
Journal of Geo-information Science >
A Critical Road Segment Identification Method Using Two-Stage Feature Learning with Dynamic and Static Road Segment Embedding
Received date: 2024-08-30
Revised date: 2024-10-30
Online published: 2025-01-23
Supported by
National Key Research and Development Program of China(2023YFB3906804)
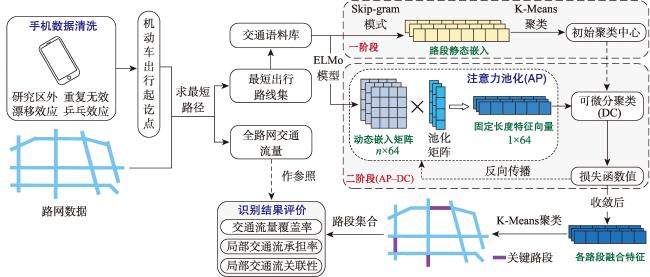
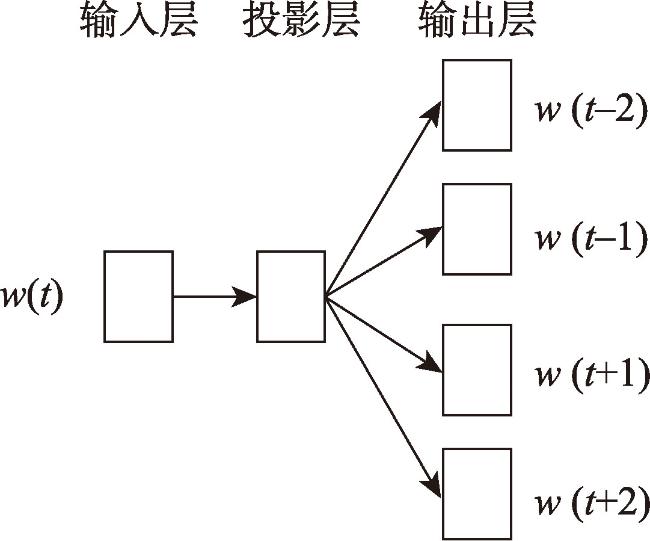
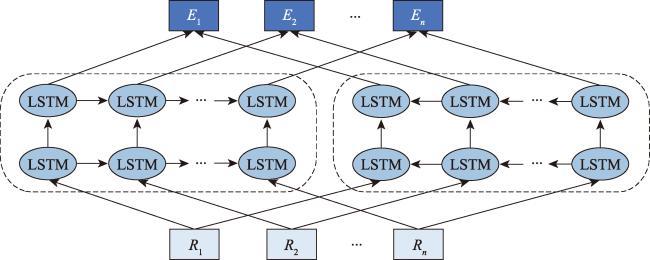
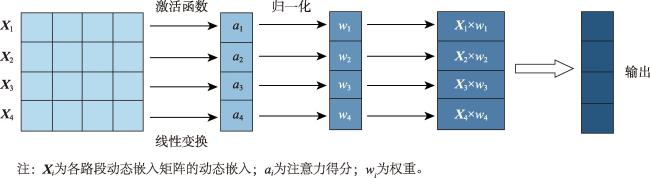
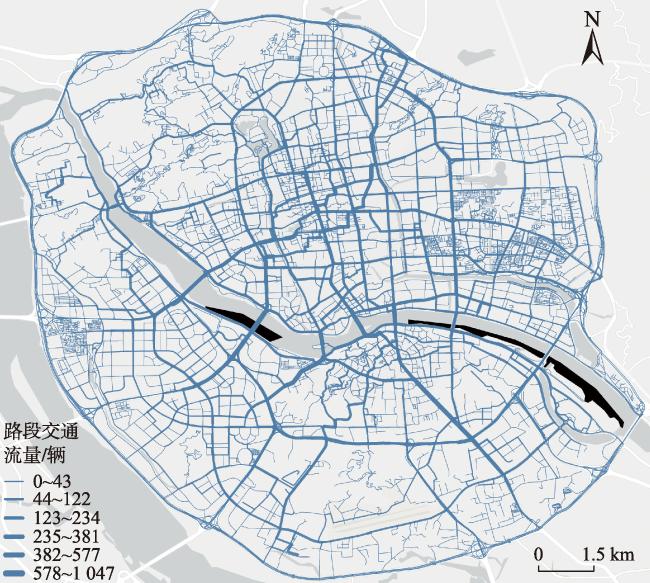
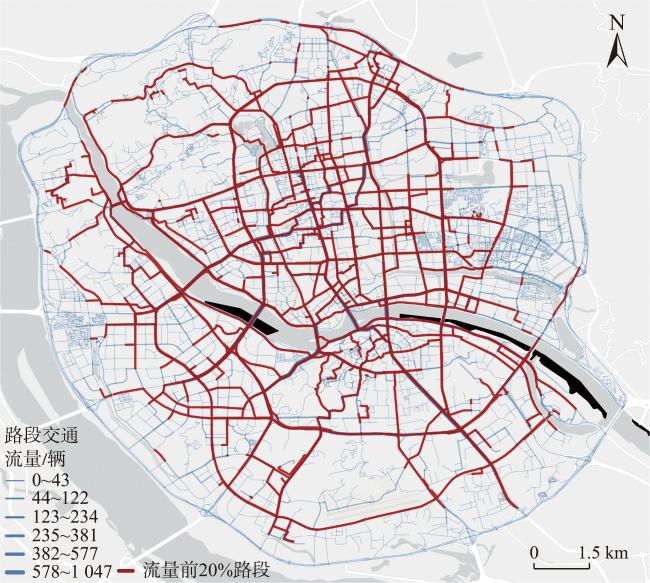
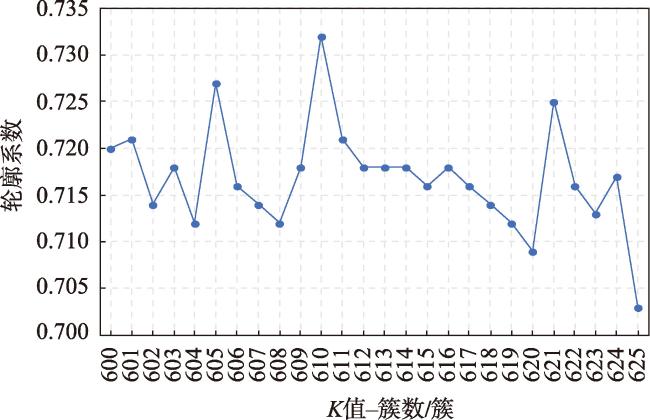
[Objectives] The accurate identification of critical road segments is crucial for effective traffic management across entire road networks. While significant progress has been made in identifying critical road segments, existing methods often fail to identify relatively critical road segments in local areas with lower traffic flow, particularly in large-scale networks such as city-level road systems. [Methods] To address this limitation, this study proposes a two-stage feature learning method based on the dynamic and static embeddings of road segments to identify critical road segments in large-scale networks. The proposed method consists of several key steps. First, travel routes are extracted from mobile positioning data to construct a comprehensive traffic corpus, which serves as the foundation for further analysis. Next, a two-stage feature learning process is conducted: (1) Static embeddings are extracted for each road segment to capture their inherent, unchanging characteristics. These embeddings are clustered to identify initial cluster centers, which serve as preliminary indicators of critical road segments. (2) Dynamic embeddings are then extracted for each road segment and processed using attention pooling, which emphasizes the most relevant aspects of the traffic data. These pooled feature vectors are subjected to differentiable clustering, a technique that optimize the clustering process through a loss function. The model iteratively adjusts until the loss value converges, signaling optimal clustering. Upon convergence, the static and dynamic features are fused to generate comprehensive feature representations for each road segment. These fused features are clustered again to identify the final cluster centers, which represent the critical road segments within the network. To validate the proposed method, a traffic corpus is constructed by using mobile positioning data from the Third Ring Road area of Fuzhou City. [Results] An identification experiment and comparative analysis of critical road segments are conducted using this road network as a case study. The results show that the proposed method effectively identifies critical road segments in large-scale road networks and relatively critical segments in local areas. [Conclusions] Furthermore, compared to existing methods, this method achieves superior performance across various evaluation metrics, indicating that the identified set of critical road segments is more reasonable and practical.
