
基于众包数据的室内定位方法和平台
作者简介:黄正宇(1991-),男,湖南岳阳人,硕士生,主要从事室内定位和信息检索方面研究。E-mail: huangzhengyu@ict.ac.cn
收稿日期: 2016-07-25
要求修回日期: 2016-09-29
网络出版日期: 2016-11-20
基金资助
国家自然科学基金项目(61572004、61472399)
中国科学院科研装备研制项目“面向可穿戴行为感知的精准模型测试仪研制”(YZ201527)
Indoor Localization Method and Platform Based on Crowdsourcing Data
Received date: 2016-07-25
Request revised date: 2016-09-29
Online published: 2016-11-20
Copyright
随着WLAN的普及,基于Wi-Fi的室内定位方法逐渐成为研究与应用的热点。虽然,其中基于位置指纹的定位算法研究相对广泛,应用效果较好,然而现有的指纹定位方法或系统仍存在以下3个问题:① 离线阶段的数据标定和定位模型的训练需要耗费大量人力物力,以及时间消耗,使系统很难得到实际应用;② 真实环境中WLAN信号波动呈现高动态性,采集的数据存在显著的时效性,无法提供长时间的有效定位保证;③ 实际环境中AP设备变动频繁,导致训练数据与定位数据特征维度不等长,造成模型失效。针对上述问题,本文提出了一种基于众包数据的模型更新方法,通过不断融合增量数据,使定位模型保持实时有效。该方法主要包括半监督极速学习机(SELM)、具有时效机制的增量式定位方法(TMELM)和特征自适应的在线极速学习机(FA-OSELM)3部分。基于上述方法,本文设计并实现了基于众包数据的室内定位平台系统。实际应用表明,本文提出的方法能够显著降低模型训练阶段的数据采集工作量,有效提升模型训练速度,并且长时间保持较高的定位精度。
黄正宇 , 陈益强 , 刘军发 , 蒋鑫龙 , 胡春雨 . 基于众包数据的室内定位方法和平台[J]. 地球信息科学学报, 2016 , 18(11) : 1476 -1784 . DOI: 10.3724/SP.J.1047.2016.01476
As WLAN getting more and more popular and pervasive, Wi-Fi based indoor localization is becoming a hot issue in research and application fields. Among various kinds of up-to-date indoor localization methods, fingerprint based methods are most widely used because of the good performance. However, the existing fingerprint based methods still have following three common problems: Firstly, fingerprint based methods require a vast amount of calibration work, which need huge human and time consumption both in offline and online phases. It makes the systems difficult to be applied in the practical applications. Secondly, the Wi-Fi signals in the environment change frequently, bringing the significant timeliness in collected data. So it cannot guarantee to provide a long term effective localization. Thirdly, the Wi-Fi access points change frequently in real scene. Thus, the feature dimensions of training data and testing data are unequal. The traditional algorithms cannot well handle the feature dimension changing problem caused by increase or decrease in APs’ number. To solve these problems mentioned above, we proposed a crowdsourcing based indoor localization method, including Semi-supervised ELM, Timeliness Managing ELM and Feature Adaptive Online Sequential ELM. We also developed an indoor localization platform. Applications show that our method can reduce human effort in data calibration and improve the model training speed. Moreover, our method can maintain the high location accuracy for a long time.
