
基于DBI和稀疏轨迹数据的交通状态精细划分与识别
|
朱秋圳(1996— ),男,福建平和人,硕士生,主要从事时空数据挖掘研究。E-mail: zqiiuz@163.com |
收稿日期: 2021-07-18
要求修回日期: 2021-08-30
网络出版日期: 2022-05-25
基金资助
国家自然科学基金项目(41471333)
中央引导地方科技发展专项(2017L3012)
版权
Fine Classification and Identification of Traffic States based on DBI and Sparse Trajectory Data
Received date: 2021-07-18
Request revised date: 2021-08-30
Online published: 2022-05-25
Supported by
National Natural Science Foundation of China(41471333)
The Central Guided Local Development of Science and Technol- ogy Project(2017L3012)
Copyright
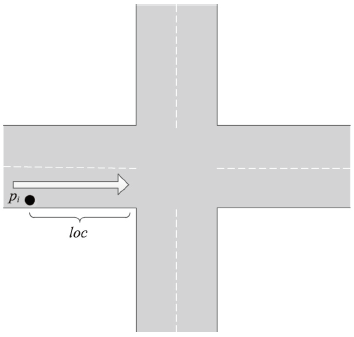
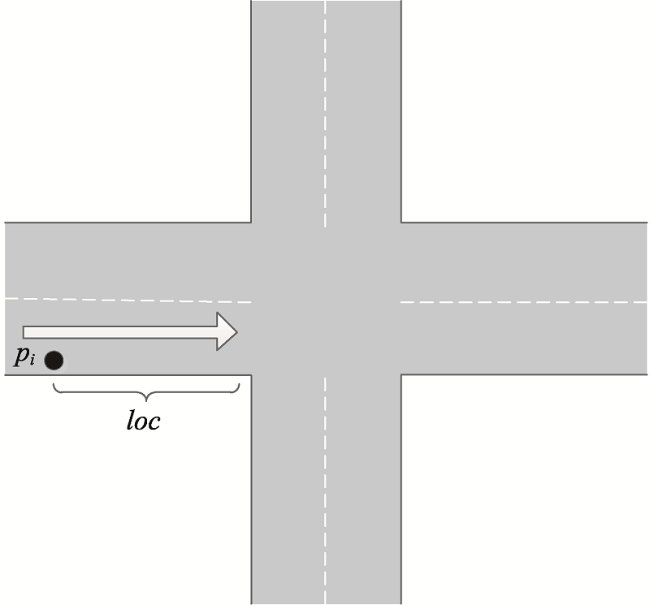
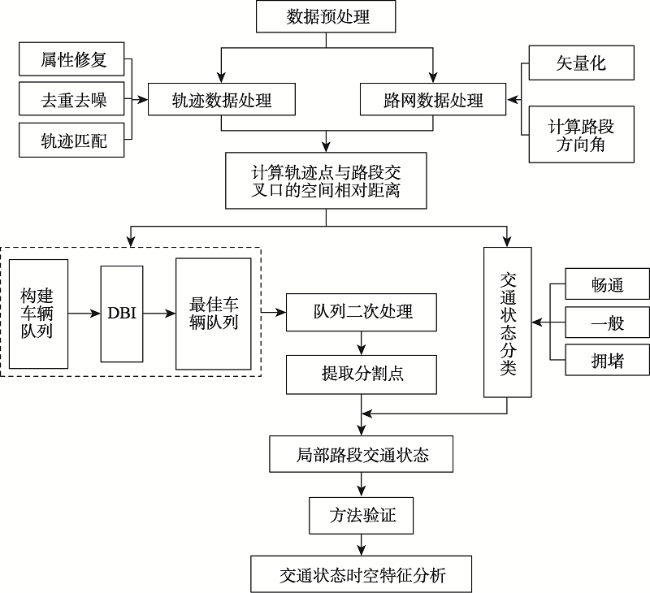
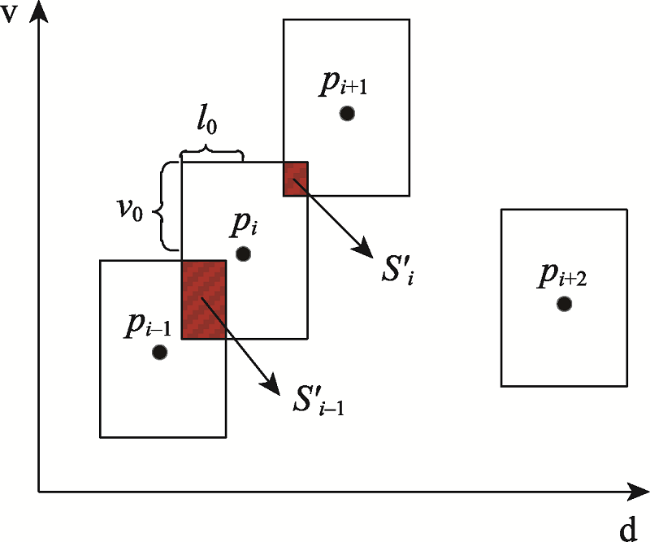
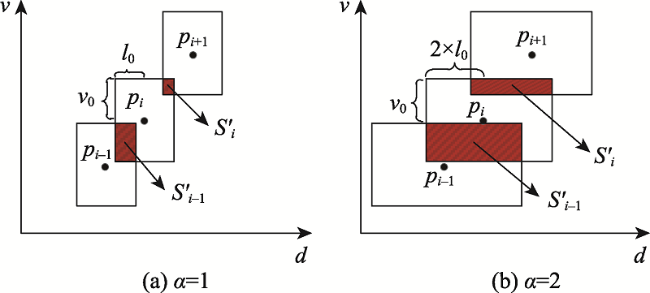
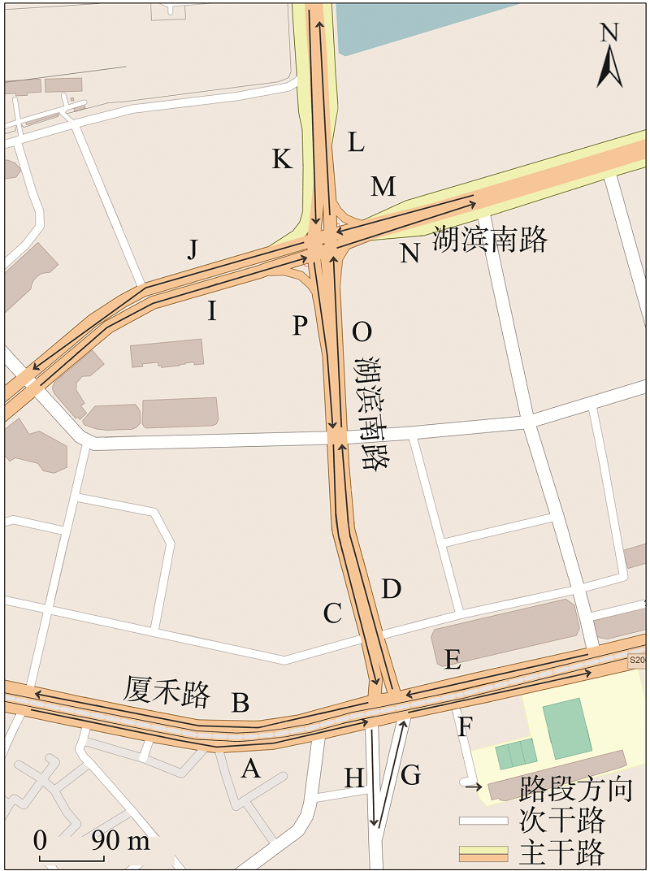
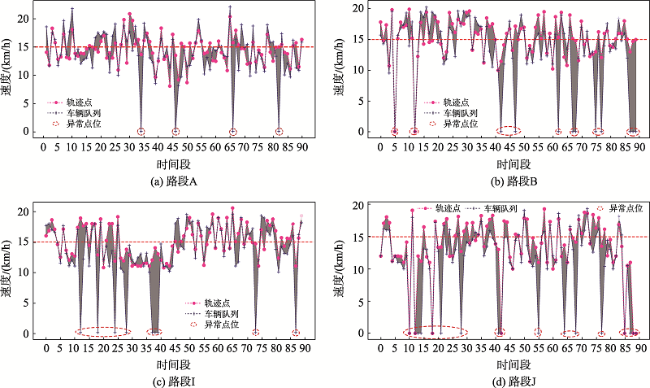
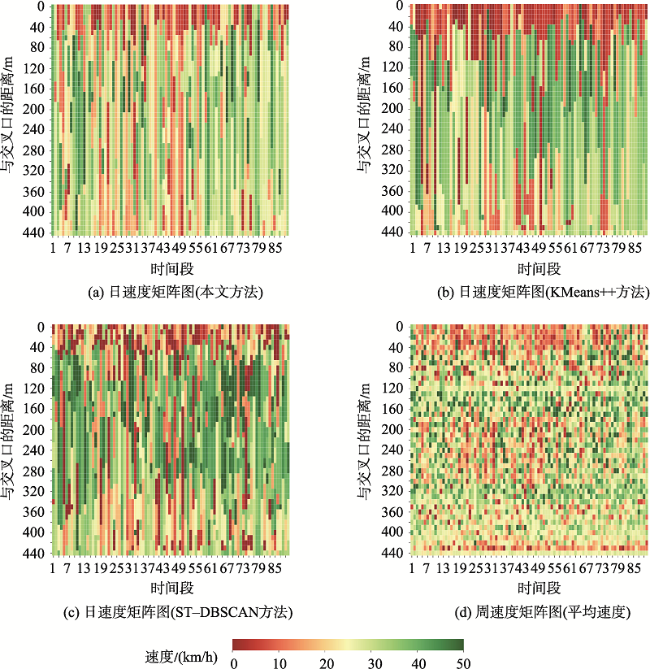
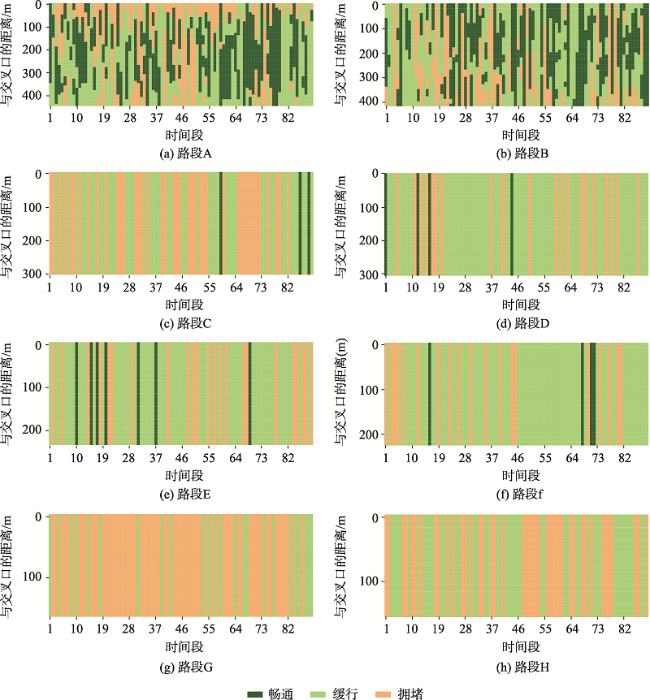
浮动车轨迹数据已逐渐成为城市交通状态识别的主要数据源之一,但是现有基于浮动车轨迹数据的交通状态识别中多数是应用高精度或是多源轨迹数据。针对稀疏轨迹数据在城市交通状态识别中存在识别精度不高的问题,本文提出一种结合戴维森堡丁指数(DBI)和轨迹相似性度量的动态交通状态划分方法。首先,对轨迹数据和路网数据进行预处理并且建立不同时间片的路段轨迹集合;接着,依据轨迹速度-空间相似性,利用戴维森堡丁指数动态地扩展轨迹的空间维度,并根据轨迹相似性度量方法构建最佳车辆队列;然后,将前后不同的车辆队列进行二次处理,连接组成交通流簇;最后,基于模糊C均值聚类方法将交通流进行划分,实现路段交通状态的识别。采用厦门市厦禾路、湖滨西路和湖滨南路交叉路段上的真实出租车轨迹数据进行测试,结果表明,本文所提方法保证了车辆队列速度分布与原始轨迹速度分布基本一致,相比对比方法Kmeans++和ST-DBSCAN,本文方法均方根误差平均下降了18.77%和21.22%,并且在不同的实验路段表现更加稳定,可有效、可靠地运用稀疏轨迹数据识别城市交通状态,进而实现城市交通状态的精细分析。
朱秋圳 , 邬群勇 , 姚铖鑫 , 孙豪宇 . 基于DBI和稀疏轨迹数据的交通状态精细划分与识别[J]. 地球信息科学学报, 2022 , 24(3) : 458 -468 . DOI: 10.12082/dqxxkx.2022.210408