WU Weiyi , WU Sheng . A Critical Road Segment Identification Method Using Two-Stage Feature Learning with Dynamic and Static Road Segment Embedding[J]. Journal of Geo-information Science, 2025 , 27(1) : 167 -180 . DOI: 10.12082/dqxxkx.2025.240483
表1 手机定位数据示例Tab. 1 Example of mobile phone location data |
| 脱敏ID | 经度/°E | 纬度/°N | 定位时间 | 场景二级分类 |
|---|---|---|---|---|
| 00001f09-05bf-440b-a92e-9dbf99d7eef2 | 119.245 | 26.079 | 2023-03-20 13:58:57 | 酒店宾馆 |
| 00002edc-5b31-42d7-913b-4c06358ef30a | 119.231 | 26.077 | 2023-03-20 15:20:37 | 地铁站 |
| … | … | … | … | … |
| 00004561-f310-4651-b9c5-ce2ec06d755b | 119.324 | 26.084 | 2023-03-20 11:37:25 | 小吃快餐 |
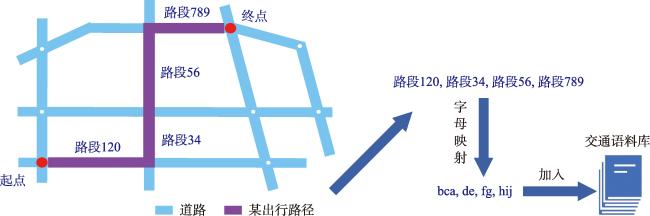
表2 交通语料库示例Tab. 2 Example of traffic corpus |
| 出行路线的路段序列 | 对应句子 |
|---|---|
| 路段123,路段456,路段789 | bcd efg hij |
| 路段10,路段23,路段45,路段67,路段89 | ba cd ef gh ij |
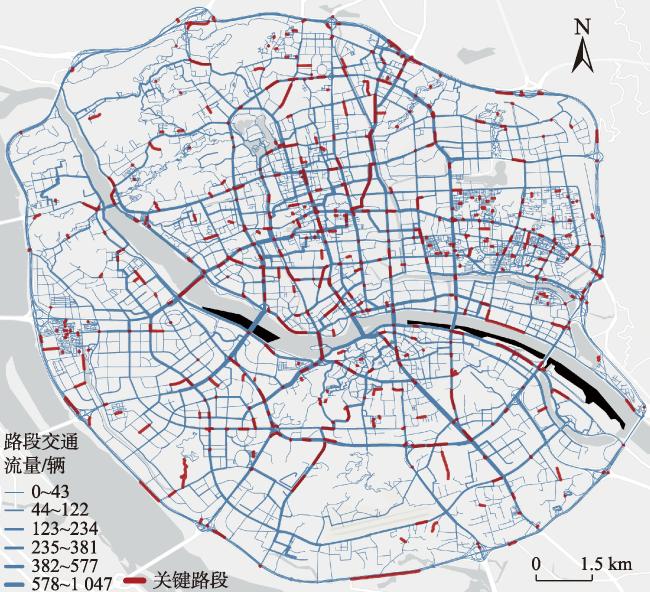
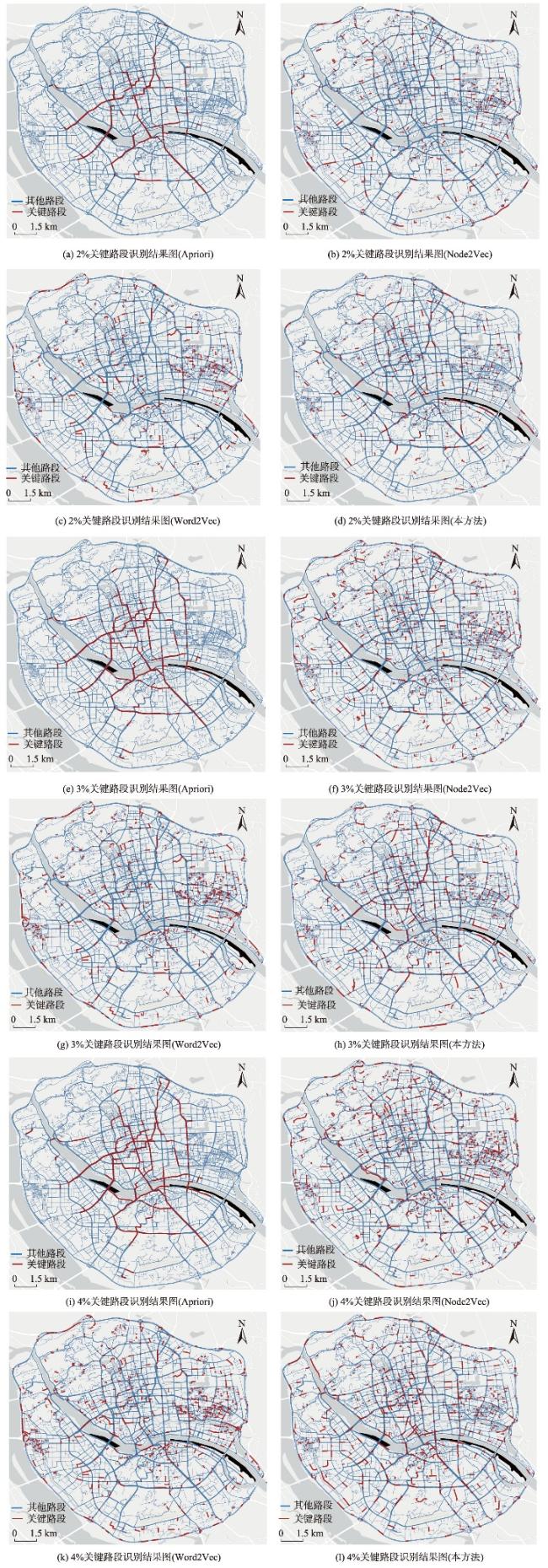
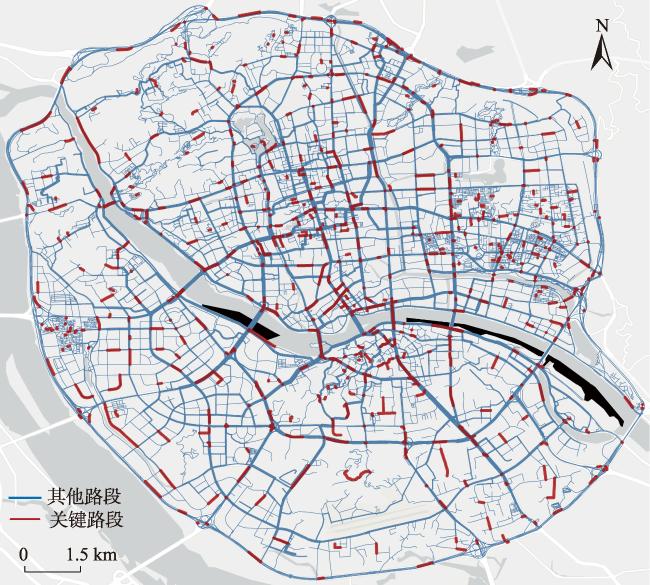
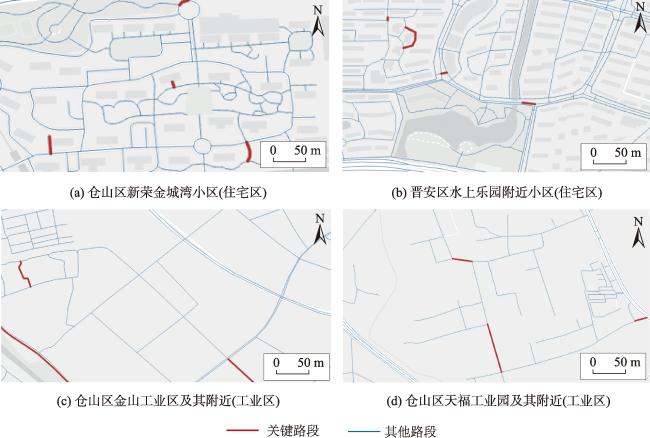
图10 福州市三环内区域路网不同方法关键路段识别结果Fig. 10 Identification results of critical road sections in the road network within the third ring road of Fuzhou by different methods |
