1 引言
导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] 。大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] 。内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据。对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持。目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等。
利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注。针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] 。此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] 。城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息。有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点。例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等。
从城市全局角度研究热点区域的分布和关联性问题,获取在居民日常出行活动中具有紧密关联性的热点区域空间分布特征,将为优化道路交通建设,减少拥堵,以及更合理的城市功能区域规划,智慧城市建设等提供决策支持。而目前这方面的研究主要着眼于热点区域的发现,针对城市热点区域之间关联性的研究仍然较少。因此,本文提出一种利用导航大数据的城市热点区域关联性挖掘方法。在提取出城市热点区域的基础上对城市进行空间离散化,通过基于谱聚类算法和蚁群算法的方法进一步挖掘城市热点区域之间的关联性,并将该方法应用到实际的出租车轨迹数据。
2 研究区概况与数据源
2.1 研究区概况
本文以上海市市区(崇明岛以外)为研究区。上海市是直辖市,位于中国东部地区长江出海口,是中国最大的工业城市,制造业发达,同时也是经济、金融、贸易和科技创新中心。上海作为中国的大都市之一,其居民日常出行活动特征及城市规划建设现状具有典型性,因此本文选取上海市为研究区进行实例分析。研究区共涉及除崇明区以外的上海市15个市辖区,包括位于市中心的黄浦区、长宁区和浦东新区等8个市辖区,以及位于市中心边缘的闵行区、松江区和青浦区等7个市辖区。
2.2 数据源
乘坐出租车出行是重要的居民出行方式之一,相比公交地铁等方式,出租车为居民出行提供定制化的服务,没有固定的载客路线,能较好地反映居民出行特点。出租车轨迹数据还具有分布广、易收集的特点,因此本文选取出租车轨迹数据作为居民出行导航数据。数据集包含上海市2007年2月20日全天24 h的出租车轨迹数据[19 ] ,采样间隔为1 min,坐标精度约20 m。出租车轨迹数据由离散的多维数据点构成,包含车辆信息、时间戳、经纬度、速度以及载客状态等。针对数据中的粗差以及定位精度问题,首先对数据进行了清洗,并将轨迹数据与道路网进行了匹配,最终得到有用的干净数据中涵盖了4316辆出租车。根据数据中的载客状态提取轨迹中的上下客点:载客状态从“0”变为“1”表示上客点,载客状态从“1”变为“0”表示下客点。为验证本文数据的有效性,首先对上下客点的时空分布特性以及载客行程距离分布特性等进行分析。
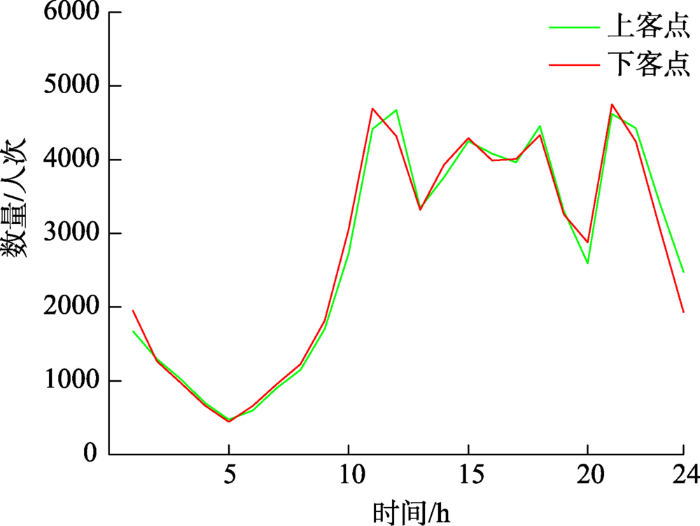
上下客点数量的时间分布如图1 所示,上午 9时到晚上23时左右是居民出行的活跃时段,同时,在上午11时和晚上21时左右分别出现了一个驼峰,代表居民日常活动中的出行和返程高峰时段。由于出租车数据选自休息日,早上出行和晚上返程的高峰相比工作日有一定延迟,该分布与文献[20 ]中的结果相吻合。
图1 2007年2月20日全天上海市出租车轨迹上下客点数量时间分布
Fig. 1 Temporal distribution of pick-up and drop-off points in the taxi trajectories of Shanghai on February 20, 2007
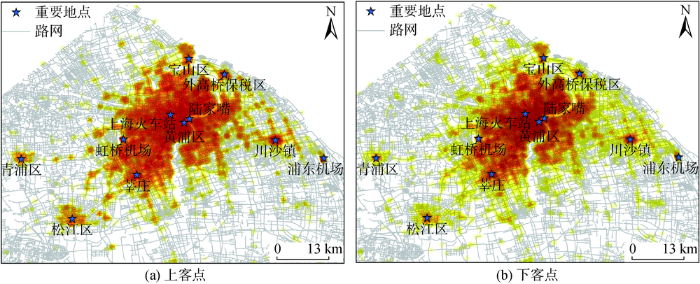
上下客点的空间分布如图2 所示,颜色越深,上下客点越密集。上下客点集中分布在以黄浦区和陆家嘴为中心向外辐射的市中心。在主要的交通枢纽点,如虹桥机场和浦东机场,上下客点密度较大。此外,一些远离市中心的行政区划中心如城市西侧的莘庄、松江区和青浦区,城市东侧的川沙镇,以及东北角的宝山和外高桥保税区等也是上下客点密集的区域。
图2 2007年2月20日全天上海市出租车轨迹上下客点密度空间分布热图
Fig. 2 Spatial distribution of pick-up and drop-off points in the taxi trajectories of Shanghai on February 20, 2007
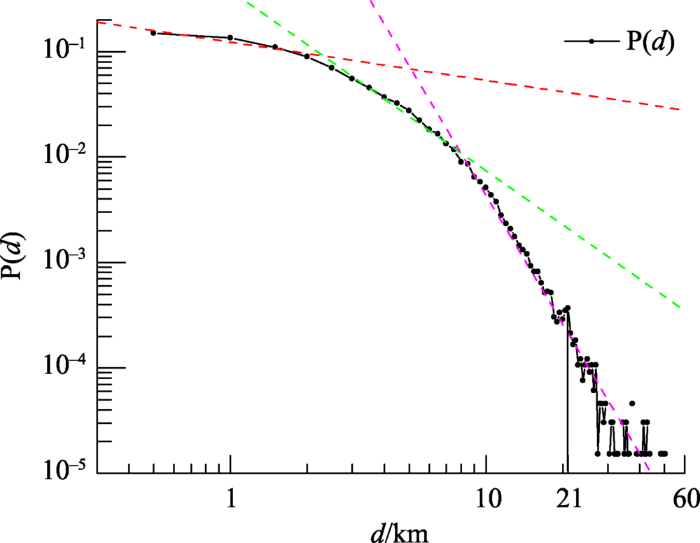
居民乘坐出租车出行次数关于行程距离的分布在不同的城市中具有不同的特征,该分布是理解出租车轨迹数据的重要统计性质。如图3 所示,通过对数坐标系可以看出,行程数量随行程距离的分布P(d)服从指数逐渐减小的幂律分布,与文献[15 ]中的论述一致。出租车载客行程主要集中在短途范围内,行程数量随着距离的增加而减小,长距离行程的数量急剧下降。值得注意的是,在距离为21 km左右处出现了一个波峰,由此可推断该距离为市区到浦东机场或其他城郊热点区域的行程距离。