Compared with traditional traffic detection data, floating vehicle trajectory data have the characteristics of wide coverage, low cost, and high mobility, which have been widely used in urban traffic status recognition and have gradually become one of the main data sources for urban traffic state recognition. However, most of the existing traffic state recognition based on floating vehicle trajectory data is based on high-precision or multi-source trajectory data. To address the problem of low accuracy of sparse trajectory data in urban traffic state recognition, this paper proposes a dynamic traffic state classification method combining Davies-Bouldin Index (DBI) and trajectory similarity metric to finely classify urban road traffic state, and then realizes the spatial and temporal characteristics of urban traffic state. Firstly, we pre-process the trajectory data and road network data, including data cleaning, map matching, and format conversion, record the relative spatial distances between trajectory points and matching road sections, and build a set of trajectories of road sections in different time slices. Secondly, we dynamically extend the spatial dimension of trajectories by using Davies-Bouldin Index (DBI) according to the trajectory speed-spatial similarity, and construct the best vehicle queue according to the trajectory similarity measure. After that, the different vehicle queues before and after are processed twice, and the vehicle queues are merged according to the rules and connected to form traffic flow clusters, so as to achieve the purpose of dividing local road sections and laying the foundation for subsequent recognition of local traffic states. Finally, the global trajectory points are clustered based on the fuzzy C-means clustering method to divide traffic states, and the speed bounds of different traffic states are obtained and compared with the previous traffic flow cluster speed The comparison is carried out to realize the local road traffic state identification, and then realize the fine analysis of traffic state. The real cab trajectory data at the intersection sections of Xiamen Xiahe Road, Hubin West Road, and Hubin South Road are used for testing. The results show that the traffic speed map calculated by the trajectory similarity metric method can reflect the changes of traffic speed on the road section more clearly, and the method ensures that the vehicle queuing speed distribution is basically consistent with the original trajectory speed distribution. Compared with the comparison methods, i.e., Kmeans++ and ST-DBSCAN, the root-mean-square error of the proposed method decreases by 18.77% and 21.22% on average, and it performs more stable and robust in different experimental road sections. It can effectively and reliably use sparse trajectory data to identify urban traffic states, and then realize the fine analysis of urban traffic states, which provides auxiliary decisions for the management of urban road traffic problems.
