王胜开 , 徐志洁, 张健钦
, 徐志洁, 张健钦
WANG Shengkai, XU Zhijie, ZHANG Jianqin
通讯作者:
收稿日期: 2017-08-15
修回日期: 2018-02-16
网络出版日期: 2018-04-20
版权声明: 2018 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:王胜开(1989-),男,河北邢台人,硕士,主要从事交通GIS,地理可视化,虚拟地理环境方面研究。 E-mail: shengkai_bucea@163.com
展开
摘要
热力图是对数据的一种直观的表示方法,在空间大数据挖掘和知识发现的研究中具有良好的展示效果。本文研究了一种逆向渲染流程绘制热力图的方法,提出了将渲染器像素映射的地理空间作为计算分析的空间粒度,解决了热力图影响力叠加规则依赖于渲染器机制的缺点。逆向渲染热力图方法使用地理距离与绘制像素结合计算得到分析点缓冲区半径系数和影响力参数,以此来减弱在不同的地图尺度下热力图的形变程度。采用Kapur多级分割算法自动探测图像阈值得到色彩梯度,优化了热力效应的分级展示,在视觉效果上数据特征更加美观清晰。本文通过一组实验进行了验证,数据是由北京市交通委提供的公交IC刷卡记录,提取了其中某一时间段的刷卡数据作为样本,在相同的实验条件下,分别使用基于开源的Leaflet在线地图和Canvas渲染技术2种绘制热力图渲染方法,得到可视化结果后对比分析。在相同的实验条件下,逆向渲染热力图的可视化效果更符合现代的多尺度电子地图需求,更适用于地理空间POI点空间特征可视化。
关键词:
Abstract
As a graphical representation and visualization method, Heatmap has a more visual and comprehensive display effect due to its capability in large spatial data mining and knowledge discovery, compared with standard analysis chart. With the development of big data and multi-scale digital map technology, a static Heatmap has not been able to meet the user requirements and heatmap has begun to turn multidimensional. This paper presents a method of drawing the Heatmap using the reverse rendering process, in which the geographic space mapped by renderer pixels was taken as the spatial granularity in calculation and analysis. This method solved the problem that the influence superposition mode of the Heatmap is much limited by the rendering mechanism. With the improved method, the influence superposition mode can be flexibly selected according to the analysis requirements, and radius coefficient and influence parameter of the analysis point are calculated by combining the geographical distance and rendering pixel to reduce the deformation of heatmap at different map scales. We used the Kapur