图3 2007年2月20日全天上海市出租车行程直线距离的对数分布
Fig. 3 Log-log plot of the taxi trip distance distribution of Shanghai on February 20, 2007
3 研究方法
居民出行行程的起点和终点(Origin-Destination,OD点)是出行轨迹中最重要的特征点,主要体现2个方面:① OD点密集的区域必定承载了大量的居民活动,可被视为城市中的热点区域;② 若存在大量的行程往返于不同的特定区域,那么这些区域之间潜在的紧密联系也将由居民出行活动反映。因此,本文提出通过挖掘居民出行导航数据中的OD点分布信息,揭示城市热点区域之间存在的关联性。首先利用聚类算法对OD点坐标进行空间聚类,得到热点区域的分布情况,并依据该分布对OD点密集的城市热点区域进行离散化;再根据行程次数定义区域之间的关联性,通过基于谱聚类算法和蚁群算法的方法,挖掘城市中具有紧密关联性的热点区域的空间分布特征。
3.1 热点区域挖掘与离散化
居民出行活动遍布城市全域,但OD点密集,居民活动频繁的热点区域才更具代表性,因此,需要首先挖掘出城市中的热点区域。城市热点区域挖掘中常用的方法是对坐标点进行聚类分析[10 ,21 ] 。常用的聚类算法主要包含4类:层次聚类、划分式聚类、基于密度和基于网格聚类。本文以OD点坐标之间的欧氏距离为相似性度量,利用基于密度的DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法[22 ] 进行聚类挖掘热点区域。该算法在不用事先确定聚类个数的情况下能够较好地处理全城分布不均匀、不规则的OD点数据。DBSCAN算法有2个重要的参数:eps和MinPts,其中eps表示样本点的邻域距离阈值,MinPts表示位于样本邻域内其他样本点的数量阈值。采用k-distance方法[22 ] 确定聚类参数,针对城郊和市中心密度差别较大的情况,通过调整参数分别对城市全域和市中心进行2次聚类,相比固定参数的传统方法能够更好地捕捉不同尺度的热点区域分布。
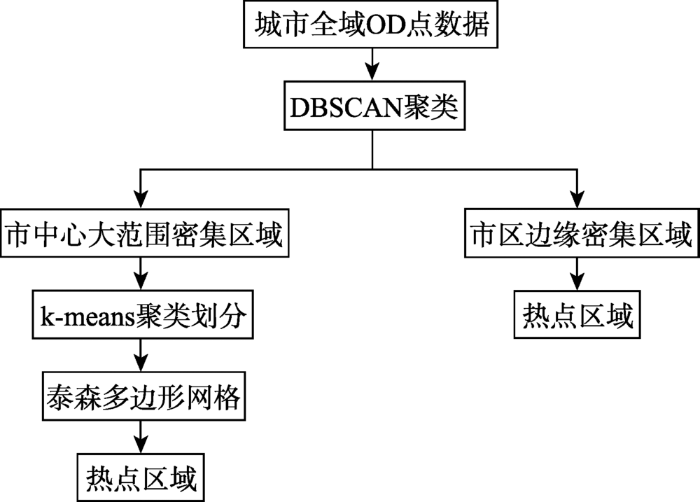
为了分析区域之间的关联性,需要将城市热点区域进行离散化。常用的区域离散化方法包括:均匀网格法,依照道路划分的方法,按照轨迹点密度划分以及以兴趣点为参照的多边形划分等几类[1 ] 。本文将根据OD点的分布,结合密度划分和多边形划分的方法进行区域离散化。热点区域离散化方法流程如图4 所示。针对市中心OD点的密度远大于城市边缘地区,且市中心内部点密度相对均匀的情况,首先利用DBSCAN算法过滤城市边缘的稀疏区域,并将城市边缘存在的少数密集区域作为单独网格。而对OD点密集的市中心区域再利用基于距离的k-means算法单独进行聚类,确定每个聚类的中心点。以各中心点为参照点生成泰森多边形(也称Voronoi多边形)[23 ] ,使得多边形内的所有样本点到该多边形内的参照点的距离比到其他任何一个参照点距离更短。这种城市区域离散化方法相比其他方法能更加准确地识别OD点密集的热点区域,同时基于OD点之间距离的划分策略也使得每个网格能够很好地保留点分布的原始特征。
图4 城市热点区域挖掘与离散化方法技术流程
Fig. 4 Technical flowchart of urban hotspots detection and discretization methodology
3.2 热点区域关联性挖掘
居民出行产生的导航数据与城市热点区域关联性以及城市环境建设之间的关系可由图5 表达。热点区域的空间分布和区域之间的关联性由客观的城市环境建设现状以及主观的居民出行行为共同决定。例如,某大学的2个校区位于不同的区域,使得2个区域之间的往返行程较为频繁,造成2个区域之间较强的关联性。因此,研究居民出行产生的导航数据不仅能够揭示城市热点区域之间的关联性,还能进一步分析土地资源利用及道路交通建设情况等城市环境的潜在信息,将对城市建设有重要意义。
图5 导航数据与热点区域关联性以及城市环境建设之间的关系
Fig. 5 Relationships among navigation data, regional association, and urban environment
3.2.1 相关定义
著名的“购物篮分析”指出:当物体 i j i j i j [24 ] 。同理,在城市中,如果起点位于区域 i j j i i j
离散化的热点区域网格作为关联性分析所利用的对象,可抽象为无向权重的关联图 G ( v , e ) v e e i j N ij
N ij = N { O ∈ i ⋂ D ∈ j } + N { O ∈ j ⋂ D ∈ i }
式中: O D N m N ij i j m )构成的 m × m V
V = N 11 ⋯ ⋯ N 1 j ⋯ ⋮ ⋮ N i 1 N ij ⋯ ⋮ ⋮ m × m
式中: i j m 表示各区域编号。由定义可知 N ij = N ji V G ( v , e ) N ij
将矩阵 V N ' ij i j m )构成的标准化关联度矩阵 V '
N ' ij = N ij - min ( N ij ) max ( N ij ) - min ( N ij )
定义区域节点 i j
s ij = 1 N ' ij
节点 i j s ij
导航轨迹的OD点架起了不同区域相互联系的桥梁,因此,图 G ( v , e ) V ' V '
3.2.2 谱聚类算法
谱聚类算法是数据挖掘领域中常用的聚类算法之一,建立在图论的谱图理论基础上,是一种点对聚类算法[25 ] 。其基本原理为:将研究对象即离散化后的热点区域抽象为关联图 G ( v , e ) [26 ] 。聚类准则将对结果产生至关重要的影响,本文采用 Ncut [27 ] ,使目标函数 Ncut