表3 不同方法的关键路段识别结果对比Tab. 3 Comparison of critical road segment identification results by different methods |
| 关键路段流量 | 方法 | 交通流覆盖率/% | 局部交通流承担率/% | 局部交通流关联性 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1阶 | 2阶 | 3阶 | 1阶 | 2阶 | 3阶 | 第1阶 | 第2阶 | 第3阶 | ||||
| 2% | Apriori | 27.94 | 39.13 | 49.19 | 20.32 | 8.71 | 4.44 | 0.528 | 0.356 | 0.288 | ||
| Node2Vec | 9.41 | 25.78 | 48.77 | 14.54 | 5.11 | 2.46 | 0.379 | 0.251 | 0.203 | |||
| Word2Vec | 8.10 | 21.08 | 38.11 | 18.01 | 6.31 | 2.99 | 0.374 | 0.217 | 0.153 | |||
| 本方法 | 19.76 | 38.83 | 59.32 | 20.04 | 8.76 | 4.73 | 0.523 | 0.388 | 0.339 | |||
| 3% | Apriori | 38.70 | 50.81 | 59.99 | 20.08 | 8.07 | 4.34 | 0.527 | 0.344 | 0.277 | ||
| Node2Vec | 15.80 | 41.85 | 71.78 | 14.74 | 5.21 | 2.55 | 0.396 | 0.273 | 0.225 | |||
| Word2Vec | 11.44 | 28.62 | 49.87 | 17.82 | 6.34 | 2.97 | 0.382 | 0.213 | 0.156 | |||
| 本方法 | 29.05 | 53.76 | 73.44 | 19.89 | 8.24 | 4.56 | 0.519 | 0.375 | 0.319 | |||
| 4% | Apriori | 42.53 | 54.38 | 62.82 | 19.84 | 8.25 | 4.71 | 0.523 | 0.338 | 0.268 | ||