multi-level segmentation algorithm to automatically detect the image threshold and get the gradient colors, so that the hierarchical display of thermodynamic effect can be optimized and the visual effects on the data can be more beautiful and clear in the map. This method was tested in a group of experiments with bus IC card records provided by Beijing Municipal Transportation Commission. Under the same experiment condition, Heatmaps were derived by using the reverse rendering process method, as well as the standard process method, both based on the leaflet map and Canvas render. The visual results of the two methods were compared and analyzed at different map scales in different locations. It shows that the visualization effects of reverse rendering method can provide more stable details and more comprehensive display of data features under same experiment conditions. This indicates that the proposed reverse rendering method can improve the visualization effect of spatial features of POI (position of interest) points in Heatmap and is more in line with the requirements of modern multi-scale digital map.
Keywords:
随着大数据的蓬勃发展,数据可视化技术也随之快速发展。由于大数据中捆绑着大量地理空间信息,而热力图作为一种直观的可视化方法[1],具有综合展示数据地理空间特征和属性特征的良好特性,可帮助各个领域的研究人员获取地理空间知识[2],因此深受欢迎。国内的赵婷等[3]使用微软内部发布的Heat Map并结合K-means聚类算法针对地理标签数据的可视化表达进行了研究;杨微等[4]使用了影响力叠加算法改进后绘制的热力图对全国居民小区价格进行了分析;吴志强等[5]则通过使用百度热力图对上海市城市空间结构进行探索研究。国外,Spakov等[6]通过数据聚集热图可视化技术根据人眼凝视调整热图的透明度,实现了轨迹实验验证和产品的可用性研究;Bojko[7]提出针对不同的需求选择不同的热力图可视化技术,并在轨迹可视化方面符合人类视觉分辨要求;Benomar等[8]利用热力图研究软件系统在时间维度和空间维度的动态性。
在热力图具体绘制方面,作为一种基于密度的定性分析可视化方法,其本身是依赖于数据的空间位置信息绘制而成的。一般的热力图,将数据进行投影聚类[9,10],确定数据点影响半径,然后绘制出热力灰度图,并用渐变色为热力图赋色。很多开源网络地图如:国外的Openlayer、Leaflet以及国内的百度地图、天地图和超图地图等在线地图都为开发者提供了API接口或插件,可以在这些平台上便捷地实现一般热力图的绘制。在当前互联网时代里,多尺度网络电子地图迅速发展,之前的热力图可视化研究和一般热力图绘制也存在一些不足,主要有以下4点:① 自适应能力差,不同尺度下变形失真,在不同的地图比例下,热力图所展示的数据特征差异很大;② 点影响域叠加模式单一,叠加模式只取决于渲染器的叠加规则,导致影响因子算法对数据特征探测不够灵敏;③ 生成热力图的色彩梯度凭经验构造,不同的热力图需要尝试多次才能得到合适的配色方案;④ 热力图在绘制时由于将数据投影到屏幕视窗,未充分考虑数据的地理空间特性。