Ncut ( A 1 , A 2 , … , A k ) = 1 2 ∑ i = 1 k w ( A i , A ̅ i ) vol ( A i )
式中: k w ( A i , A ̅ i ) A i vol ( A i ) A i
谱聚类算法利用谱图理论来研究上述的相邻矩阵 V ' Ncut [25 ] 。图 G ( v , e )
L = D - V '
式中: D d ii = ∑ j N ' ij L ( norm )
L ( norm ) = D - 1 L D - 1
3.2.3 蚁群算法
蚁群算法是一种仿生优化算法。其基本原理为:一群蚂蚁在觅食时,会选择食源和蚁巢之间不同的路径,并留下随时间挥发的信息素,一条路径走过的蚂蚁越多,信息素浓度就越大,而蚂蚁会以更大概率选择信息素浓度较大且距离较短的路径。最终这种“正反馈”机制能够使蚂蚁找到一条最优(短)路径[28 ] 。将蚁群算法应用于谱聚类算法划分出的子图中求解基于关联度距离的最优路径,可进一步研究本身已具有紧密关联性的区域之间更深层次的内在联系。
将 n r i j i j η ij s ij i j
η ij = 0 i = j N ' ij i ≠ j
由 p h ij η ij
p ij = p h ij ( t ) α × η ij β ∑ j∈allowed p h ij ( t ) α × η ij β j ∈ allowed 0 j ∉ allowed
式中: α β allowed 表示未访问过的节点。
为了避免结果陷入局部最优解,采用轮盘赌方法作为蚂蚁转移策略,使迭代过程具有随机性[29 ] 。每次迭代后信息素的更新包括2个部分,信息素的自然挥发以及蚂蚁走过留下的信息素增量。
p h ij ( t + 1 ) = ρ × p h ij ( t ) + Δ p h ij ( t ) 蚂蚁经过 ρ × p h ij ( t ) 蚂蚁未经过
式中: ρ ∈ ( 0,1 ) Δ p h ij ( t )
Δ p h ij ( t ) = Q L i , j 位于蚂蚁路径中 0 i , j 不位于蚂蚁路径中
式中: Q L α = 1 , β = 5 , ρ = 0.5
在由多个相互关联的区域节点构成的子图 A i
4 结果及分析
4.1 热点区域分布
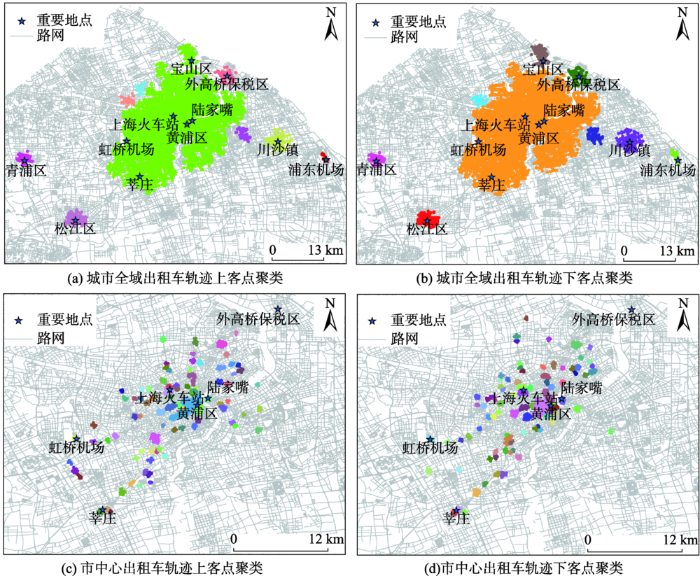
以出租车轨迹数据中的上下客点为居民出行的OD点进行研究,经过两次DBSCAN聚类,城市中的热点区域分布如图6 所示。图6 (a)和图6 (b)展示了对城市全域进行聚类的结果,市中心被识别为范围较大的热点区域;其他热点区域包括浦东国际机场,川沙镇,松江区,青浦区以及外高桥保税区等。图6 (c)和图6 (d)是对市中心上下客点密集地区进行第二次聚类的结果,上下客点集中分布在黄浦江西岸中心城区以及黄浦江东岸的陆家嘴金融中心,呈现了一条西南-东北走向的热点带,热点区域主要出现在交叉路口,各个商圈,以及机场、火车站等交通枢纽附近。
图6 出租车轨迹上下客点集中的热点区域
Fig. 6 Hotspot regions with high density of pick-up and drop-off points in the taxi trajectories
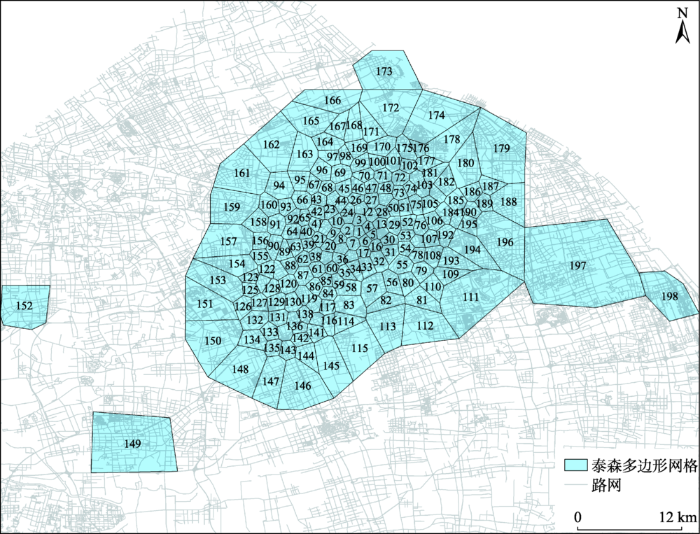
在得到热点区域分布的基础上,根据上下客点的分布特征对城市进行自动的泰森多边形划分,点越密集的区域划分网格越小。城市区域离散化结果如图7 所示,上下客点密集的热点区域被划分为198个网格,分别标注为区域1-198。
图7 泰森多边形区域划分
Fig. 7 Spatial discretization of Theiessen polygons
4.2 热点区域关联性分析
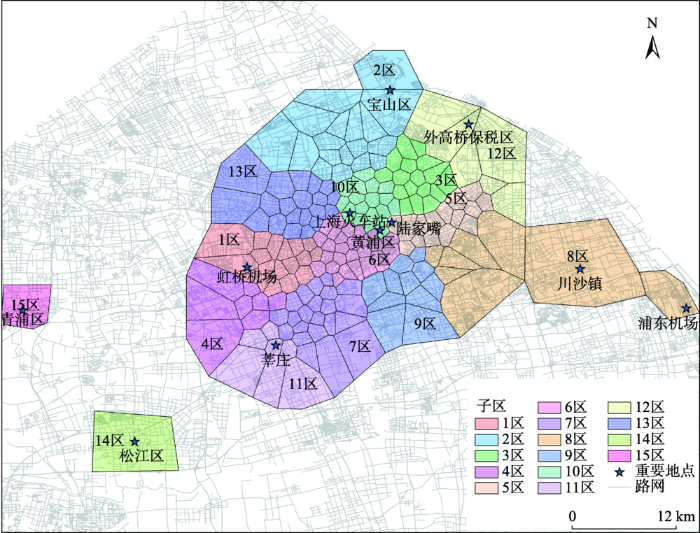
利用基于谱聚类的方法对上述网格进行聚类,全部热点区域被划分为15个子区,揭示了区域关联性的分布情况如图8 所示。大量的出租车都往返于子区内部的各个区域,属于同一子区的各区域之间存在较强关联性;而不同子区之间的载客行程次数则较少,因此属于不同子区的区域之间关联性相对较弱。位于城市西侧的青浦区和松江区2个热点区域则由于距离等原因,同其他热点区域之间关联性较弱,形成了单独的子区。
图8 具有较强关联性的区域划分结果
Fig. 8 Result of grouped regions with strong association
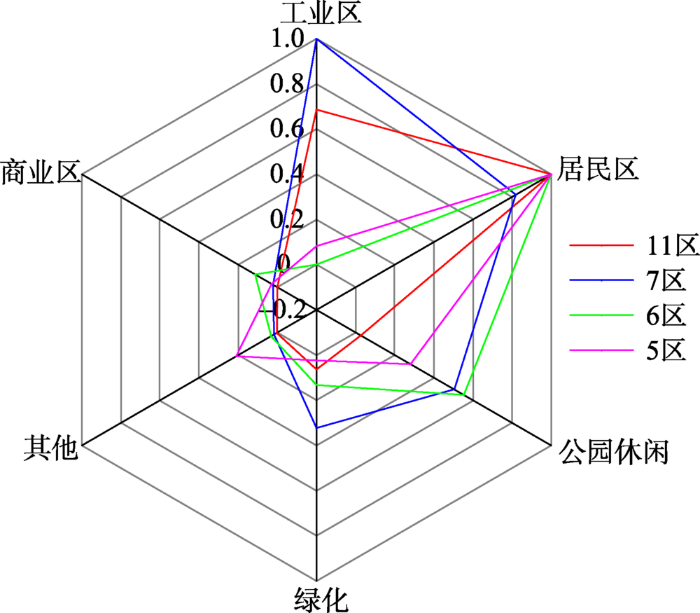
以位于市中心的5区和6区以及位于市区边缘的7区和11区为例。4个子区内部的土地资源利用比例特征如图9 所示。黄浦江和内环高架路所包围的区域构成了6区,商业区集中,许多出租车行程都往返于该子图内部的各个商圈。5区主要包含浦东地区的居民小区,且配备了公园等完善的休闲基础设施,满足小区居民的日常活动需求,因此形成了一片紧密关联的区域。位于市区西南角的7区和11区相邻,莘庄作为二者的相邻点,是闵行区的经济和行政中心,同时也是重要的交通枢纽。莘庄立交的东北方向是连接莘庄与市中心的地带,大量的出租车行程往返于这些区域,从而构成了子区7;而位于莘庄立交西侧的11区内部的区域则包含了闵行居民区和莘庄工业园区。该结果反映了居民出行时往返于各热点区域间不同的频繁程度,揭示了城市中具有紧密关联性的热点区域的空间分布特征。结合土地资源利用情况,造成该分布特征的原因也得到进一步分析。
图9 5区、6区、7区和11区土地利用分布特征
