
基于特征增强和ELU的神经网络建筑物提取研究
收稿日期: 2020-03-21
要求修回日期: 2020-06-21
网络出版日期: 2021-06-25
基金资助
国家重点研发计划项目(2018YFB0504504)
国家自然科学基金项目(41701506、41371406)
中央级公益性科研院所基本科研业务费专项资金项目(AR1923)
版权
Research on Building Extraction based on Neural Network with Feature Enhancement and ELU Activation Function
Received date: 2020-03-21
Request revised date: 2020-06-21
Online published: 2021-06-25
Supported by
The National Key R&D Program of China, No.2018YFB0504504(2018YFB0504504)
N-ational Natural Science Foundation of China, No.41701506, 41371406(41701506、41371406)
Central Public-interest Scientific Institution Basal Research Fund, No.AR1923(AR1923)
Copyright
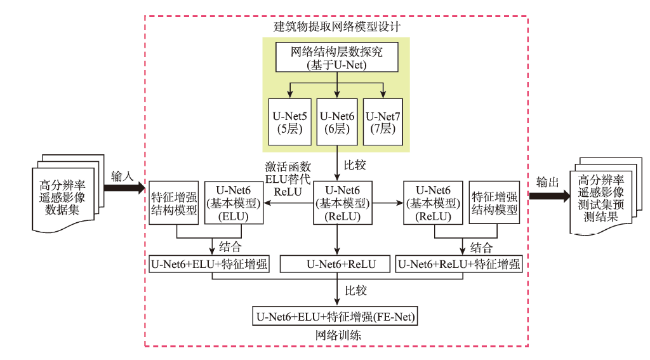
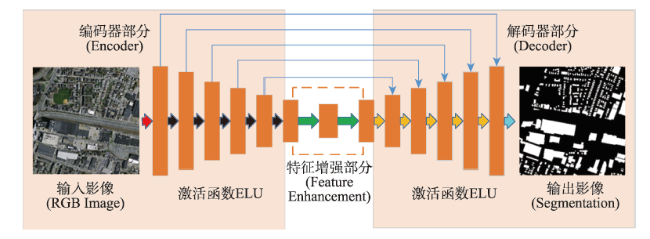
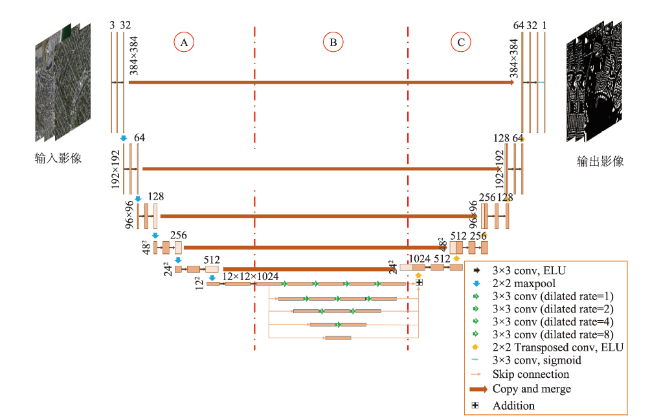
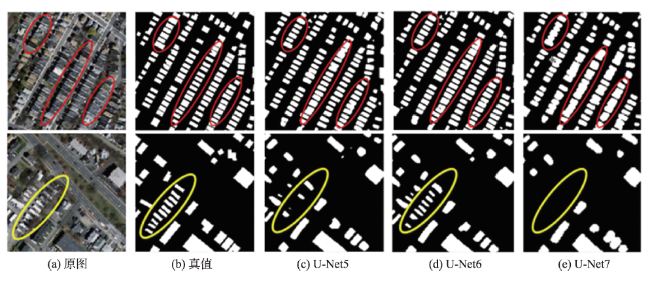
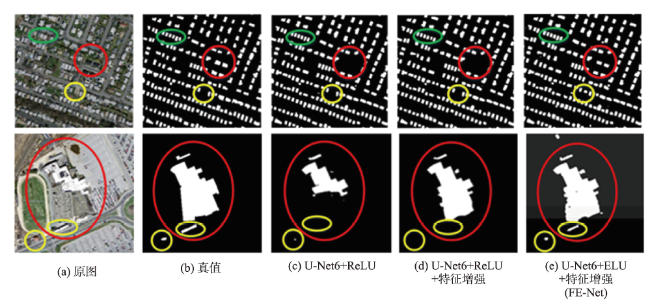
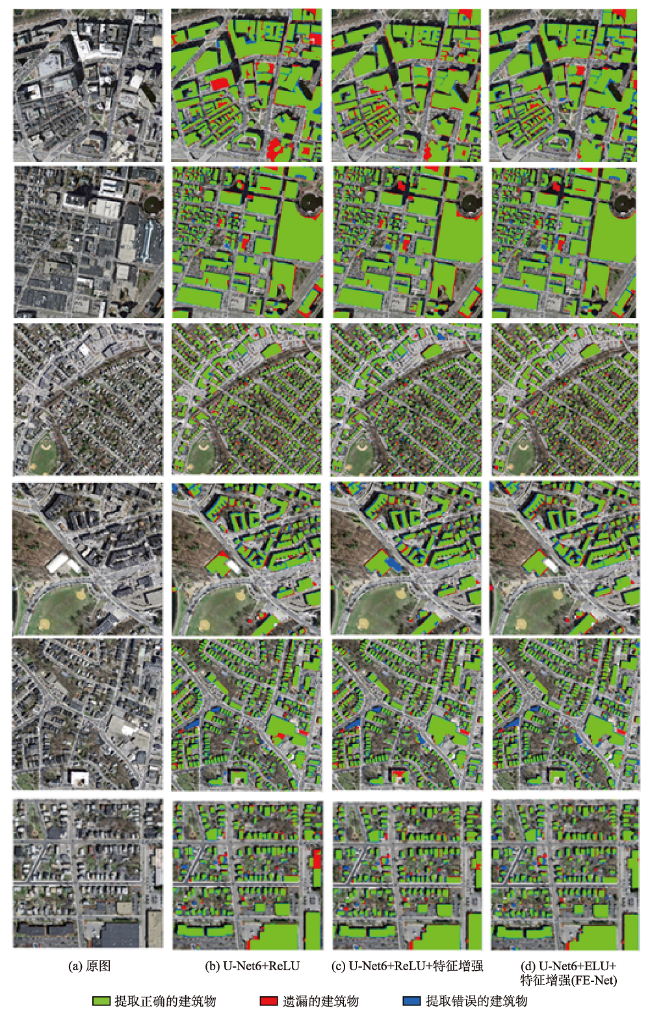
近年来,城市发展快速,大量人口奔向城市工作生活,城市建筑物的数量有如雨后春笋般扩张,需要合理地规划城市土地资源,遏制违规乱建现象,因此基于高分辨率遥感影像,对建筑物进行准确提取,对城市规划和管理有着重要辅助作用。本文基于U-Net网络模型,使用美国马萨诸塞州建筑物数据集,对网络模型结构进行探究,提出了一种激活函数为ELU、“编码器-特征增强-解码器”结构的网络模型FE-Net。实验首先通过比较不同网络层数的U-Net5、U-Net6、U-Net7的建筑物提取效果,找到最佳的基础网络模型U-Net6;其次,基于该模型,加入特征增强结构得到“U-Net6+ReLU+特征增强”的网络模型;最后,考虑到ReLU容易产生神经元死亡,为优化激活函数,将激活函数替换为ELU,从而得到网络模型FE-Net(U-Net6+ELU+特征增强)。比较3个网络模型(U-Net6+ReLU、U-Net6+ReLU+特征增强、FE-Net(U-Net6+ELU+特征增强))的建筑物提取结果,表明FE-Net网络模型的建筑物提取效果最好,精度放松F1值达到97.23%,比“U-Net6+ReLU”和“U-Net6+ReLU+特征增强”2个网络模型分别高出0.36%和0.12%,且与其他具有相同数据集的研究成果比较,具有最高的提取精度,它能较好地提取出多尺度的建筑物,不仅对小尺度建筑物有较好的提取效果,而且能大致、较完整地提取出形状不规则的建筑物,有相对更少的漏检和错检,较准确地实现了端到端的建筑物提取。