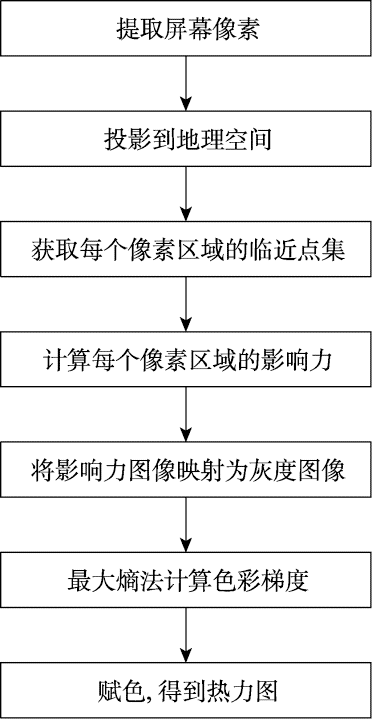
基于上述缺点,本文研究实现了一种逆向渲染热力图的绘制方法,即以视窗单个像素为分析点,根据适用于当前分析的影响力叠加模式[11]分析单个像素的临近数据点的分布并计算影响力灰度图(并非灰度值为0-255的传统意义灰度图),然后按照数据灰度图的整体分布规律划分得到渐变色分级阈值,以这种自适应的方式获得热力图的色彩梯度,然后赋色得到热力图。这种热力图渲染方法以像素替代数据点为分析元,极大减小了地理空间分析的粒度,将地图尺度变换对热力图的影响降到最低;提出新的影响力(热度)叠加模式,叠加机制不再依赖于渲染器的Alpha通道,保证了数据特征质量;全局分析完成后,通过最大熵法计算热度分级阈值,实现了热力图根据影响力分布自动分级配色,优化热力图可视化效果。此方法所有的计算分析都是在地理空间坐标下进行的,得到分析结果后再映射到渲染器中。
本文首先介绍一般热力图可视化原理和逆向热力图基本理论知识;然后介绍逆向热力图的实现方法;最后设计一个验证实验,以北京市公交IC卡刷卡记录形成的某个时段的站点客流登量数据为例绘制客流密度的热力图,对比分析一般的热力图绘制方法和本文逆向地理热力图绘制方法展示的城市人群的时空停留分布情况[12],并明确下一步的研究方向。
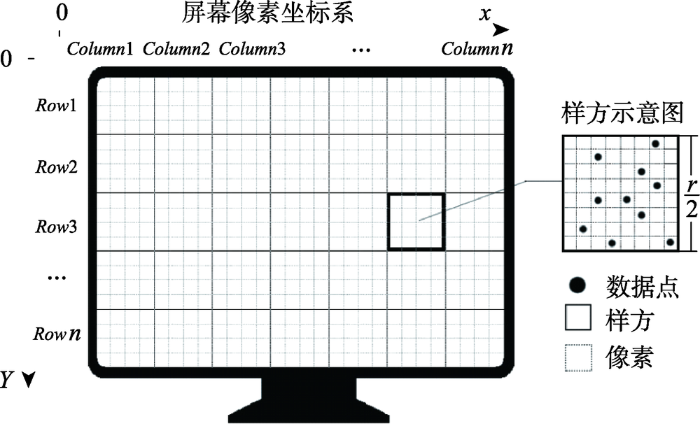
常见的热力图(以HeatMap为例)主要采用了密度分析样方法的思想[13]来优化渲染,首先将地理数据点投射在屏幕上,即将地理坐标投射为屏幕坐标,得到屏幕数据集Pi(式(1))。
式中:xi、yi分别为数据点的横纵坐标;zi为数据点属性值。
然后,确定热力图的渲染半径r。如图1所示,将屏幕划分为边长为r/2的方形样方,每个数据点位于一个样方中,根据数据点的屏幕坐标可以确定数据网格行列数(式(2))。
式中:xi、yi分别为数据点的横纵坐标;r为渲染半径。
最后,对每个样方的数据点集使用K-means算法[14]进行硬聚类计算形成聚类,假设某个样方内数据点集为Pn,n为点个数,每个点的坐标为xn、yn,点的属性值为zn。聚类计算公式见式(3)。
式中:X、Y、Z为聚类后的中心坐标和属性值。
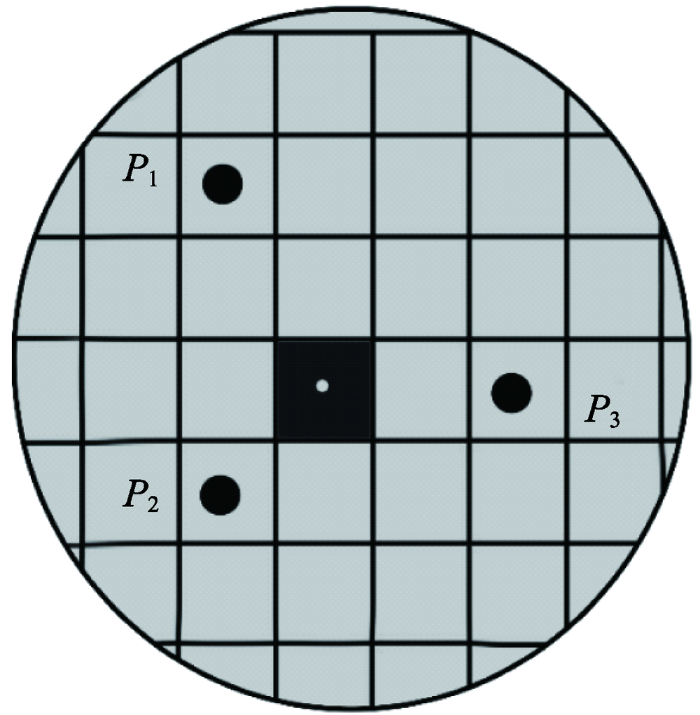
以聚类中心点为圆心(X、Y),半径为r绘制由内向外的透明度渐变圆[15],如图2所示。
透明度渐变圆中心灰度值大小由聚类点属性值(z值)决定,影响力自内而外线性衰减。
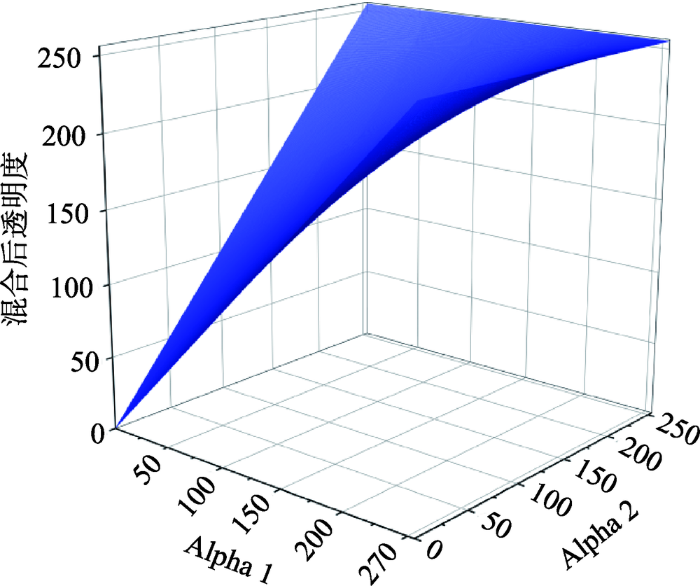
这种热力图绘制方法默认使用了渲染器像素alpha通道叠加规则作为影响力叠加模式,一般的渲染器叠加规则见式(4)。
式中:a为叠加后像元的alpha值;a1、a2为叠加像素的alpha值;a、a1、a2的值域都是[0, 255],具体模型如图3所示。
所有的聚类点绘制完成后就形成了灰度图,按照热度分级阈值使用不同颜色对灰度图赋色,就得到热力图。
本文研究将网络地图服务(WMS)作为地理空间平台,并采用现今大多数网络地图服务商使用的空间参照系EPSG:3857。它是欧洲石油勘测团体(EPSG)在2009年提出的一个球形墨卡托投影坐标系统,在这个坐标系统中,计算2个地理空间点之间的距离使用的是haversine算法(半正矢公式),2个点的空间距离d计算公式为:
式中:r为地球半径;φ1、φ2为2个点的纬度;μ1、μ2为2个点经度。
本文的逆向热力图基于核密度估计的思想,核密度估计是一种数学方法,通过平滑的数据点计算密度来达到降低取样伪差的目的[16]。如图4所示,每个热力图画板的像素点在地理空间中都表示一个矩形地理区域,以公交客流数据为例:根据公交站点数据的基本特征,选取距该区域中心1500 m之内的数据点为邻近数据点,从而得到一个邻近点数据集pm。(式(6))(根据《城市道路交通设计规范》规定,公交车站服务面积以500 m为半径不得小于城市面积90%,所以综合考虑客流密度分布规律和图像平滑条件,取影响半径h为1500 m,影响半径即公交站点的衰减距离阈值)。