Fig. 9 Land use characteristics of sub-graphs 5, 6, 7, 11
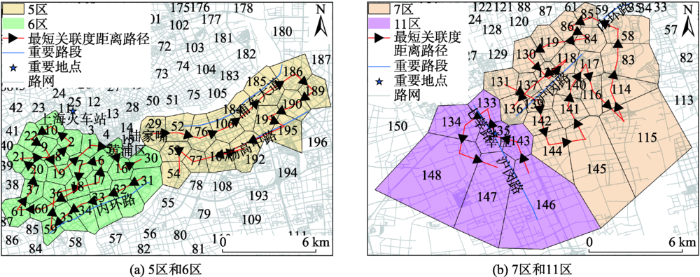
以子区内部各热点区域为节点,利用蚁群算法得到一条基于关联度距离的最短路径。以5区和6区,7区和11区为例,4个子区内部的最短关联度距离路径如图10 所示。该路径由各个区域节点按照关联性最强的顺序构成,即以该路径的顺序沟通各热点区域,往返于相邻节点之间的行程次数最多。如图10 (a)所示,5区内部的最短关联度距离路径的方向与浦东大道和杨高中路一致,将浦东地区的居民区和各类休闲区域紧密联系在一起;6区内部最短关联度距离路径中,区域31-32-33-34-35-59依次相邻,彼此间关联性紧密,与横贯这几个区域的内环路是承载大量交通流的重要路段的实际情况相符。图10 (b)中,7区内部区域136-137-118-138在最短关联性距离路径上相邻,形成沟通闵行区和市中心的重要通道;而11区内部的区域节点中,146-143-135-133依次相邻,与主干道路沪闵路和七莘路方向吻合,沟通了该子图范围内主要的居民区和工业园区。以上结果揭示了各区域节点形成关联性较强的子图的内在机制及热点区域之间的居民流通规律。
图10 5区、6区、7区和11区最短关联度距离路径
Fig. 10 Optimal paths with the shortest association distance within sub-graphs 5,6,7,11
5 结语
本文提出了利用导航大数据挖掘城市热点区域分布和关联性特征的方法,并以上海市出租车轨迹数据为基础进行了实例分析:① 出租车上下客点的时空分布反映了上海市居民出行的总体特征; ② 通过空间聚类挖掘上海市居民出行频繁的热点区域,发现热点区域主要集中于各个商圈以及交通枢纽,市中心的热点分布较为密集;③ 基于热点区域之间的行程次数定义了区域间的关联度和关联度距离,热点区域关联性挖掘方法将上海的热点区域划分为15个内部紧密关联的子区,揭示了城市中具有紧密关联性的热点区域的空间分布特征,并结合上海的土地资源利用和道路交通建设情况进一步分析了造成这一特征的原因。分析结果能够为合理的城市功能区域规划和土地资源利用,以及道路交通的建设等提供有效的决策支持和参考信息,具有重要现实意义。
与现有研究相比,本文更着重于探究形成热点区域关联性的内在机制,所提出的城市热点区域关联性挖掘方法充分考虑并利用热点区域关联性与居民出行行为之间的关系。谱聚类和蚁群算法与导航大数据相结合,创新性地将关联性分析转化为图的最优划分问题以及最优路径的求解问题。在本文的基础上还存在进一步研究的空间。今后将融合丰富的多源异构数据如手机数据,社交网络数据等进行研究,并加入时间维度信息,来研究热点区域关联性的时空演化特征。
The authors have declared that no competing interests exist.
参考文献
文献选项
[1]
郭迟 ,刘经南 ,方媛 ,等 .位置大数据的价值提取与协同挖掘方法
[J].软件学报 ,2014 ,25 (4 ):713 -730 .
[本文引用: 2]
[ Guo C Liu J N Fang Y et al .Value extraction and collaborative mining methods for location big data
[J]. Journal of Software , 2014 ,25 (4 ):713 -730 . ]
[本文引用: 2]
[2]
陈明剑 ,李广云 .北斗导航大数据建设与思考
[J].卫星应用 ,2017 (2 ):56 -59 .
[本文引用: 1]
[ Chen M Li G Construction and thinking about Beidou navigation big data
[J]. Satellite Application , 2017 (2 ):56 -59 . ]
[本文引用: 1]
[3]
陈卓然 ,黄翀 ,刘高焕 ,等 .基于出租车GPS数据的居民就医时空特征分析
[J].地球信息科学学报 ,2018 ,20 (8 ):1111 -1122 .
[本文引用: 1]
[ Chen Z R Huang C Liu G H et al .Analysis of spatial-temporal characteristics of resident travel for hospitals based on taxi GPS data
[J]. Journal of Geo-information Science , 2018 ,20 (8 ):1111 -1122 . ]
[本文引用: 1]
[4]
王永程 ,褚衍杰 .基于谱聚类的用户关联关系挖掘
[J].电讯技术 ,2016 ,56 (1 ):32 -37 .
[本文引用: 1]
[ Wang Y C Chu Y J et al .User association mining based on spectral clustering
[J]. Telecommunication Engineering , 2016 ,56 (1 ):32 -37 . ]
[本文引用: 1]
[5]
Dabiri S Heaslip K Inferring transportation modes from GPS trajectories using a convolutional neural network
[J]. Transportation Research Part C: Emerging Technologies , 2018 ,86 :360 -371 .