表1 轨迹数据样例及注解Tab. 1 Sample track data and annotations |
| 字段 | 样例 | 注释 |
|---|---|---|
| cid | 75677bf5af02481b760fa11eae94031c | 车辆id |
| status | 1 | 载客状态 |
| speed | 29.6 | 速度/(km/h) |
| direction | 9 | 车头朝向 |
| time | 2020-06-22 08:45:11 | 采样时间 |
| lon | 118.12°E | 经度 |
| lat | 24°N | 纬度 |
表2 各方法在不同路段上RMSE和MAE比较Tab. 2 Comparison of MAE and RMSE for each method on different road sections |
| 路段编号 | 使用方法 | 评价指标 | |
|---|---|---|---|
| RMSE | MAE | ||
| A | 本文方法 | 7.53 | 10.18 |
| Kmeans++ | 9.87 | 14.43 | |
| ST-DBSCAN | 12.88 | 15.44 | |
| B | 本文方法 | 8.54 | 10.5 |
| Kmeans++ | 10.31 | 12.63 | |
| ST-DBSCAN | 11.02 | 11.62 | |
| I | 本文方法 | 9.02 | 11.4 |
| Kmeans++ | 10.85 | 13.02 | |
| ST-DBSCAN | 9.53 | 12.53 | |
| J | 本文方法 | 8.46 | 8.87 |
| Kmeans++ | 8.77 | 10.63 | |
| ST-DBSCAN | 10.23 | 13.11 | |
| [1] |
闫学东, 刘晓冰, 刘炀, 等. 基于浮动车大数据与网格模型的城市交通拥堵识别和评价研究[J]. 北京交通大学学报, 2019, 43(1):104-113.
[
|
| [2] |
|
| [3] |
吴华意, 黄蕊, 游兰, 等. 出租车轨迹数据挖掘进展[J]. 测绘学报, 2019, 48(11):1341-1356.
[
|
| [4] |
黄子赫, 高尚兵, 蔡创新, 等. 多重处理的道路拥堵识别可视化融合分析[J]. 中国图象图形学报, 2020, 25(2):409-418.
[
|
| [5] |
邬群勇, 胡振华, 张红. 基于多源轨迹数据的城市交通状态精细划分与识别[J]. 交通运输系统工程与信息, 2020, 20(1):83-90.
[
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
周艳, 李妍羲, 江荣贵, 等. 交通拥堵与预警信息交互传播动力学分析[J]. 地球信息科学学报, 2017, 19(10):1279-1286.
[
|
| [17] |
唐炉亮, 牛乐, 杨雪, 等. 利用轨迹大数据进行城市道路交叉口识别及结构提取[J]. 测绘学报, 2017, 46(6):770-779.
[
|
| [18] |
李思宇, 向隆刚, 张彩丽, 等. 基于低频出租车轨迹的城市路网交叉口提取研究[J]. 地球信息科学学报, 2019, 21(12):1845-1854.
[
|
| [19] |
|
| [20] |
付子圣, 李秋萍, 柳林, 等. 利用GPS轨迹二次聚类方法进行道路拥堵精细化识别[J]. 武汉大学学报·信息科学版, 2017, 42(9):1264-1270.
[
|
| [21] |
张彭, 张晓松, 雷方舒, 等. 道路拥堵概率估计方法及其在城市交通运行评价中的应用[J]. 交通运输系统工程与信息, 2015, 15(6):161-169.
[
|
| [22] |
雷宁, 张光德, 陈玲娟. 基于改进模糊聚类算法的快速路交通状态分类评价[J]. 公路, 2017, 62(11):134-139.
[
|
| [23] |
|
| [24] |
王美红. 基于实测数据的天津市交通拥堵时空关联性分析[D]. 北京:北京交通大学, 2019.
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}