
Journal of Geo-information Science >
POI Outliers Detection Based on Local Aggregation Characteristic Scale Determination and Its Interpretability Analysis
Received date: 2024-01-18
Revised date: 2024-04-19
Online published: 2024-06-25
Supported by
Natural Science Foundation of Inner Mongolia Autonomous Region(2021BS04002)
Natural Science Foundation of Inner Mongolia Autonomous Region(2021MS04006)
University Basic Research Business Fee Project of Inner Mongolia Autonomous Region(NCYWT23046)
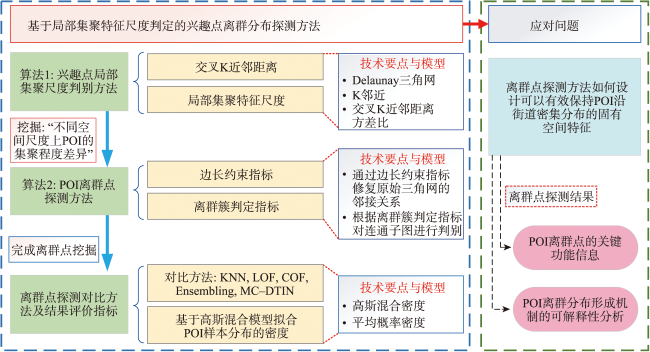
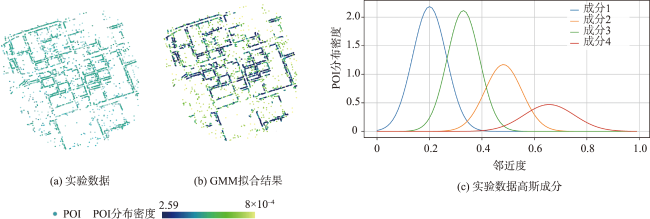
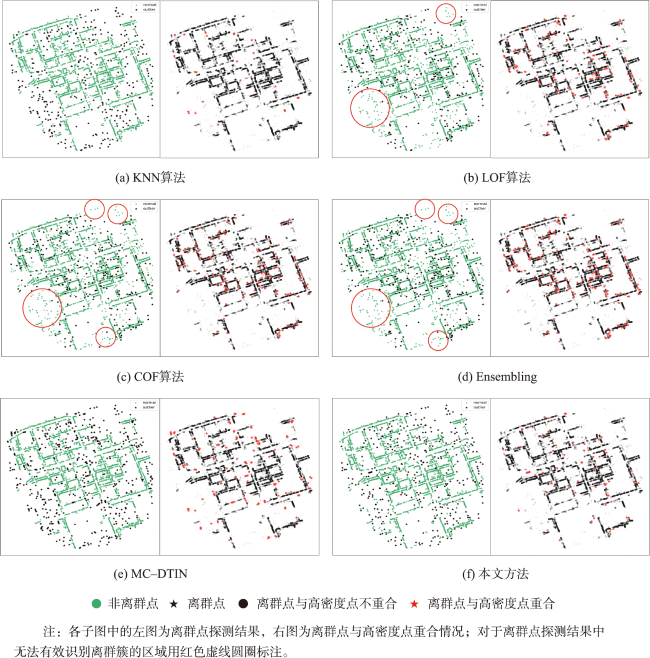
Points of Interest(POI), which are rich in semantic information, reflect current situations, and indicate areas of interest, serve as the primary data source in studies related to urban functionalization studies. These studies aim to deepen the understanding of human activities and environmental features within geographical spaces. An important research issue for enhancing the understanding of the human-environment system is detecting outliers, namely elements considerably different from the rest in large-scale spatial data. The detection of POI outliers can be broadly discussed from three perspectives: (1) spatial distribution differences, (2) spatial contextual differences, and (3) variations in the usage frequency of some POI instances and their surrounding points in specific areas due to factors such as special events, changes in urban population behavior, cultural activities, etc., leading to outliers. This paper focuses on discussing the phenomenon of POI outliers caused by spatial distribution differences. However, current outlier detection methods face with challenges. They fall short of adequately expressing and quantifying