式中:pn为数据点总集;On为距离像素点区域中心n米之内的区域。
每个临近点对这个像素点区域都存在一个影响力,此影响力I计算公式见下式(式(7)):
式中:z为数据点的属性值(如本文中的公交站点刷卡数据,z即为某一站点一定时间段内的刷卡数量);w为当前地理尺度下单个像素点的地理宽度; d为像素点中心到数据点的距离,由半正矢公式求得;δ为空间权重函数;h是距离衰减阈值。
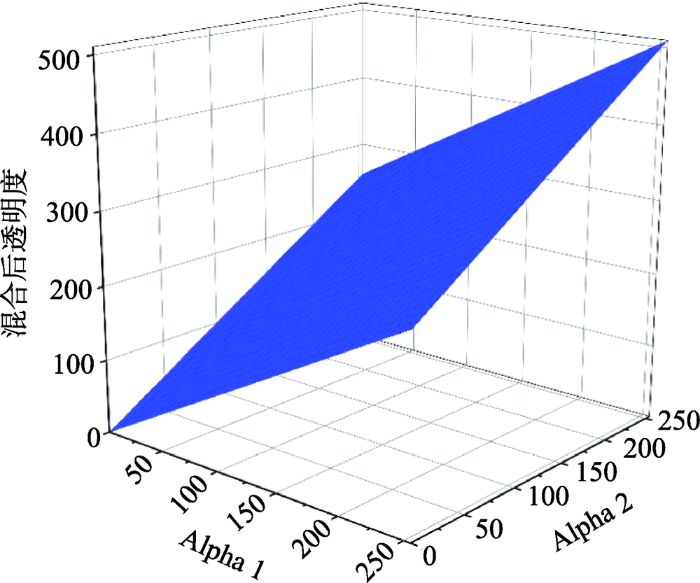
根据公共交通站客流的区位效应特点,本文采用线性叠加模型作为影像力叠加规则,具体模型如图5所示。
像素点的临近点影响力叠加总和即为该像素点的灰度值算子,得到视窗每个像素点的灰度算子之后,就可以将其映射到范围为[0, 255]的灰度区间内,渲染出影响力灰度图。色彩梯度[17]的计算受到吕宗伟提出的Kapur多级分割的阈值相关性及其快速实现算法的启发[18],采用最大熵法计算色彩梯度的分割阈值。最大熵法基本思想是把图像分为若干子图像,计算各子图像的熵,当各个子图像熵的和最大时,分割图像的各个阈值是最佳阈值。
图像灰度区间可以表示为{1,2,3,…,L},L是灰度图最大灰度值,ni表示灰度值为i的像素个数,N是图像像素的总数,图像的灰度概率函数为pi (式(8))。
图像熵H(式(9))的定义如下:
对于M(M>2)级分割,最大熵算法是把图像像素按照灰度值分为M个子图像,分别为C0={0,1,…,t1},C1={t1+1,…,t2},…,CM-1={tM-1,…,L}。
按照上面的公式计算每个子图像的熵,然后相加得到整个图像的熵φ(t1,t2,…,tm-1)(式(10))。
依次更改图像分割阈值,遍历所有可能的分割情况,迭代计算图像的熵,找到计算出最大的图像熵,其对应的一组分割阈值就是最佳阈值t*(式(11))。
本文热力图的绘制实现基于开源Web技术,主要使用了Leaflet交互式地图开源JavaScript库,这个库具有良好的可扩展性,在此基础上开发出利用Canvas渲染的JavaScript语言编写的热力图插件。Canvas渲染作为HTML5技术的新特性,其优秀的渲染机制和简洁灵活的API操作足够满足绘制美观、高精度的热力图,而JavaScript是当今流行的轻量级前端脚本语言,是Canvas画布的“画笔”。
目前已有的热力图绘图步骤主要是先将数据对象直接或经过聚集处理后绘制在屏幕上,形成灰度图,然后再对屏幕像素进行灰度渐变赋色,这是从数据点对象出发的正向绘图思维。本文研究了一种新的热力图绘制步骤,即逆向渲染探索绘制热力图,主要思想是以屏幕像素为对象,分析屏幕像素点所表示的地理区域和周围邻近数据点之间的相互联系计算获得像素点灰度值,并最终得到整个屏幕的灰度图。通过使用最大熵法自动获取多级分割阈值,生成渐变色来渲染灰度图,从而实现色彩梯度自适应并自定义影响力叠加模型。具体处理渲染流程如图6所示。
本文使用北京市公交站点在交通高峰时段客流数据绘制市区公交乘客分布热力图,通过热度分析市区客流分布情况。本次试验的公交客流数据由IC卡数据处理获得并存储在Oracle 11g数据库中,静态公交站点GIS数据由GeoServer发布,利用Java web工程架构整合数据,并在前端采用Canvas技术绘制热力图。
本实验截取了工作日2016年9月1日(星期四)的刷卡数据,全天刷卡记录共1349万条,涵盖北京市909条公共交通线路的44 267个公交站点,具体的数据格式如表1所示。实验截取10-14时共4 h的数据子集,共267万余条记录,然后进行统计归并处理得到公交站点客流登量数值数据,用于热力图绘制。
表1 公交刷卡数据格式
Tab. 1 Format of bus card data
| 字段名 | 字段类型 | 说明 |
|---|---|---|
| BUSDATA_ID | NUMBER(19) | 公交系统ID |
| DEAL_SEQ_NUM | NUMBER(10) | 交易序号 |
| GRANT_CARD_CODE | VARCHAR2(10) | 卡发行号 |