[本文引用: 1]
[6]
刘菊 ,许珺 ,蔡玲 ,等 .基于出租车用户出行的功能区识别
[J].地球信息科学学报 ,2018 ,20 (11 ):1550 -1561 .
[本文引用: 1]
[ Liu J Xu J Cai L et al .Identifying functional regions based on the spatio-temporal pattern of taxi trajectories
[J]. Journal of Geo-information Science , 2018 ,20 (11 ):1550 -1561 . ]
[本文引用: 1]
[7]
杨伟 ,艾廷华 .众源车辆轨迹加油停留行为探测与加油站点提取
[J].测绘学报 ,2017 ,46 (7 ):918 -927 .
[本文引用: 1]
[ Yang W Ai T H Refueling stop activity detection and gas station extraction using crowdsourcing vehicle trajectory data
[J]. Acta Geodaetica et Cartographica Sinica , 2017 ,46 (7 ):918 -927 . ]
[本文引用: 1]
[8]
Liu S Y Liu Y H Ni L et al .Detecting crowdedness spot in city transportation
[J]. IEEE Transactions on Vehicular Technology , 2013 ,62 (4 ):1527 -1539 .
[本文引用: 1]
[9]
孙涛 ,吴琳 ,王飞 ,等 .大规模航运数据下“一带一路”国家和地区贸易网络分析
[J].地球信息科学学报 ,2018 ,20 (5 ):593 -601 .
[本文引用: 1]
[ Sun T Wu L Wang F et al .Analysis on the trade networks of the Belt and Road countries and regions under large scale shipping data
[J]. Journal of Geo-information Science , 2018 ,20 (5 ):593 -601 . ]
[本文引用: 1]
[10]
Chang H W Tai Y C Hsu Y J Context-aware taxi demand hotspots prediction
[J]. International Journal of Business Intelligence & Data Mining , 2009 ,5 (1 ):3 -18 .
[本文引用: 2]
[11]
Pan G Qi G D Wu Z H et al .Land-use classification using taxi GPS traces
[J]. IEEE Transactions on Intelligent Transportation Systems , 2013 ,14 (1 ):113 -123 .
[本文引用: 1]
[12]
Liu Y Wang F H Xiao Y et al .Urban land uses and traffic ‘source-sink areas': Evidence from GPS-enabled taxi data in Shanghai
[J]. Landscape & Urban Planning , 2012 ,106 (1 ):73 -87 .
[本文引用: 1]
[13]
Zhuang C Y Yuan N J Song R H et al .Understanding people lifestyles: Construction of urban movement knowledge graph from GPS trajectory
[C]. Melbourne: Proceedings of 26th International Joint Conference on Artificial Intelligence , 2017 :3616 -3623 .
[本文引用: 1]
[14]
Newman M E Girvan M Finding and evaluating community structure in networks
[J]. Physical Review E Statistical Nonlinear & Soft Matter Physics , 2004 ,69 (2 ):026113 .
[本文引用: 1]
[15]
Liu X Gong L Gong Y X et al .Revealing travel patterns and city structure with taxi trip data
[J]. Journal of Transport Geography , 2015 ,43 :78 -90 .
[本文引用: 2]
[16]
Xiao L Z Xu W T Liu J X Detecting urban dynamics with taxi trip data for evaluation and optimizing of spatial planning: The example of Xiamen city, China
[J]. International Review for Spatial Planning and Sustainable Development , 2016 ,4 (3 ):14 -26 .
[本文引用: 1]
[17]
李勇 . 基于出租车GPS数据的城市交通拥堵识别和关联性分析
[D].哈尔滨:哈尔滨工业大学 ,2016 .
[本文引用: 1]
[ Li Y Congestion identification and correlation analysis on urban traffic based on taxi GPS data
[D]. Haerbin: Harbin Institute of Technology , 2016 . ]
[本文引用: 1]
[18]
陈泽东 ,谯博文 ,张晶 .基于居民出行特征的北京城市功能区识别与空间交互研究
[J].地球信息科学学报 ,2018 ,20 (3 ):291 -301 .
[本文引用: 1]
[ Chen Z D Qiao B W Zhang J Identification and spatial interaction of urban functional regions in Beijing based on the characteristics of residents' traveling
[J]. Journal of Geo-information Science , 2018 ,20 (3 ):291 -301 . ]
[本文引用: 1]
[19]
https://www.cse.ust.hk/scrg/ ,2018 .8 .15 .
[本文引用: 1]
[20]
Liu Y Kang C G Gao S et al .Understanding intra-urban trip patterns from taxi trajectory data
[J]. Journal of Geographical Systems , 2012 ,14 (4 ):463 -483 .
[本文引用: 1]
[21]
Khetarpaul S Chauhan R Gupta S K et al .Mining GPS data to determine interesting locations
[C]. Hyderabad: Proceedings of International Workshop on Information Integration on the Web: in Conjunction with WWW. ACM , 2011 :1 -6 .
[本文引用: 1]
[22]
Liu P Zhou D Wu N J VDBSCAN: Varied density based spatial clustering of applications with noise
[C]. Chengdu: International Conference on Service Systems and Service Management, IEEE , 2007 :1 -4 .
[本文引用: 2]
[23]
信睿 ,艾廷华 ,杨伟 ,等 .顾及出租车OD点分布密度的空间Voronoi剖分算法及OD流可视化分析
[J].地球信息科学学报 ,2015 ,17 (10 ):1187 -1195 .
https://doi.org/10.3724/SP.J.1047.2015.01187
Magsci
[本文引用: 1]
摘要
为对城市各区域出租车OD轨迹流进行可视化分析,需对城市作空间剖分处理,以产生研究所需的子区域。传统的欧氏距离空间剖分方法,在空间上进行硬性切割不能有效地顾及城市人、物的时空流动模式,因此,本文提出了一种空间约束条件下,顾及出租车OD点分布密度的网络Voronoi剖分方法。首先,将道路网的边细分成线性单元,然后,设定空间约束以产生合适的发生元,让各发生元在路网上以线性单元为单位扩散步长,以不同的速度向周围联通道路进行扩散,最终将城市空间划分成一系列与出租车OD点分布密度相适应的空间子区域。利用OD流可视化理论与技术,基于划分的城市子区域分析出租车在这些区域的时空流动,并结合图论知识探究城市空间OD流拓扑图结构的变化,分析不同划分区域出租车流动模式。最后,通过北京地区一天的出租车轨迹数据,对本文提出的算法及分析方法进行了实验。
[ Xin R Ai T H Yang W et al .A new network Voronoi diagram considering the OD point density of taxi and visual analysis of OD flow
[J]. Journal of Geo-information Science , 2015 ,17 (10 ):1187 -1195 . ]
https://doi.org/10.3724/SP.J.1047.2015.01187
Magsci
[本文引用: 1]
摘要
为对城市各区域出租车OD轨迹流进行可视化分析,需对城市作空间剖分处理,以产生研究所需的子区域。传统的欧氏距离空间剖分方法,在空间上进行硬性切割不能有效地顾及城市人、物的时空流动模式,因此,本文提出了一种空间约束条件下,顾及出租车OD点分布密度的网络Voronoi剖分方法。首先,将道路网的边细分成线性单元,然后,设定空间约束以产生合适的发生元,让各发生元在路网上以线性单元为单位扩散步长,以不同的速度向周围联通道路进行扩散,最终将城市空间划分成一系列与出租车OD点分布密度相适应的空间子区域。利用OD流可视化理论与技术,基于划分的城市子区域分析出租车在这些区域的时空流动,并结合图论知识探究城市空间OD流拓扑图结构的变化,分析不同划分区域出租车流动模式。最后,通过北京地区一天的出租车轨迹数据,对本文提出的算法及分析方法进行了实验。
[24]
Han J W Kamber M Data mining: Concepts and techniques
[J]. Data Mining Concepts Models Methods & Algorithms Second Edition , 2011 ,5 (4 ):1 -18 .