唐璎 , 刘正军 , 杨懿 , 顾海燕 , 杨树文 . 基于特征增强和ELU的神经网络建筑物提取研究[J]. 地球信息科学学报, 2021 , 23(4) : 692 -709 . DOI: 10.12082/dqxxkx.2021.200130
In recent years, with the rapid development of the city, a large number of people turn to work and live in the city, resulting in an increasing number of urban buildings. Land resources and urban ecological environment (such as green space) are threatened to some extent. Thus, it is urgent to plan urban land resources and space reasonably, prevent illegal construction, improve urban living environment, and make the city sustainable, orderly, healthy, and green. With the high-resolution remote sensing image data becoming more and more abundant, accurate building extraction using high-resolution remote sensing images plays an important role in urban planning, urban management, and change detection of urban buildings. Based on the U-Net network model, using the Massachusetts building dataset, this paper explored the network model structure and proposed a network model called FE-Net with "encoder-feature enhancement-decoder" structure and ELU activation function. First, the best basic network model called U-Net6 was found by comparing the building extraction results using U-Net5, U-Net6, and U-Net7 with different number of network layers. Based on the U-Net6, the network model of "U-Net6+ReLU+feature enhancement" was established by adding the structure of feature enhancement. In order to optimize the activation function, the ReLU activation function was replaced by the ELU activation function, and then the network model called FE-Net (U-Net6+ELU+feature enhancement) was created. The FE-Net network model was compared with the building extraction results from the other two network models (U-Net6+ReLU and U-Net6+ReLU+feature enhancement). Results show that the FE-Net network model had the best building extraction performance. Its relaxed F1-measure reached 97.23%, which was 0.36% and 0.12% higher than the other two network models. Meanwhile, FE-Net also had the highest extraction accuracy compared with other studies using the same dataset of Massachusetts. The FE-Net network model can extract multi-scale buildings better, which can not only extract small-scale buildings accurately, but also roughly and completely extract buildings with irregular shape with relatively less missing and wrong detections. Thus, the FE-Net network model can be used to achieve end-to-end building extraction with a high accuracy.
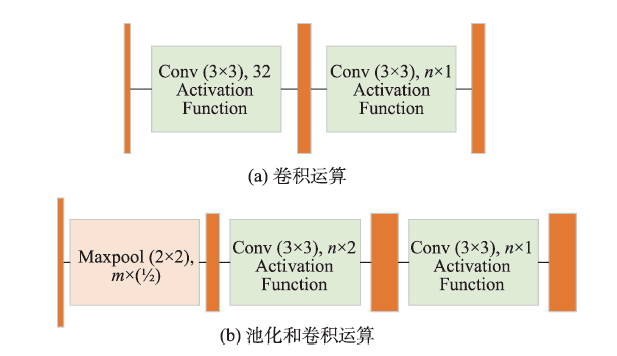
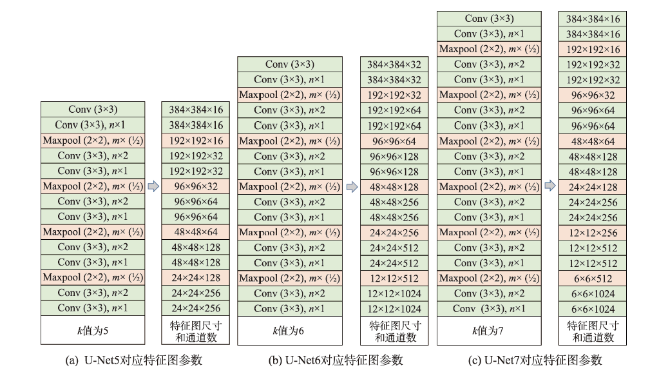
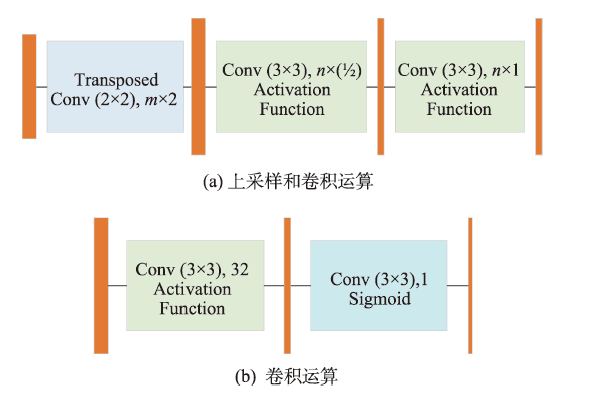
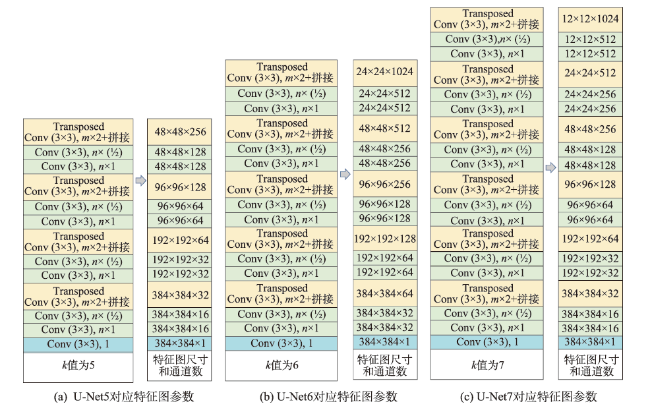
表1 FE-Net网络模型中各个特征图的对应参数Tab. 1 Corresponding parameters of each feature map in FE-Net network model |
| 编码器部分 | 解码器部分 | ||
|---|---|---|---|
| 名称 | 尺寸和通道数 | 名称 | 尺寸和通道数 |
| 输入影像 | 384×384×3 | 特征图 | 12×12×1024 |
| Conv(3×3), 32 | 384×384×32 | Transposed Conv(3×3), m×2+拼接 | 24×24×1024 |