| LINE_CODE | NUMBER(5) | 运营线路编号 |
| VEHICLE_CODE | VARCHAR2(20) | 车辆号 |
| ON_STATION | VARCHAR2(20) | 上车站,上车站站标 |
| OFF_STATION | NUMBER(4) | 下车站,下车站站标 |
| UP_TIME | DATE | 上车时间 |
| DEAL_TIME | DATE | 下车时间 |
将上述得到的站点登量数据导入系统中,通过系统所处的视窗得到当前的Canvas画布像素,遍历站点登量数据,通过半正矢公式计算像素周围临近范围,对每个像素进行邻近点分析,计算出每个像素的影响力,绘制出影响力灰度图,再通过最小熵算法自动分析灰度图分布规律,得到热力图渐变分割阈值,最后通过所得的渐变色对灰度图赋色,得到最终的热力图。
为了对试验结果更好的评定,本文使用Heatmap对同一批数据做热力图进行对比分析。为了保证实验结果对比效果,本文在同一渲染器中绘制2种方法的热力图,并相同色系的渐变色。由于一般热力图不具备影响力半径自适应功能,故将其影响力半径系数手动调整与逆向热力图一致,以便更加科学直观对比其可视化效果。实验所用计算机主要配置信息如表2所示。实验程序运行时间情况为:一般热力图方法运行时间约2 s,逆向热力图方法运行时间约6 s。
表2 实验计算机配置信息
Tab. 2 Configuration information of the computer facility in experiment
| 参数 | 信息 |
|---|---|
| 电脑型号 | 联想80WW笔记本电脑 |
| 操作系统 | Windows 10(64位) |
| 处理器 | Core i7-7700HQ @2.80GHz/四核 |
| 主板 | LNVNB161216 |
| 内存 | DDR4/2667MHz/8GB |
| 主硬盘 | 128 GB/固态硬盘 |
| 显卡 | Nvidia GeForce GTX 1050 Ti/4 GB |
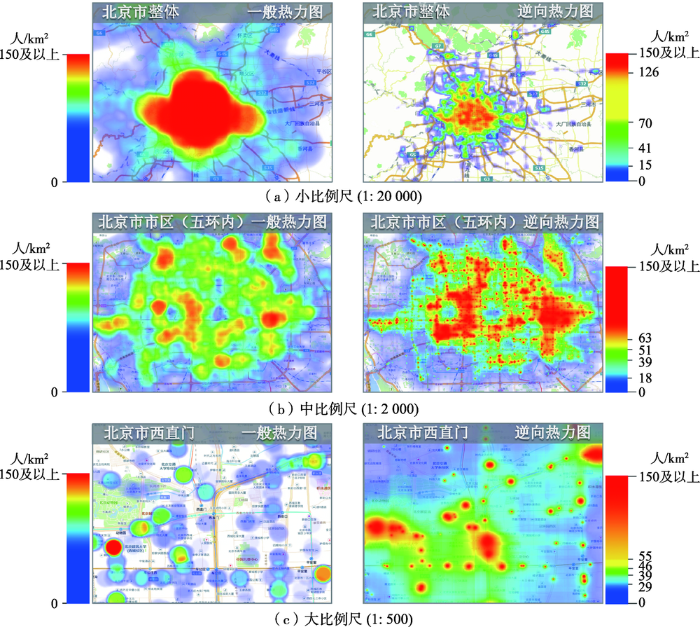
实验结果如图7所示,在不同地图比例尺下比较2种热力图绘制方法:一种是一般的HeatMap绘制方法,另一种是本文的逆向绘制地理热力图方法。小比例尺为1:20 000,中比例尺为1:2000,大比例尺为1:500。小比例尺为截取北京市整体;中比例尺为北京五环以内区域,这片区域为公交客流主要分布区域;大比例尺是西直门附近,西直门附近有公交枢纽、动物园、商业区、学校和火车站,客流分布特征明显。
图7 逆向热力图与一般热力图对比
注:左为一般热力图,右为逆向热力图
Fig. 7 Comparison of reverse and general Heatmaps
由图7可知,北京市中午时段内的主要客流集中在市区,周边郊区分布较稀疏。在小比例尺下,一般的热力图会由于相互遮盖形成中心团状热核,而使用本文方法的逆向热力图数据特征更加清晰;在中等比例尺下,2种方法绘制热力图差别不大,数据特征都比较清晰,而逆向热力图在反映客流分布情况则更精细,层次更加分明;在大比例尺下,一般方法绘制的热力图呈现点状,失去了宏观热力效果,而逆向热力图由于考虑的是地理距离,局部效果依然明显,可以看出动物园、商业区和学校等客流密集区域。
本文提出的逆向热力图绘制方法,可以充分考虑到数据的地理空间分布的实际情况,受地图尺度影响较小,与一般热力图相比更加稳定地表现数据特征,采用最大熵法自动完成热度分级,具有良好的数据可视化效果。由于普通热力图使用了样方法聚类,即便调节影响力半径在小比例尺下依然会出现团状热斑,而逆向热力图方法按照像素粒度计算分析,受尺度影响较小。而且本文提出的逆向热力图方法是根据屏幕像素先计算后绘制,影响力叠加不依赖于渲染器,可以根据不同的需求设置不同的影响力叠加模型,更适用于地理空间POI点分析。
由于本文方法计算成本较高,导致渲染效率偏低,下一步的研究中将继续优化算法,降低计算复杂度,满足大数据可视化的时效性要求,以便此方法的推广应用。
The authors have declared that no competing interests exist.
