
Journal of Geo-information Science >
An Intelligent Site Selection Approach for Public Service Facilities Coupled with Improved Graph Attention Network and Deep Reinforcement Learning
Received date: 2024-01-21
Revised date: 2024-02-18
Online published: 2024-11-07
Supported by
National Key Research and Development Program of China(2022YFB3903700)
National Key Research and Development Program of China(2022YFB3903704)
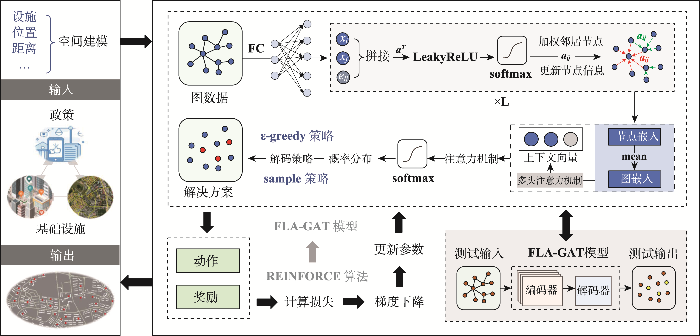
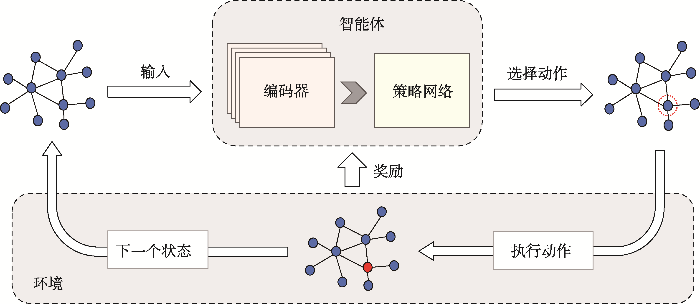
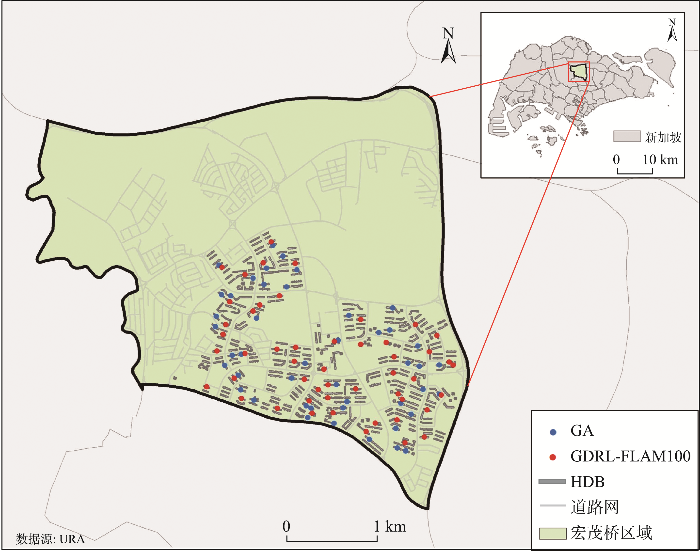
In the context of the rapid development of urbanization, the reasonable selection of locations for public service facilities is critical for delivering efficient services and enhancing the quality of urban residents' lives. However, prevailing approaches for allocation of public service facilities often fall short of meeting the demands on their performance and efficiency in complex and large-scale real-world scenarios. To address these issues, this article proposed a novel Graph-Deep-Reinforcement-Learning Facility Location Allocation Model (GDRL-FLAM), coupling a Facility Location Allocation Graph Attention Network (FLA-GAT) with a Deep Reinforcement Learning (DRL) algorithm. This proposed model tackled the location allocation problem for public service facilities based on graph representation and the REINFORCE algorithm. To assess the performance and efficiency of the proposed model, this study conducted experiments based on randomly generated datasets with 20, 50, and 100 points. The experimental results indicated that: (1) For the tests with 20, 50, and 100 points, the GDRL-FLAM model exhibited a significant improvement ranging from 11.79% to 14.49% compared to the Genetic Algorithm (GA) which is one of the commonly used heuristic algorithms for addressing location allocation problems. For the tests with 150 and 200 points, the improvement ranged from 1.52% to 9.35%. Moreover, with the increase in the size of the training set, the model also demonstrated enhanced generalizability on large-scale datasets; (2) The GDRL-FLAM model showed strong transfer learning ability to obtain the location allocation strategies in simple scenarios and adapt them to more complex scenarios; (3) In the case study of Singapore, the GDRL-FLAM model outperformed GA significantly, achieving obvious improvements ranging from 1.01% to 10.75%; (4) In all these abovementioned tests and experiments, the GDRL-FLAM model showed substantial improvement in efficiency compared to GA. In short, this study demonstrated the potential of the proposed GDRL-FLAM model in addressing the location allocation issues for public service facilities, due to its generalization and transfer learning abilities. The proposed GDRL-FLAM could also be adapted to solve other spatial optimization problems. Finally, the article discussed the limitations of the model and outlined potential directions for future research.