| Conv(3×3), n×1 | 384×384×32 | Conv(3×3), n×(1/2) | 24×24×512 |
| Maxpool(2×2), m×(1/2) | 192×192×32 | Conv(3×3), n×1 | 24×24×512 |
| Conv(3×3), n×2 | 192×192×64 | Transposed Conv(3×3), m×2+拼接 | 48×48×512 |
| Conv(3×3), n×1 | 192×192×64 | Conv(3×3), n×(1/2) | 48×48×256 |
| Maxpool(2×2), m×(1/2) | 96×96×64 | Conv(3×3), n×1 | 48×48×256 |
| Conv(3×3), n×2 | 96×96×128 | Transposed Conv(3×3), m×2+拼接 | 96×96×256 |
| Conv(3×3), n×1 | 96×96×128 | Conv(3×3), n×(1/2) | 96×96×128 |
| Maxpool(2×2), m×(1/2) | 48×48×128 | Conv(3×3), n×1 | 96×96×128 |
| Conv(3×3), n×2 | 48×48×256 | Transposed Conv(3×3), m×2+拼接 | 192×192×128 |
| Conv(3×3), n×1 | 48×48×256 | Conv(3×3), n×(1/2) | 192×192×64 |
| Maxpool(2×2), m×(1/2) | 24×24×256 | Conv(3×3), n×1 | 192×192×64 |
| Conv(3×3), n×2 | 24×24×512 | Transposed Conv(3×3), m×2+拼接 | 384×384×64 |
| Conv(3×3), n×1 | 24×24×512 | Conv(3×3), n×(1/2) | 384×384×32 |
| Maxpool(2×2), m×(1/2) | 12×12×512 | Conv(3×3), n×1 | 384×384×32 |
| Conv(3×3), n×2 | 12×12×1024 | Conv(3×3), 1 | 384×384×1 |
| Conv(3×3), n×1 | 12×12×1024 | ||
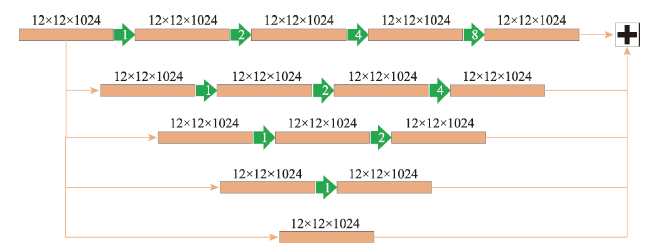
注:在特征增强部分,经过空洞卷积后得到的特征图,它们的大小和通道数均为12×12×1024。 |
表2 实验环境Tab. 2 Experimental environment |
| 项目 | 参数 |
|---|---|
| 中央处理器 | Intel® Xeon(R) CPU E5-2620 v2 @2.10GHz × 24 |
| 内存 | 62.8 GB |
| 硬盘 | 2 TB |
| 显卡 | GeForce GTX 1080/PCIe/SSE2 |
| 操作系统 | Ubuntu 16.04 |
| 开发语言 | Python |
| 深度学习框架 | PyTorch |
表3 不同网络结构层数实验结果对比Tab. 3 Comparison of experimental results of different network layers |