| [1] |
Visualization of eye gaze data using heat maps [J].
Usability testing is widely used today to determine, among other things, the quality of web site designs. To help the researchers, a number of techniques have been suggested for visualizing the eye tracker data. Using one of the most popular techniques, gaze fixations are plotted in 2-D against the stimulus image in the background. However, there is an alternative visualization technique, based on the heat map paradigm, which offers additional benefits by better separating the different levels of observation intensity. We present a modified version of this technique to facilitate visualizations by allowing the transparency of the heat map to depend on the gaze data itself. In our version, transparency is presented in either the gray scale, or employing some color scheme. The intensity is proportional to the duration of the observation. Thus, longer fixations add more transparency than shorter ones. Conversely, the least observed areas are hidden by a shadow or fog. We also propose three alternative forms for the function of the transparency distribution. One of these is a simple linear relationship, whereas the other two are nonlinear (a sum of linear and sine wave, and a Gaussian). Ill. 7, bibl. 6 (in English; summaries in English, Russian and Lithuanian).
|
| [2] |
地理空间知识服务概论 [J].Geospatial knowledge service: A review [J]. |
| [3] |
一种基于Heat Map的地理标签数据可视化表达的研究 [J].https://doi.org/10.3969/j.issn.1006-7949.2016.06.007 URL [本文引用: 1] 摘要
地理标签数据是指蕴含在网页、照片、微博等信息媒介中的地理空间信息,其表现形式通常是经纬度坐标。通过分析地理标签数据的研究现状,对地理标签数据进行分类,并归纳地理标签数据具有属性数据非结构化、海量信息分布不均、强调位置相对关系等特点。针对其中一个特点,通过对K-means算法进行改进,结合计算机图形学相关知识,利用热力图表达地理标签数据的分布特征。最后,通过与ArcGIS核密度图、散点图进行比较,得出该热力图算法具有表达效果明显、用户体验好等优点。
Research on heat map visualization of geotagged data [J].https://doi.org/10.3969/j.issn.1006-7949.2016.06.007 URL [本文引用: 1] 摘要
地理标签数据是指蕴含在网页、照片、微博等信息媒介中的地理空间信息,其表现形式通常是经纬度坐标。通过分析地理标签数据的研究现状,对地理标签数据进行分类,并归纳地理标签数据具有属性数据非结构化、海量信息分布不均、强调位置相对关系等特点。针对其中一个特点,通过对K-means算法进行改进,结合计算机图形学相关知识,利用热力图表达地理标签数据的分布特征。最后,通过与ArcGIS核密度图、散点图进行比较,得出该热力图算法具有表达效果明显、用户体验好等优点。
|
| [4] |
基于Heatmap的地理对象空间分布热度计算方法 [J].Heatmap geographical mapping spatial distribution calculation method [J]. |
| [5] |
基于百度地图热力图的城市空间结构研究——以上海中心城区为例 [J].Research on urban spatial structure based on baidu heat map: A case study on the central city of shanghai [J]. |
| [6] |
Visualization of eye gaze data using heat maps [J].
Usability testing is widely used today to determine, among other things, the quality of web site designs. To help the researchers, a number of techniques have been suggested for visualizing the eye tracker data. Using one of the most popular techniques, gaze fixations are plotted in 2-D against the stimulus image in the background. However, there is an alternative visualization technique, based on the heat map paradigm, which offers additional benefits by better separating the different levels of observation intensity. We present a modified version of this technique to facilitate visualizations by allowing the transparency of the heat map to depend on the gaze data itself. In our version, transparency is presented in either the gray scale, or employing some color scheme. The intensity is proportional to the duration of the observation. Thus, longer fixations add more transparency than shorter ones. Conversely, the least observed areas are hidden by a shadow or fog. We also propose three alternative forms for the function of the transparency distribution. One of these is a simple linear relationship, whereas the other two are nonlinear (a sum of linear and sine wave, and a Gaussian). Ill. 7, bibl. 6 (in English; summaries in English, Russian and Lithuanian).