POIs' local spatial distribution features. The effectiveness of these methods needs further investigation. Given these considerations, this study proposed a novel approach for detecting POI outliers based on determination of local aggregation scales. Initially, we constructed spatial adjacency relationships of the POIs using Delaunay triangulation. Subsequently, the local aggregation characteristic scales of these points were determined by combining cross K-nearest distances and multi-scale feature parameters. Thereafter, based on the scale constraint, the points and their adjacent edge sets that met the conditions were extracted. Finally, we employed the edge length constraint index to systematically remove local long edges that did not meet the prescribed criteria. This meticulous process ensured the integration of the refined point set, thus facilitating the comprehensive detection of outliers within the POI context. The comparative experimental results, drawn from real-world data, suggested that the proposed method possessed a strong generalization ability. Moreover, it effectively and robustly detected outliers without compromising the inherent distribution characteristics of POI. We also performed an interpretability analysis of outlier detection results. The analysis revealed a close correlation between the causes of outlier distribution and various factors including the proportion of POI types, spatial layout, footprint area, and public awareness level. This study provides novel methodologies and academic perspectives for a comprehensive understanding of urban development trends, optimal resource allocation, and the enhancement of urban sustainability and quality of life.

WU Peng , Hasibagen , QIN Fuying . POI Outliers Detection Based on Local Aggregation Characteristic Scale Determination and Its Interpretability Analysis[J]. Journal of Geo-information Science, 2024 , 26(7) : 1594 -1610 . DOI: 10.12082/dqxxkx.2024.240039
| 算法1 兴趣点局部集聚尺度判别方法 |
|---|
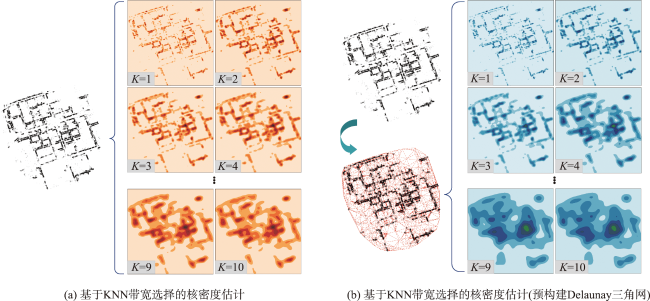
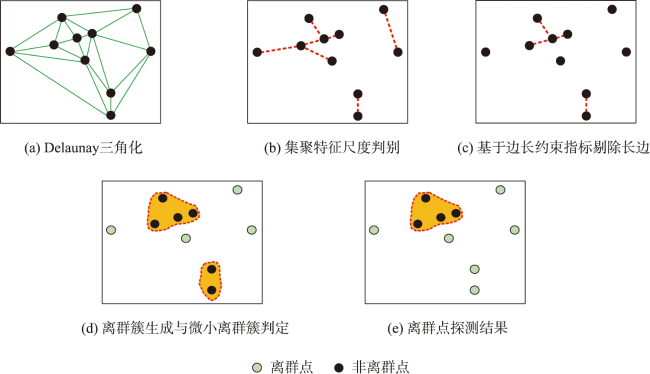
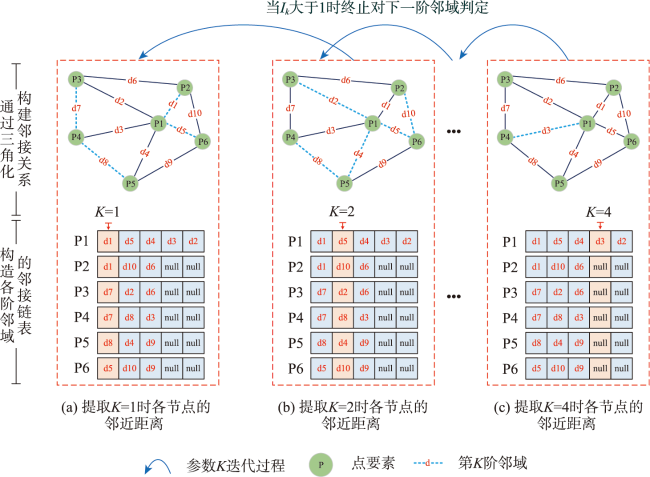
| 输入: 1实例点集合Pnts 2预定义两个空列表k_List, k_1_List 输出:集聚特征尺度参数K 步骤: 1通过Delaunay三角化,粗略表达实例点集的空间邻近关系: tri = Trianglulate(Pnts) 2提取tri中的边集E,并按照{[i, j]:Edge_Length | i, j∈Index(Pnts)}的结构构建边集字典EdgeDic,并提取全局点集的最大直接邻居个数Max_K 3基于EdgeDic构建图结构,其中图中任意节点的邻接点按照其邻接边长度由小到大构建邻接链表EdgeLink for k in [ 1, Max_K - 1]: 5 在EdgeLink中分别查找Pnts中每个点的第K个节点及第K+1个节点,即K邻域和K+1邻域,将结果分别存入k_List和k_1_List 6 根据定义2,计算交叉K与交叉K+1近邻距离方差比Ik 7 若Ik<1,则继续执行for循环,k_List和k_1_List置空 8 若Ik>1,则跳出for循环,return K, EdgeDic. 9 end for |
图3 本文方法执行过程示例Fig. 3 Illustration of the method proposed in this paper's execution process |
| 算法2 POI离群点探测方法 |
|---|
| 输入: 1局部集聚尺度参数K 2边集字典EdgeDic 3实例点集合Pnts 输出:离群点探测结果Outliers 步骤: 1 根据EdgeDic所构建的图结构及K值,截取每个节点的K邻域,生成K_EdgeDic, 根据定义3,基于K_EdgeDic计算边集的均值(Mean)和标准差(STD) |
| 2 for edge, edge_Length in K_EdgeDic: 3 根据定义3计算边长约束指标CI 4 if edge_Length<CI: continue 5 else: 在K_EdgeDic中删除edge相关的边记录; 6 end for 7 将点集Pnts与K_EdgeDic中剩余节点作差集运算,获得初步离群点探测结果Outlier. 8 创建一个空列表,用于存储连接子图的直径: diameter_List = [ ]. 9 for sub_g in connected components of K_EdgeDic: 10 if len( sub_g.nodes )<K+1: diameter_List.append( sub_g.diameter ) 11 end for 12 计算直径数值序列diameter_List的均值、中位数和标准差; 13 遍历K_EdgeDic中的所有子图,根据公式4计算指标,若子图直径小于该指标, 则存入Outlier_cluster 14 汇总离群点探测结果: Outliers = Outlier+Outlier_cluster 15 return Outliers |
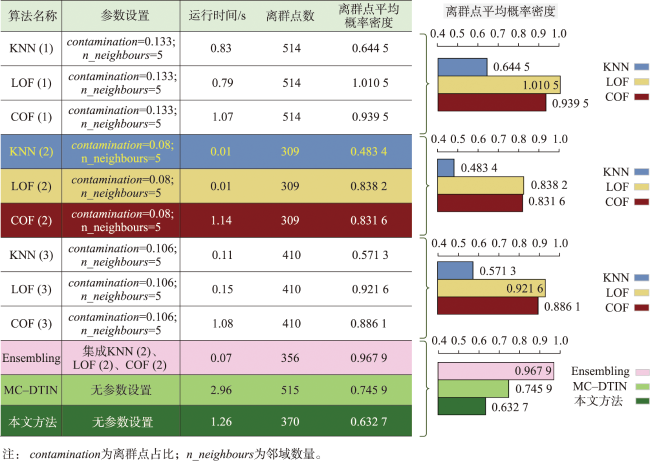
表1 各离群点探测方法详细信息Tab. 1 Details of various outlier detection methods |
| 算法名称 | 算法复杂度 | 算法复杂度说明 | 算法描述 |
|---|---|---|---|