| 模型 | 网络层数 | 放松精准率(ρ=3)/% | 放松召回率(ρ=3)/% | 放松F1值(ρ=3)/% | 训练时间/s |
|---|---|---|---|---|---|
| U-Net5 | 5 | 95.43 | 92.97 | 94.10 | 85 761 |
| U-Net6 | 6 | 98.31 | 95.46 | 96.87 | 119 610 |
| U-Net7 | 7 | 96.58 | 91.33 | 93.89 | 193 152 |
| U-Net8 | 8 | 训练崩溃,训练时间太长 | |||
表4 网络模型实验结果对比Tab. 4 Comparison of network models' experiment results |
| 模型 | 放松精准率(ρ=3)/% | 放松召回率(ρ=3)/% | 放松F1值(ρ=3)/% | 训练时间/s |
|---|---|---|---|---|
| U-Net6+ ReLU | 98.31 | 95.46 | 96.87 | 119 610 |
| U-Net6+ ReLU+特征增强 | 98.50 | 95.93 | 97.11 | 136 487 |
| U-Net6+ ELU+特征增强(FE-Net) | 98.59 | 96.11 | 97.23 | 138 135 |
| [1] |
|
| [2] |
黄金库, 冯险峰, 徐秀莉, 等. 基于知识规则构建和形态学修复的建筑物提取研究[J]. 地理与地理信息科学, 2011,27(4):28-31.
[
|
| [3] |
林雨准, 张保明, 徐俊峰, 等. 多特征多尺度相结合的高分辨率遥感影像建筑物提取[J]. 测绘通报, 2017(12):53-57.
[
|
| [4] |
林祥国, 张继贤. 面向对象的形态学建筑物指数及其高分辨率遥感影像建筑物提取应用[J]. 测绘学报, 2017,46(6):724-733.
[
|
| [5] |
田昊, 杨剑, 汪彦明, 等. 基于先验形状约束水平集模型的建筑物提取方法[J]. 自动化学报, 2010,36(11):1502-1511.
[
|
| [6] |
黄昕. 高分辨率遥感影像多尺度纹理、形状特征提取与面向对象分类研究[D]. 武汉:武汉大学, 2009.
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
刘文涛, 李世华, 覃驭楚. 基于全卷积神经网络的建筑物屋顶自动提取[J]. 地球信息科学学报, 2018,20(11):1562-1570.
[
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
王宇, 杨艺, 王宝山, 等. 深度神经网络条件随机场高分辨率遥感图像建筑物分割[J]. 遥感学报, 2019,23(6):1194-1208.
[
|
| [20] |
范荣双, 陈洋, 徐启恒, 等. 基于深度学习的高分辨率遥感影像建筑物提取方法[J]. 测绘学报, 2019,48(1):34-41.
[
|
| [21] |
|
| [22] |
杨嘉树, 梅天灿, 仲思东. 顾及局部特性的 CNN 在遥感影像分类的应用[J]. 计算机工程与应用, 2018,54(7):188-195.
[
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}