| Node2Vec | 19.12 | 50.05 | 78.88 | 13.86 | 4.94 | 2.45 | 0.375 | 0.255 | 0.216 | |||
| Word2Vec | 14.56 | 36.29 | 60.78 | 17.44 | 6.19 | 2.90 | 0.374 | 0.215 | 0.154 | |||
| 本方法 | 35.24 | 61.01 | 80.28 | 20.31 | 8.61 | 4.68 | 0.539 | 0.378 | 0.323 | |||
注:加粗数值表示每个指标中的最佳表现。 |
利益冲突:Conflicts of Interest 所有作者声明不存在利益冲突。
All authors disclose no relevant conflicts of interest.
| [1] |
|
| [2] |
贾洪飞, 郭明雪, 罗清玉, 等. GPS数据下的城市路网关键路段识别[J]. 吉林大学学报(工学版), 2020, 50(4):1338-1343.
[
|
| [3] |
苏飞, 董宏辉, 贾利民, 等. 基于时空相关性的城市交通路网关键路段识别[J]. 交通运输系统工程与信息, 2017, 17(3):213-221.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
万蔚, 黄雨晨, 王振华, 等. 突发状况下的道路网络故障演化分析——以通州市区道路网络为例[J]. 重庆交通大学学报(自然科学版), 2019, 38(11):14-20,40.
[
|
| [9] |
李永成, 刘树美, 于尧, 等. 兼顾路段和交叉口的路网脆弱性识别机制[J]. 北京邮电大学学报, 2020, 43(1):14-20.
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
张德欣, 刘小明, 孙立光, 等. 基于大规模定位数据的出行方式模糊判别研究[J]. 交通信息与安全, 2011, 29(2):1-4.
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
真诗泳, 林钦贤, 张露丹, 等. 基于多源数据的城市内部空间交互特征:以福州市主城区为例[J]. 科学技术与工程, 2023, 23(35):14937-14946.
[
|
| [21] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}