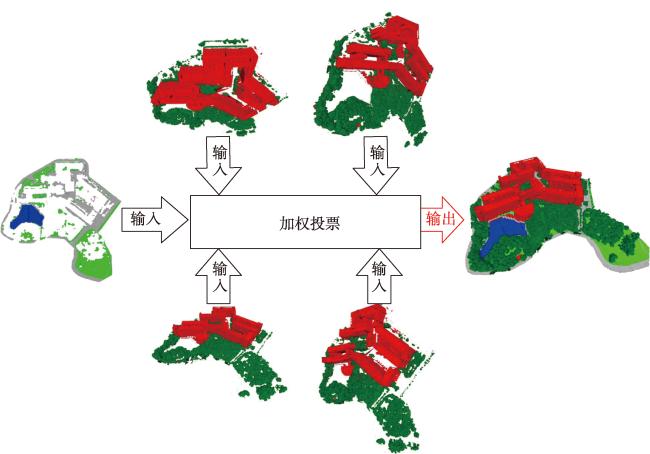
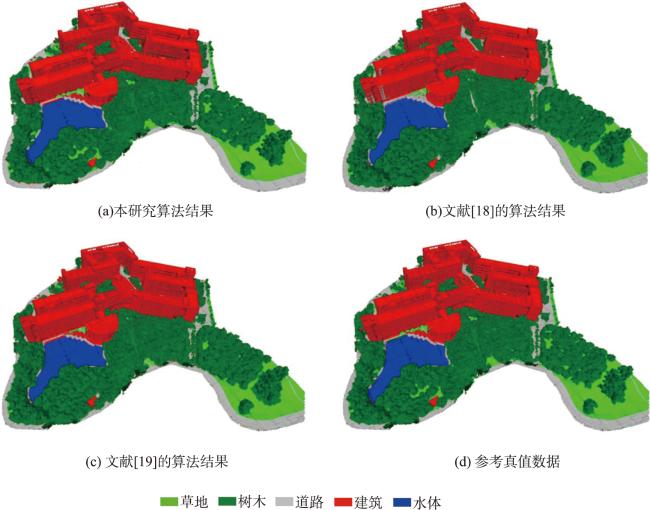
Textured 3D mesh models are digital virtual spaces that provide a true, three-dimensional representation of human production, living, and ecological spaces. They have been widely used as foundational data input in areas such as smart cities and visual exhibitions. The semantic interpretation of textured 3D models is the foundation for fully exploring the potential of these models to achieve automatic understanding and analysis of scenes. Existing interpretation methods suffer from issues such as incomplete interpretation of occluded objects and inaccurate interpretation of different object boundaries. To address these challenges, in this study, we propose a multiview-based classification method for textured 3D mesh models. A textured 3D mesh model is first segmented into ground surfaces and 3D objects by Cloth Simulation Filtering (CSF) method. The ground surface is projected to a 2D orthophoto and classified using object-based image analysis methods. The textured 3D objects are transformed into five 2D images through orthographic and multiview oblique projections. These 2D images are then classified using object-based image analysis methods. Furthermore, these 2D semantic maps are inverse-projected to the 3D mesh model, and a multiview voting strategy is proposed for fusing sematic information from different views to obtain the sematic 3D objects. Finally, the semantic terrain surface and 3D objects are merged together to obtain the semantic 3D mesh model. A textured 3D mesh model of Shenzhen University is used to verify the effectiveness of the proposed method. Besides, the proposed method is compared with two state-of-the-art methods. The results show that the proposed method effectively addresses the problems in interpreting occluded objects and distinguishing edges between different objects. It outperforms the competing methods, particularly in the areas of orthographic occlusion and where different ground objects are connected or adhered, and achieves the highest classification accuracy (overall accuracy is 96.69%, Kappa coefficient is 0.942). Future research endeavors could consider the introduction of hyper-facet as the basic unit for classification and multiview fusion. Besides, we used only five fixed views in this study, and adaptive multiview estimation strategy could be further investigated to enhance the accuracy and robustness of the method. This method makes full use of the multiview information of the textured 3D mesh models, which holds significant theoretical and practical values. It not only contributes valuable insights but also offers methodological support for advancing the development and utilization of textured 3D models, especially in the field of natural resources management using textured 3D mesh models.