|
| [7] |
Informative or Misleading? Heatmaps Deconstructed [J]. |
| [8] |
Visualizing software dynamicities with heat maps [C]. |
| [9] |
InCHlib - interactive cluster heatmap for web applications [J].https://doi.org/10.1186/s13321-014-0044-4 URL PMID: 4173117 [本文引用: 1] 摘要
Background Hierarchical clustering is an exploratory data analysis method that reveals the groups (clusters) of similar objects. The result of the hierarchical clustering is a tree structure called dendrogram that shows the arrangement of individual clusters. To investigate the row/column hierarchical cluster structure of a data matrix, a visualization tool called 'cluster heatmap' is commonly employed. In the cluster heatmap, the data matrix is displayed as a heatmap, a 2- dimensional array in which the colour of each element corresponds to its value. The rows/columns of the matrix are ordered such that similar rows/columns are near each other. The ordering is given by the dendrogram which is displayed on the side of the heatmap. Results We developed InCHlib (Interactive Cluster Heatmap Library), a highly interactive and lightweight JavaScript library for cluster heatmap visualization and exploration. InCHlib enables the user to select individual or clustered heatmap rows, to zoom in and out of clusters or to flexibly modify heatmap appearance. The cluster heatmap can be augmented with additional metadata displayed in a different colour scale. In addition, to further enhance the visualization, the cluster heatmap can be interconnected with external data sources or analysis tools. Data clustering and the preparation of the input file for InCHlib is facilitated by the Python utility script inchlib-clust.Conclusions The cluster heatmap is one of the most popular visualizations of large chemical and biomedical data sets originating, e.g., in high-throughput screening, genomics or transcriptomics experiments. The presented JavaScript library InCHlib is a client-side solution for cluster heatmap exploration. InCHlib can be easily deployed into any modern web application and configured to cooperate with external tools and data sources. Though InCHlib is primarily intended for the analysis of chemical or biological data, it is a versatile tool which application domain is not limited to the life sciences only.
|
| [10] |
Heatmap visualization of population based multi objective algorithms [C]. |
| [11] |
Network density estimation: A GIS approach for analysing point patterns in a network space [J].https://doi.org/10.1111/j.1467-9671.2008.01107.x URL [本文引用: 1] 摘要
Human activities and more generally the phenomena related to human behaviour take place in a network-constrained subset of the geographical space. These phenomena can be expressed as locations having their positions configured by a road network, as address points with street numbers. Although these events are considered as points on a network, point pattern analysis and the techniques implemented in a GIS environment generally consider events as taking place in a uniform space, with distance expressed as Euclidean and over a homogeneous and isotropic space. Network-spatial analysis has developed as a research agenda where the attention is drawn towards point pattern analytical techniques applied to a space constrained by a road network. Little attention has been put on first order properties of a point pattern (i.e. density) in a network space, while mainly second order analysis such as nearest neighbour and K -functions have been implemented for network configurations of the geographical space. In this article, a method for examining clusters of human-related events on a network, called Network Density Estimation (NDE), is implemented using spatial statistical tools and GIS packages. The method is presented and compared to conventional first order spatial analytical techniques such as Kernel Density Estimation (KDE). Network Density Estimation is tested using the locations of a sample of central, urban activities associated with bank and insurance company branches in the central areas of two midsize European cities, Trieste (Italy) and Swindon (UK).