| KNN | 对于KNN、LOF、COF及其集成算法的复杂度均采用大O计数法表达,其中N为POI要素的规模 | KNN: 计算每个点与其他点的距离,并选择最近的K个邻居 | |
| LOF | LOF: 通过比较每个点与其邻域点的密度,计算局部离群因子 | ||
| COF | COF: 基于LOF,考虑全局信息,计算局部离群因子的平均值 | ||
| Ensembling | Ensembling: 构建共现矩阵(相似度图);计算拉普拉斯矩阵;特征值分解 | ||
| MC-DTIN | MC-DTIN算法中N为POI要素的规模;M为初始Delaunay三角网的边数; m为删除全局长边后的各点的邻域个数 | MC-DTIN: 构建Delaunay三角网;分别基于三层边长约束指标提取离群点 | |
| 本文方法 | | 本文方法中N为POI的规模; K为邻域个数; Np为新边集规模; Nsub_g为连通子图数量; E为子图中边数 | 构建Delaunay三角网;识别显著局部集聚尺度并生成新边集(Np);根据边长约束指标提取离群点,并在剩余点集(连通子图数量为Nsub_g)中识别离群簇 |
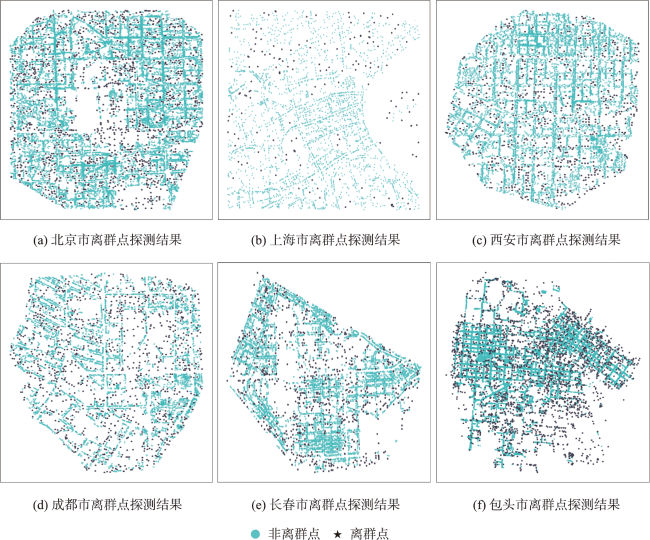
表3 各城市POI样本数据信息及其在本文方法中的离群点探测结果Tab. 3 The sample data of POI from multiple cities, along with their outlier detection results using the proposed method |
| 城市 | 点要素数 /个 | 路网类型 | 集聚特征 尺度 | 离群点数 /个 |
|---|---|---|---|---|
| 北京 | 21 928 | 棋盘状 | K=3 | 1 487 |
| 上海 | 2 992 | 蛛网状 | K=3 | 167 |
| 西安 | 12 235 | 棋盘状 | K=3 | 764 |
| 成都 | 10 269 | 环形放射状 | K=2 | 1 165 |
| 长春 | 9 461 | 放射状 | K=2 | 855 |
| 包头 | 33 101 | 环形放射状 | K=2 | 2 687 |
表4 POI各类型中离群点占比Tab. 4 Outliers percentage in each type of POI |
| 类型编码 | POI类型名称 | 离群点占比 | 类型编码 | POI类型名称 | 离群点占比 |
|---|---|---|---|---|---|
| ‘180105’ | 高尔夫球场 | 1.00 | ‘180310’ | 海洋馆 | 0.67 |
| ‘190107’ | 北京市政府 | 1.00 | ‘230127’ | 机场 | 0.67 |
| ‘230226’ | 大型露营公园 | 1.00 | ‘230216’ | 加气站 | 0.58 |
| ‘180106’ | 运动俱乐部 | 0.95 | ‘230203’ | 交通出口 | 0.58 |
| ‘210211’ | 陵园&公墓 | 0.83 | ‘180304’ | 公园广场 | 0.57 |
| ‘180301’ | 生态果园 | 0.77 | ‘180308’ | 动物园 | 0.55 |
| ‘250100’ | 农场&大型绿地 | 0.75 | ‘140202’ | 汽车检测中心 | 0.54 |
| ‘230209’ | 收费站 | 0.70 | ‘230201’ | 旅游景点桥 | 0.54 |
| ‘230202’ | 立交桥等 | 0.69 | ‘180109’ | 垂钓园 | 0.50 |
| ‘180104’ | 滑雪场 | 0.67 | ‘230103’ | 火车站 | 0.50 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
薛冰, 赵冰玉, 李京忠. 地理学视角下城市复杂性研究综述——基于近20年文献回顾[J]. 地理科学进展, 2022, 41(1):157-172.