[本文引用: 1]
[25]
蔡晓妍 ,戴冠中 ,杨黎斌 .谱聚类算法综述
[J].计算机科学 ,2008 ,35 (7 ):14 -18 .
[本文引用: 2]
[ Cai X Y Dai G Z Yang L B Survey on spectral clustering algorithms
[J]. Computer Science , 2008 ,35 (7 ):14 -18 . ]
[本文引用: 2]
[26]
Luxburg U V Belkin M Bousquet O Consistency of spectral clustering
[J]. Annals of Statistics , 2008 ,36 (2 ):555 -586 .
[本文引用: 1]
[27]
Shi J B Malik J Normalized cuts and image segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2000 ,22 (8 ):888 -905 .
[本文引用: 1]
[28]
段海滨 ,王道波 ,朱家强 ,等 .蚁群算法理论及应用研究的进展
[J].控制与决策 ,2004 ,19 (12 ):1321 -1326 .
Magsci
[本文引用: 1]
摘要
<p>蚁群算法是优化领域中新出现的一种仿生进化算法. 该算法采用分布式并行计算机制, 易与其他方法结合,<br />具有较强的鲁棒性; 但搜索时间长、易限入局部最优解是其突出的缺点. 针对蚁群算法, 首先介绍其基本原理; 然后讨<br />论了近年来对蚁群算法的若干改进以及在许多新领域中的发展应用; 最后评述了蚁群算法未来的研究方向和主要研<br />究内容.</p>
[ Duan H B Wang D B Zhu J Q et al .Development on ant colony algorithm theory and its application
[J]. Control & Decision , 2004 ,19 (12 ):1321 -1320 . ]
Magsci
[本文引用: 1]
摘要
<p>蚁群算法是优化领域中新出现的一种仿生进化算法. 该算法采用分布式并行计算机制, 易与其他方法结合,<br />具有较强的鲁棒性; 但搜索时间长、易限入局部最优解是其突出的缺点. 针对蚁群算法, 首先介绍其基本原理; 然后讨<br />论了近年来对蚁群算法的若干改进以及在许多新领域中的发展应用; 最后评述了蚁群算法未来的研究方向和主要研<br />究内容.</p>
[29]
杨平 ,郑金华 .遗传选择算子的比较与研究
[J].计算机工程与应用 ,2007 ,43 (15 ):59 -62 .
Magsci
[本文引用: 1]
摘要
在改进的基本遗传算法的实验基础上,通过分析传统的基本选择算子的理论及其优缺点,提出了能够产生较好收敛速度的三种选择方法:基于上限的确定式采样、基于切断的轮盘赌选择以及无回放最大值选择法,通过实验证明其在收敛性和收敛速度上都有很大的改善,为一些需要更快速求到最优解的应用问题提供了更好的选择策略。
[ Yang P Zheng J H Comparison and research over genetic election operators
[J]. Computer Engineering & Applications , 2007 ,43 (15 ):59 -62 . ]
Magsci
[本文引用: 1]
摘要
在改进的基本遗传算法的实验基础上,通过分析传统的基本选择算子的理论及其优缺点,提出了能够产生较好收敛速度的三种选择方法:基于上限的确定式采样、基于切断的轮盘赌选择以及无回放最大值选择法,通过实验证明其在收敛性和收敛速度上都有很大的改善,为一些需要更快速求到最优解的应用问题提供了更好的选择策略。
位置大数据的价值提取与协同挖掘方法
2
2014
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
... 为了分析区域之间的关联性,需要将城市热点区域进行离散化.常用的区域离散化方法包括:均匀网格法,依照道路划分的方法,按照轨迹点密度划分以及以兴趣点为参照的多边形划分等几类[1 ] .本文将根据OD点的分布,结合密度划分和多边形划分的方法进行区域离散化.热点区域离散化方法流程如图4 所示.针对市中心OD点的密度远大于城市边缘地区,且市中心内部点密度相对均匀的情况,首先利用DBSCAN算法过滤城市边缘的稀疏区域,并将城市边缘存在的少数密集区域作为单独网格.而对OD点密集的市中心区域再利用基于距离的k-means算法单独进行聚类,确定每个聚类的中心点.以各中心点为参照点生成泰森多边形(也称Voronoi多边形)[23 ] ,使得多边形内的所有样本点到该多边形内的参照点的距离比到其他任何一个参照点距离更短.这种城市区域离散化方法相比其他方法能更加准确地识别OD点密集的热点区域,同时基于OD点之间距离的划分策略也使得每个网格能够很好地保留点分布的原始特征. ...
位置大数据的价值提取与协同挖掘方法
2
2014
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
... 为了分析区域之间的关联性,需要将城市热点区域进行离散化.常用的区域离散化方法包括:均匀网格法,依照道路划分的方法,按照轨迹点密度划分以及以兴趣点为参照的多边形划分等几类[1 ] .本文将根据OD点的分布,结合密度划分和多边形划分的方法进行区域离散化.热点区域离散化方法流程如图4 所示.针对市中心OD点的密度远大于城市边缘地区,且市中心内部点密度相对均匀的情况,首先利用DBSCAN算法过滤城市边缘的稀疏区域,并将城市边缘存在的少数密集区域作为单独网格.而对OD点密集的市中心区域再利用基于距离的k-means算法单独进行聚类,确定每个聚类的中心点.以各中心点为参照点生成泰森多边形(也称Voronoi多边形)[23 ] ,使得多边形内的所有样本点到该多边形内的参照点的距离比到其他任何一个参照点距离更短.这种城市区域离散化方法相比其他方法能更加准确地识别OD点密集的热点区域,同时基于OD点之间距离的划分策略也使得每个网格能够很好地保留点分布的原始特征. ...
北斗导航大数据建设与思考
1
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
北斗导航大数据建设与思考
1
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
基于出租车GPS数据的居民就医时空特征分析
1
2018
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
基于出租车GPS数据的居民就医时空特征分析
1
2018
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
基于谱聚类的用户关联关系挖掘
1
2016
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
基于谱聚类的用户关联关系挖掘
1
2016
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
Inferring transportation modes from GPS trajectories using a convolutional neural network
1
2018
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
基于出租车用户出行的功能区识别
1
2018
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
基于出租车用户出行的功能区识别
1
2018
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
众源车辆轨迹加油停留行为探测与加油站点提取
1
2017
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
众源车辆轨迹加油停留行为探测与加油站点提取
1
2017
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
Detecting crowdedness spot in city transportation
1
2013
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
大规模航运数据下“一带一路”国家和地区贸易网络分析
1
2018
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
大规模航运数据下“一带一路”国家和地区贸易网络分析
1
2018
... 导航定位技术的快速发展以及导航设备应用的普及,使得大量的导航数据在城市建设和居民活动中产生,成为一项重要资源[1 ] .大量具有泛在定位、导航、授时(Position Navigation and Time,PNT)特征的数据集合构成了导航大数据[2 ] .内嵌导航定位功能的设备,如车载、船载导航设备,智能手机和智能穿戴设备等,可被视为感知人类活动和环境时空动态信息的移动传感器,产生大量的导航数据.对导航大数据进行挖掘,可以获取隐含的用户运动规律和环境时空信息,进而为社会情报的获取分析,合理的城市规划等提供决策支持.目前利用导航大数据的研究主要集中在2个方面:① 挖掘用户行为特征,如利用海量的出租车数据挖掘居民的就医时空行为模式[3 ] ,通过用户手机产生的地理空间数据,利用谱聚类算法挖掘用户关联性[4 ] ,以及识别用户出行交通模式[5 ] 等;② 挖掘环境时空信息,如基于车辆导航数据进行功能区识别[6 ] ,加油站点分布数据提取[7 ] ,探测道路交通拥堵情况[8 ] 以及利用大洋船舶轨迹数据挖掘全球范围的贸易网络[9 ] 等. ...