|
| [12] |
顾及手机基站分布的核密度估计城市人群时空停留分布 [J].https://doi.org/10.13203/j.whugis20150646 URL [本文引用: 1] 摘要
为了减小人群在连续空间上停留分布的估计误差,结合手机基站的空间的分布特点,根据基站间的邻近性来计算带宽控制参数,使搜索带宽随着基站的分布而变化;利用最小二乘交叉验证和对数概率两种方法来评价其估计效果,结果表明变化带宽比固定带宽的核密度估计效果更优。以深圳市手机位置数据为例,利用改进方法估计了几个典型时段城市人群停留的时空分布差异,反映了城市人群对城市不同区域的使用情况及其随时间变化情况。
Analyzing space-time variation of urban human stay using kernel density estimation by considering spatial distribution of mobile phone towers [J].https://doi.org/10.13203/j.whugis20150646 URL [本文引用: 1] 摘要
为了减小人群在连续空间上停留分布的估计误差,结合手机基站的空间的分布特点,根据基站间的邻近性来计算带宽控制参数,使搜索带宽随着基站的分布而变化;利用最小二乘交叉验证和对数概率两种方法来评价其估计效果,结果表明变化带宽比固定带宽的核密度估计效果更优。以深圳市手机位置数据为例,利用改进方法估计了几个典型时段城市人群停留的时空分布差异,反映了城市人群对城市不同区域的使用情况及其随时间变化情况。
|
| [13] |
核密度估计法支持下的网络空间POI点可视化与分析 [J].https://doi.org/10.11947/j.AGCS.2015.20130538 URL Magsci [本文引用: 1] 摘要
<p>城市空间POI点的分布模式、分布密度在基础设施规划、城市空间分析中具有重要意义, 表达该特征的核密度法(kernel density estimation)由于顾及了地理学第一定律的区位影响,比其他密度表达方法(如样方密度、基于Voronoi图密度)占优.然而,传统的核密度计算方法往往基于二维延展的欧氏空间,忽略了城市网络空间中设施点的服务功能及相互联系发生于网络路径距离而非欧氏距离的事实.本研究针对该缺陷,给出了网络空间核密度计算模型,分析了核密度方法在置入网络结构中受多种约束条件的扩展模式,讨论了衰减阈值及高度极值对核密度特征表达的影响.通过实际多种POI点分布模式(随机型、稀疏型、区域密集型、线状密集型)下的核密度分析试验,讨论了POI基础设施在城市区域中的分布特征、影响因素、服务功能.</p>
The visualization and analysis of POI features under network space supported by kernel density estimation [J].https://doi.org/10.11947/j.AGCS.2015.20130538 URL Magsci [本文引用: 1] 摘要
<p>城市空间POI点的分布模式、分布密度在基础设施规划、城市空间分析中具有重要意义, 表达该特征的核密度法(kernel density estimation)由于顾及了地理学第一定律的区位影响,比其他密度表达方法(如样方密度、基于Voronoi图密度)占优.然而,传统的核密度计算方法往往基于二维延展的欧氏空间,忽略了城市网络空间中设施点的服务功能及相互联系发生于网络路径距离而非欧氏距离的事实.本研究针对该缺陷,给出了网络空间核密度计算模型,分析了核密度方法在置入网络结构中受多种约束条件的扩展模式,讨论了衰减阈值及高度极值对核密度特征表达的影响.通过实际多种POI点分布模式(随机型、稀疏型、区域密集型、线状密集型)下的核密度分析试验,讨论了POI基础设施在城市区域中的分布特征、影响因素、服务功能.</p>
|
| [14] |
一种基于密度的K-means算法研究 [J].
针对传统K-means算法必须事先确定聚类数目以及对初始聚类中心的选取比较敏感的缺陷,采用基于密度的思想,通过设定Eps邻域以及Eps邻域内至少包含的对象数minpts来排除孤立点,并将不重复的核心点作为初始聚类中心;采用类内距离和类间距离的比值作为准则评价函数,将准则函数取得最小值时的聚类数作为最佳聚类数,这些改进有效地克服了K-means算法的不足。最后通过几个实例介绍了改进后算法的具体应用,实例表明改进后的算法比原算法有更高的聚类准确性,更能实现类内紧密类间远离的聚类效果。
Research on K-means algorithm based on density [J].
针对传统K-means算法必须事先确定聚类数目以及对初始聚类中心的选取比较敏感的缺陷,采用基于密度的思想,通过设定Eps邻域以及Eps邻域内至少包含的对象数minpts来排除孤立点,并将不重复的核心点作为初始聚类中心;采用类内距离和类间距离的比值作为准则评价函数,将准则函数取得最小值时的聚类数作为最佳聚类数,这些改进有效地克服了K-means算法的不足。最后通过几个实例介绍了改进后算法的具体应用,实例表明改进后的算法比原算法有更高的聚类准确性,更能实现类内紧密类间远离的聚类效果。
|
| [15] |
基于四叉树网格的快速层次聚类热图可视化研究 [D].Research on quadtree grid based fast hierarchical clustering heatmap visualization [D]. |
| [16] |
Huub V D W, Van W J J. Visualization of vessel movements [J].https://doi.org/10.1111/cgf.2009.28.issue-3 URL [本文引用: 1] |
| [17] |
SVG essentials, 2nd edition [M]. |
| [18] |
Kapur多级分割的阈值相关性及其快速实现算法 [J].https://doi.org/10.3969/j.issn.1003-9775.2014.11.018 URL [本文引用: 1] 摘要
基于Kapur算法所产生的多级阈值之间是相互联系的性质,提出了Kapur多级分割的快速实现算法。该算法利用一个给定的初始阈值,采用迭代的步骤分别计算多级阈值;当满足收敛条件时,得到多级分割的阈值。实验结果表明,无论是计算时间还是计算结果的准确性,文中算法都超过了许多已有的算法;且该算法计算相当简单,对内存要求也较低,能够满足实时计算的要求。
Fast implementation of Kapur's method for multilevel thresholding based on dependence of thresholds [J].https://doi.org/10.3969/j.issn.1003-9775.2014.11.018 URL [本文引用: 1] 摘要
基于Kapur算法所产生的多级阈值之间是相互联系的性质,提出了Kapur多级分割的快速实现算法。该算法利用一个给定的初始阈值,采用迭代的步骤分别计算多级阈值;当满足收敛条件时,得到多级分割的阈值。实验结果表明,无论是计算时间还是计算结果的准确性,文中算法都超过了许多已有的算法;且该算法计算相当简单,对内存要求也较低,能够满足实时计算的要求。
|

/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}