[
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
张景奇, 史文宝, 修春亮. POI数据在中国城市研究中的应用[J]. 地理科学, 2021, 41(1):140-148.
[
|
| [11] |
范红超, 孔格菲, 杨岸然. 众源地理信息研究现状与展望[J]. 测绘学报, 2022, 51(7):1653-1668.
[
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
邓敏, 石岩, 龚健雅, 等. 时空异常探测方法研究综述[J]. 地理与地理信息科学, 2016, 32(6):8.
[
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
李光强, 邓敏, 朱建军, 等. 一种顾及邻近域内实体间距离的空间异常检测新方法(英文)[J]. 遥感学报, 2009, 13(02):197-202.
[
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
谢娟英, 高红超, 谢维信. K近邻优化的密度峰值快速搜索聚类算法[J]. 中国科学:信息科学, 2016, 46(2):258-280.
[
|
| [29] |
周玉, 朱文豪, 房倩, 等. 基于聚类的离群点检测方法研究综述[J]. 计算机工程与应用, 2021, 57(12): 37-45.
[
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
邹彤彤, 刘孝义, 刘金泉, 等. 基于MetaOD模型选择的岩土工程数据异常检测方法[J]. 地质科技通报, 2022, 41(2):239-245.
[
|
| [35] |
王圣音, 刘瑜, 陈泽东, 等. 大众点评数据下的城市场所范围感知方法[J]. 测绘学报, 2018, 47(8):1105-13.
[
|
| [36] |
|
| [37] |
邓敏, 谌恺祺, 石岩, 等. 多尺度空间同位模式挖掘的点过程分解方法[J]. 测绘学报, 2022, 51(2):258-268.
[
|
| [38] |
|
| [39] |
黄潇莹, 李霖, 颜芬. 基于多源兴趣点的模糊地名空间范围划分方法[J]. 地理信息世界, 2016, 23(6):61-67,72.
[
|
| [40] |
常飞, 王录仓, 马玥, 等. 城市公共服务设施与人口是否匹配?——基于社区生活圈的评估[J]. 地理科学进展, 2021, 40(4):607-619.
[
|
| [41] |
柴彦威, 李春江, 夏万渠, 等. 城市社区生活圈划定模型——以北京市清河街道为例[J]. 城市发展研究, 2019, 26(9):1-8,68.
[
|
| [42] |
李琦, 林志勇. 顾及空间及语义相关性的POI位置标注优化方法[J]. 地球信息科学学报, 2022, 24(7):1254-1263.
[
|
| [43] |
曹元晖, 刘纪平, 王勇, 等. 基于POI数据的城市建筑功能分类方法研究[J]. 地球信息科学学报, 2020, 22(6):1339-1348.
[
|
| [44] |
杨敏, 蒋琛俊, 李莹, 等. 分布依存规则指导的空间数据冲突探测与一致性改正[J]. 测绘通报, 2020, 0(12):50-53,70.
[
|
| [45] |
谭永滨, 李小龙, 程朋根, 等. 顾及距离约束的地标相对影响力评价模型[J]. 测绘学报, 2021, 50(12):1663-70.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}