Context-aware taxi demand hotspots prediction
2
2009
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
... 居民出行活动遍布城市全域,但OD点密集,居民活动频繁的热点区域才更具代表性,因此,需要首先挖掘出城市中的热点区域.城市热点区域挖掘中常用的方法是对坐标点进行聚类分析[10 ,21 ] .常用的聚类算法主要包含4类:层次聚类、划分式聚类、基于密度和基于网格聚类.本文以OD点坐标之间的欧氏距离为相似性度量,利用基于密度的DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法[22 ] 进行聚类挖掘热点区域.该算法在不用事先确定聚类个数的情况下能够较好地处理全城分布不均匀、不规则的OD点数据.DBSCAN算法有2个重要的参数:eps和MinPts,其中eps表示样本点的邻域距离阈值,MinPts表示位于样本邻域内其他样本点的数量阈值.采用k-distance方法[22 ] 确定聚类参数,针对城郊和市中心密度差别较大的情况,通过调整参数分别对城市全域和市中心进行2次聚类,相比固定参数的传统方法能够更好地捕捉不同尺度的热点区域分布. ...
Land-use classification using taxi GPS traces
1
2013
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
Urban land uses and traffic ‘source-sink areas': Evidence from GPS-enabled taxi data in Shanghai
1
2012
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
Understanding people lifestyles: Construction of urban movement knowledge graph from GPS trajectory
1
2017
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
Finding and evaluating community structure in networks
1
2004
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
Revealing travel patterns and city structure with taxi trip data
2
2015
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
... 居民乘坐出租车出行次数关于行程距离的分布在不同的城市中具有不同的特征,该分布是理解出租车轨迹数据的重要统计性质.如图3 所示,通过对数坐标系可以看出,行程数量随行程距离的分布P(d)服从指数逐渐减小的幂律分布,与文献[15 ]中的论述一致.出租车载客行程主要集中在短途范围内,行程数量随着距离的增加而减小,长距离行程的数量急剧下降.值得注意的是,在距离为21 km左右处出现了一个波峰,由此可推断该距离为市区到浦东机场或其他城郊热点区域的行程距离. ...
Detecting urban dynamics with taxi trip data for evaluation and optimizing of spatial planning: The example of Xiamen city, China
1
2016
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
基于出租车GPS数据的城市交通拥堵识别和关联性分析
1
2016
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
基于出租车GPS数据的城市交通拥堵识别和关联性分析
1
2016
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
基于居民出行特征的北京城市功能区识别与空间交互研究
1
2018
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
基于居民出行特征的北京城市功能区识别与空间交互研究
1
2018
... 利用导航大数据挖掘城市人文地理信息的研究近年来获得广泛关注.针对轨迹数据采用聚类分析,可以挖掘城市中承载大量居民出行活动的热点区域和热点路径[10 ] .此外,也有研究基于出租车轨迹数据进一步对土地资源利用[11 ] ,以及上下客点时空分布反映的人口流动情况作了深入分析[12 ,13 ] .城市热点区域间居民活动的频繁程度往往能够反映出城市的功能区划,道路交通和基础设施建设特点等重要人文地理信息.有研究通过挖掘居民出行行为来揭示城市不同区域之间存在的关系网络以及关联性,并在此基础上进一步分析城市功能规划的特点.例如,基于分析和挖掘各种复杂系统(如社交网络,商业网络)的社区理论[14 ] ,利用社区发现算法挖掘城市中居民频繁开展日常活动的空间[15 ] ,划分出城市中所存在的基础设施功能可以自足的区域[16 ] ;以及识别城市交通拥堵的时空分布,分析拥堵事件的时空关联性[17 ] ;识别城市功能区并深入分析功能区之间的空间交互特征[18 ] 等. ...
1
2018
... 乘坐出租车出行是重要的居民出行方式之一,相比公交地铁等方式,出租车为居民出行提供定制化的服务,没有固定的载客路线,能较好地反映居民出行特点.出租车轨迹数据还具有分布广、易收集的特点,因此本文选取出租车轨迹数据作为居民出行导航数据.数据集包含上海市2007年2月20日全天24 h的出租车轨迹数据[19 ] ,采样间隔为1 min,坐标精度约20 m.出租车轨迹数据由离散的多维数据点构成,包含车辆信息、时间戳、经纬度、速度以及载客状态等.针对数据中的粗差以及定位精度问题,首先对数据进行了清洗,并将轨迹数据与道路网进行了匹配,最终得到有用的干净数据中涵盖了4316辆出租车.根据数据中的载客状态提取轨迹中的上下客点:载客状态从“0”变为“1”表示上客点,载客状态从“1”变为“0”表示下客点.为验证本文数据的有效性,首先对上下客点的时空分布特性以及载客行程距离分布特性等进行分析. ...
Understanding intra-urban trip patterns from taxi trajectory data
1
2012
... 上下客点数量的时间分布如图1 所示,上午 9时到晚上23时左右是居民出行的活跃时段,同时,在上午11时和晚上21时左右分别出现了一个驼峰,代表居民日常活动中的出行和返程高峰时段.由于出租车数据选自休息日,早上出行和晚上返程的高峰相比工作日有一定延迟,该分布与文献[20 ]中的结果相吻合. ...
Mining GPS data to determine interesting locations
1
2011
... 居民出行活动遍布城市全域,但OD点密集,居民活动频繁的热点区域才更具代表性,因此,需要首先挖掘出城市中的热点区域.城市热点区域挖掘中常用的方法是对坐标点进行聚类分析[10 ,21 ] .常用的聚类算法主要包含4类:层次聚类、划分式聚类、基于密度和基于网格聚类.本文以OD点坐标之间的欧氏距离为相似性度量,利用基于密度的DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法[22 ] 进行聚类挖掘热点区域.该算法在不用事先确定聚类个数的情况下能够较好地处理全城分布不均匀、不规则的OD点数据.DBSCAN算法有2个重要的参数:eps和MinPts,其中eps表示样本点的邻域距离阈值,MinPts表示位于样本邻域内其他样本点的数量阈值.采用k-distance方法[22 ] 确定聚类参数,针对城郊和市中心密度差别较大的情况,通过调整参数分别对城市全域和市中心进行2次聚类,相比固定参数的传统方法能够更好地捕捉不同尺度的热点区域分布. ...