WANG Zhong , CAO Kai . An Intelligent Site Selection Approach for Public Service Facilities Coupled with Improved Graph Attention Network and Deep Reinforcement Learning[J]. Journal of Geo-information Science, 2024 , 26(11) : 2452 -2464 . DOI: 10.12082/dqxxkx.2024.240044
表1 参数设置Tab. 1 Parameter setting |
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| Epoch | 200 | 学习率衰减系数 α | 0.98 |
| 编码层数L | 4 | ε | 0.90 |
| 学习率 | 0.000 1 | ε 衰减系数 β | 0.99 |
| 节点嵌入维度hx | 128 | 边嵌入维度he | 64 |
表2 不同节点数量下的GDRL-FLAM性能评估Tab. 2 Performance evaluation of the GDRL-FLAM with different numbers of nodes |
| 方法 | FLP20 | FLP50 | FLP100 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 目标值 | DI/% | 时间 | 目标值 | DI/% | 时间 | 目标值 | DI/% | 时间 | |||
| GA | 4.411 | 0.00 | 3 h | 8.700 | 0.00 | 5 h | 14.081 | 0.00 | 12 h | ||
| GDRL-FLAM (ε-greedy) | 3.773 | 14.33 | 11 min | 7.593 | 12.56 | 27 min | 12.400 | 11.79 | 58 min | ||
| GDRL-FLAM (Sample) | 3.766 | 14.49 | 24 min | 7.566 | 12.87 | 53 min | 12.373 | 11.99 | 2 h | ||
表3 FLP150泛化性能测试结果Tab. 3 Generalization performance test results for FLP150 |
| 方法 | GDRL-FLAM50 | GDRL-FLAM100 | |||||
|---|---|---|---|---|---|---|---|
| 目标值 | DI/% | 时间/h | 目标值 | DI/% | 时间/h | ||
| GA | 17.787 | 0.00 | 11 | 17.787 | 0.00 | 11 | |
| GDRL-FLAM (ε-greedy) | 17.406 | 1.97 | 2 | 16.273 | 8.34 | 2 | |
| GDRL-FLAM (Sample) | 16.922 | 4.69 | 5 | 16.094 | 9.35 | 5 | |
表4 FLP200泛化性能测试结果Tab. 4 Generalization performance test results for FLP200 |
| 方法 | GDRL-FLAM50 | GDRL-FLAM100 | |||||
|---|---|---|---|---|---|---|---|
| 目标值 | DI/% | 时间/h | 目标值 | DI/% | 时间/h | ||
| GA | 15.282 | 0.00 | 10 | 15.282 | 0.00 | 10 | |
| GDRL-FLAM (ε-greedy) | 15.026 | 1.52 | 1 | 14.613 | 4.23 | 1 | |
| GDRL-FLAM (Sample) | 14.792 | 3.06 | 4 | 13.835 | 9.33 | 4 | |
表5 迁移学习测试结果Tab. 5 The test results of transfer learning |
| 方法 | 预训练 | 从头开始 | |||||
|---|---|---|---|---|---|---|---|
| 目标值 | DI/% | 时间 | 目标值 | DI/% | 时间 | ||
| GA | 8.700 | 0.00 | 5 h | 8.700 | 0.00 | 5 h | |
| GDRL-FLAM (ε-greedy) | 7.588 | 12.63 | 26 min | 7.593 | 12.56 | 27 min | |
| GDRL-FLAM (Sample) | 7.561 | 12.94 | 53 min | 7.566 | 12.87 | 53 min | |
表6 新加坡案例实验结果Tab. 6 The results of case study in Singapore |
| 方法 | GDRL-FLAM50 | GDRL-FLAM100 | |||
|---|---|---|---|---|---|
| 目标值 | DI/% | 目标值 | DI/% | ||
| GA | 16.715 | 0.00 | 16.715 | 0.00 | |
| GDRL-FLAM (ε-greedy) | 16.546 | 1.01 | 15.590 | 6.73 | |
| GDRL-FLAM (Sample) | 15.900 | 4.88 | 15.031 | 10.75 | |
| [1] |
高军波, 周春山. 西方国家城市公共服务设施供给理论及研究进展[J]. 世界地理研究, 2009, 18(4):81-90.
[
|
| [2] |
国家发展改革委. 关于印发《“十四五”公共服务规划》的通知[EB/OL].(2022-01-10)[2024-01-21]. https://www.gov.cn/zhengce/zhengceku/2022-01/10/content_5667482.html.
[National Development and Reform Commission. Notice on Issuing the "14th Five-Year Plan" Public Service Plan[EB/OL].(2022-01-10)[2024-01-21]. https://www.gov.cn/zhengce/zhengceku/2022-01/10/content_5667482.html.]
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
关亚宾, 马瑞, 孔云峰. 城市社区便民服务中心选址模型研究[J]. 地球信息科学学报, 2023, 25:2164-2177.
[
|
| [13] |
翟石艳, 孔云峰, 宋根鑫, 等. 面向15 min生活圈的城市服务设施规划模型与实验[J]. 地理学报, 2023, 78(6):1484-1497.
[
|
| [14] |
|
| [15] |
|
| [16] |
席裕庚, 柴天佑, 恽为民. 遗传算法综述[J]. 控制理论与应用, 1996, 13(6):697-708.
[
|
| [17] |
黎夏. 协同空间模拟与优化及其在快速城市化地区的应用[J]. 地球信息科学学报, 2013, 15(3):321-327.
[
|
| [18] |
李凯文, 张涛, 王锐, 等. 基于深度强化学习的组合优化研究进展[J]. 自动化学报, 2021, 47(11):2521-2537.
[
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
王玉璟, 孔云峰. 义务教育就近入学优化建模研究[J]. 地球信息科学学报, 2021, 23(9):1608-1616.
[
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
刘萌伟, 黎夏. 基于Pareto多目标遗传算法的公共服务设施优化选址研究——以深圳市医院选址为例[J]. 热带地理, 2010, 30(6):650-655.
[
|
| [44] |
|
| [45] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}