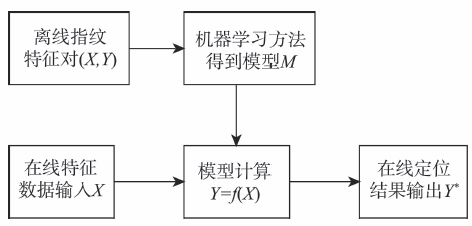
Fig. 1 The fingerprint model localization method framework图1 指纹模型定位方法框架 |
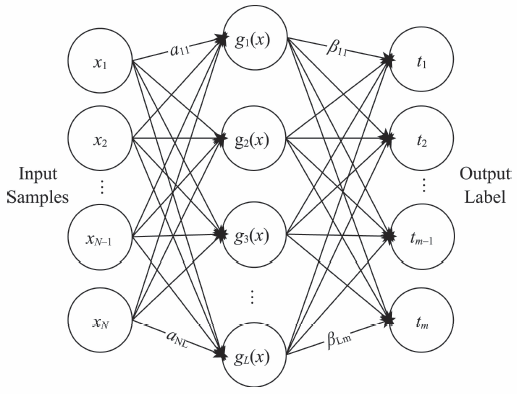
Fig. 2 Structure of ELM(Single-hidden layerfeedforward neural networks)图2 ELM网络结构(单隐层前馈神经网络SLFN) |
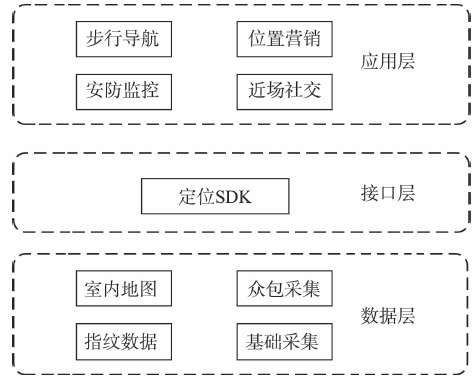
Fig. 3 Whole architecture of localization platform图3 基于众包数据的室内定位平台架构图 |
Fig. 4 Whole architecture of SDK图4 SDK整体架构图 |
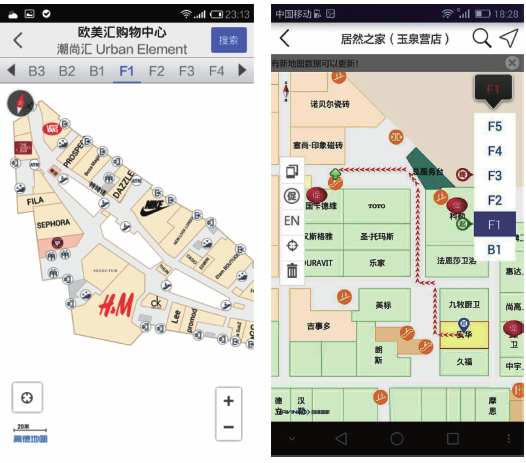
Fig. 5 The application of shopping closed-loop system图5 购物闭环系统应用APP |
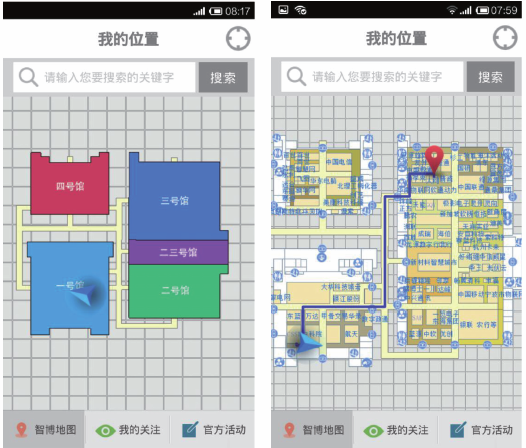
Fig. 6 The application of wisdom exhibition图6 智慧展览应用 |
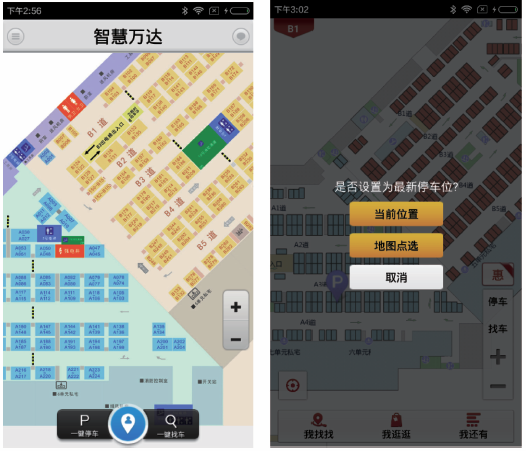
Fig. 7 The application of smart parking图7 智慧停车应用 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
[
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
Chung,
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}