VDBSCAN: Varied density based spatial clustering of applications with noise
2
2007
... 居民出行活动遍布城市全域,但OD点密集,居民活动频繁的热点区域才更具代表性,因此,需要首先挖掘出城市中的热点区域.城市热点区域挖掘中常用的方法是对坐标点进行聚类分析[10 ,21 ] .常用的聚类算法主要包含4类:层次聚类、划分式聚类、基于密度和基于网格聚类.本文以OD点坐标之间的欧氏距离为相似性度量,利用基于密度的DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法[22 ] 进行聚类挖掘热点区域.该算法在不用事先确定聚类个数的情况下能够较好地处理全城分布不均匀、不规则的OD点数据.DBSCAN算法有2个重要的参数:eps和MinPts,其中eps表示样本点的邻域距离阈值,MinPts表示位于样本邻域内其他样本点的数量阈值.采用k-distance方法[22 ] 确定聚类参数,针对城郊和市中心密度差别较大的情况,通过调整参数分别对城市全域和市中心进行2次聚类,相比固定参数的传统方法能够更好地捕捉不同尺度的热点区域分布. ...
... [22 ]确定聚类参数,针对城郊和市中心密度差别较大的情况,通过调整参数分别对城市全域和市中心进行2次聚类,相比固定参数的传统方法能够更好地捕捉不同尺度的热点区域分布. ...
顾及出租车OD点分布密度的空间Voronoi剖分算法及OD流可视化分析
1
2015
... 为了分析区域之间的关联性,需要将城市热点区域进行离散化.常用的区域离散化方法包括:均匀网格法,依照道路划分的方法,按照轨迹点密度划分以及以兴趣点为参照的多边形划分等几类[1 ] .本文将根据OD点的分布,结合密度划分和多边形划分的方法进行区域离散化.热点区域离散化方法流程如图4 所示.针对市中心OD点的密度远大于城市边缘地区,且市中心内部点密度相对均匀的情况,首先利用DBSCAN算法过滤城市边缘的稀疏区域,并将城市边缘存在的少数密集区域作为单独网格.而对OD点密集的市中心区域再利用基于距离的k-means算法单独进行聚类,确定每个聚类的中心点.以各中心点为参照点生成泰森多边形(也称Voronoi多边形)[23 ] ,使得多边形内的所有样本点到该多边形内的参照点的距离比到其他任何一个参照点距离更短.这种城市区域离散化方法相比其他方法能更加准确地识别OD点密集的热点区域,同时基于OD点之间距离的划分策略也使得每个网格能够很好地保留点分布的原始特征. ...
顾及出租车OD点分布密度的空间Voronoi剖分算法及OD流可视化分析
1
2015
... 为了分析区域之间的关联性,需要将城市热点区域进行离散化.常用的区域离散化方法包括:均匀网格法,依照道路划分的方法,按照轨迹点密度划分以及以兴趣点为参照的多边形划分等几类[1 ] .本文将根据OD点的分布,结合密度划分和多边形划分的方法进行区域离散化.热点区域离散化方法流程如图4 所示.针对市中心OD点的密度远大于城市边缘地区,且市中心内部点密度相对均匀的情况,首先利用DBSCAN算法过滤城市边缘的稀疏区域,并将城市边缘存在的少数密集区域作为单独网格.而对OD点密集的市中心区域再利用基于距离的k-means算法单独进行聚类,确定每个聚类的中心点.以各中心点为参照点生成泰森多边形(也称Voronoi多边形)[23 ] ,使得多边形内的所有样本点到该多边形内的参照点的距离比到其他任何一个参照点距离更短.这种城市区域离散化方法相比其他方法能更加准确地识别OD点密集的热点区域,同时基于OD点之间距离的划分策略也使得每个网格能够很好地保留点分布的原始特征. ...
Data mining: Concepts and techniques
1
2011
... 著名的“购物篮分析”指出:当物体 i j i j i j [24 ] .同理,在城市中,如果起点位于区域 i j j i i j
谱聚类算法综述
2
2008
... 谱聚类算法是数据挖掘领域中常用的聚类算法之一,建立在图论的谱图理论基础上,是一种点对聚类算法[25 ] .其基本原理为:将研究对象即离散化后的热点区域抽象为关联图 G ( v , e ) [26 ] .聚类准则将对结果产生至关重要的影响,本文采用 Ncut [27 ] ,使目标函数 Ncut
... 谱聚类算法利用谱图理论来研究上述的相邻矩阵 V ' Ncut [25 ] .图 G ( v , e )
谱聚类算法综述
2
2008
... 谱聚类算法是数据挖掘领域中常用的聚类算法之一,建立在图论的谱图理论基础上,是一种点对聚类算法[25 ] .其基本原理为:将研究对象即离散化后的热点区域抽象为关联图 G ( v , e ) [26 ] .聚类准则将对结果产生至关重要的影响,本文采用 Ncut [27 ] ,使目标函数 Ncut
... 谱聚类算法利用谱图理论来研究上述的相邻矩阵 V ' Ncut [25 ] .图 G ( v , e )
Consistency of spectral clustering
1
2008
... 谱聚类算法是数据挖掘领域中常用的聚类算法之一,建立在图论的谱图理论基础上,是一种点对聚类算法[25 ] .其基本原理为:将研究对象即离散化后的热点区域抽象为关联图 G ( v , e ) [26 ] .聚类准则将对结果产生至关重要的影响,本文采用 Ncut [27 ] ,使目标函数 Ncut
Normalized cuts and image segmentation
1
2000
... 谱聚类算法是数据挖掘领域中常用的聚类算法之一,建立在图论的谱图理论基础上,是一种点对聚类算法[25 ] .其基本原理为:将研究对象即离散化后的热点区域抽象为关联图 G ( v , e ) [26 ] .聚类准则将对结果产生至关重要的影响,本文采用 Ncut [27 ] ,使目标函数 Ncut
蚁群算法理论及应用研究的进展
1
2004
... 蚁群算法是一种仿生优化算法.其基本原理为:一群蚂蚁在觅食时,会选择食源和蚁巢之间不同的路径,并留下随时间挥发的信息素,一条路径走过的蚂蚁越多,信息素浓度就越大,而蚂蚁会以更大概率选择信息素浓度较大且距离较短的路径.最终这种“正反馈”机制能够使蚂蚁找到一条最优(短)路径[28 ] .将蚁群算法应用于谱聚类算法划分出的子图中求解基于关联度距离的最优路径,可进一步研究本身已具有紧密关联性的区域之间更深层次的内在联系. ...
蚁群算法理论及应用研究的进展
1
2004
... 蚁群算法是一种仿生优化算法.其基本原理为:一群蚂蚁在觅食时,会选择食源和蚁巢之间不同的路径,并留下随时间挥发的信息素,一条路径走过的蚂蚁越多,信息素浓度就越大,而蚂蚁会以更大概率选择信息素浓度较大且距离较短的路径.最终这种“正反馈”机制能够使蚂蚁找到一条最优(短)路径[28 ] .将蚁群算法应用于谱聚类算法划分出的子图中求解基于关联度距离的最优路径,可进一步研究本身已具有紧密关联性的区域之间更深层次的内在联系. ...
遗传选择算子的比较与研究
1
2007
... 为了避免结果陷入局部最优解,采用轮盘赌方法作为蚂蚁转移策略,使迭代过程具有随机性[29 ] .每次迭代后信息素的更新包括2个部分,信息素的自然挥发以及蚂蚁走过留下的信息素增量. ...
遗传选择算子的比较与研究
1
2007
... 为了避免结果陷入局部最优解,采用轮盘赌方法作为蚂蚁转移策略,使迭代过程具有随机性[29 ] .每次迭代后信息素的更新包括2个部分,信息素的自然挥发以及蚂蚁走过留下的信息素增量. ...
 , 陈明剑
, 陈明剑

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}