QU Fenglei , HU Zhongwen , ZHANG Yinghui , ZHANG Jinhua , WU Guofeng . Classification of Textured 3D Mesh Models Based on Multiview 2D Mapping[J]. Journal of Geo-information Science, 2024 , 26(3) : 654 -665 . DOI: 10.12082/dgxxkx.2024.230520
表1 本文算法混淆矩阵Tab. 1 The confusion matrix of proposed method |
| 类别 | 参照样本(三角面片)/个 | 用户精度/% | 生产者精度/% | ||||
|---|---|---|---|---|---|---|---|
| 树木 | 建筑 | 草地 | 道路 | 水体 | |||
| 树木 | 1 016 152 | 28 429 | 26 | 59 | 0 | 97.27 | 95.75 |
| 建筑 | 36 046 | 1 123 208 | 18 | 113 | 0 | 96.88 | 97.07 |
| 草地 | 5 571 | 1 058 | 65 763 | 37 | 0 | 90.80 | 99.83 |
| 道路 | 3 182 | 4 328 | 66 | 105 467 | 1 | 93.30 | 99.79 |
| 水体 | 291 | 112 | 0 | 17 | 8 539 | 95.31 | 99.99 |
| 总体精度/% | 96.69 | ||||||
| Kappa 系数 | 0.942 | ||||||
| 类别 | 参照样本(三角面片)/个 | 用户精度/% | 生产者精度/% | ||||
|---|---|---|---|---|---|---|---|
| 树木 | 建筑 | 草地 | 道路 | 水体 | |||
| 树木 | 960 377 | 22 426 | 37 008 | 19 451 | 1 378 | 92.29 | 90.50 |
| 建筑 | 55 842 | 1 071 502 | 2 055 | 6 797 | 38 | 94.30 | 92.60 |
| 草地 | 13 542 | 4 598 | 22 045 | 1 964 | 0 | 52.30 | 33.47 |
| 道路 | 30 714 | 58 582 | 4 765 | 77 434 | 707 | 44.97 | 73.26 |
| 水体 | 767 | 27 | 0 | 47 | 6 417 | 88.41 | 75.14 |
| 总体精度/% | 89.13 | ||||||
| Kappa 系数 | 0.811 | ||||||
| 类别 | 参照样本(三角面片)/个 | 用户精度/% | 生产者精度/% | ||||
|---|---|---|---|---|---|---|---|
| 树木 | 建筑 | 草地 | 道路 | 水体 | |||
| 树木 | 949 888 | 3 819 | 684 | 398 | 8 | 99.49 | 89.51 |
| 建筑 | 108 271 | 1 149 114 | 907 | 2 561 | 69 | 91.13 | 99.31 |
| 草地 | 2 659 | 1 706 | 63 594 | 696 | 30 | 92.59 | 96.54 |
| 道路 | 381 | 2 447 | 638 | 101 924 | 81 | 96.64 | 96.43 |
| 水体 | 43 | 49 | 50 | 114 | 8 352 | 97.03 | 97.80 |
| 总体精度/% | 94.76 | ||||||
| Kappa 系数 | 0.908 | ||||||
| [1] |
李德仁, 张洪云, 金文杰. 新基建时代地球空间信息学的使命[J]. 武汉大学学报(信息科学版), 2022, 47(10):1515-1522.
[
|
| [2] |
朱勇, 程海翔. 基于倾斜摄影技术的城市实景三维建模研究[J]. 经纬天地, 2022(6):27-30.
[
|
| [3] |
曲林, 冯洋, 支玲美, 等. 基于无人机倾斜摄影数据的实景三维建模研究[J]. 测绘与空间地理信息, 2015, 38(3):38-39,43.
[
|
| [4] |
杨秀德. 基于语义描述的马尔科夫随机场无人机影像三维重建[J]. 北京测绘, 2018, 32(7):814-818.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
黄印. 基于傅里叶变换的倾斜三维模型建筑物分层提取方法[D]. 武汉: 武汉大学, 2018.
[
|
| [15] |
郭慧婷. 基于拓扑结构的三维模型特征提取方法研究[D]. 太原:中北大学, 2017. [
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
刘志刚, 胡忠文, 黄乐平, 等. 面向对象的实景三维模型分层解译方法研究[J]. 地理信息世界, 2022, 29(1):28-34.
[
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}