
一种基于深度传递迁移学习的遥感影像分类方法
|
林 禹(1994— ),男,辽宁抚顺人,硕士生,主要从事基于深度学习的遥感影像分类研究。E-mail: 915842453@qq.com |
收稿日期: 2021-07-25
要求修回日期: 2021-10-05
网络出版日期: 2022-05-25
基金资助
国家自然科学基金项目(41801233)
国家自然科学基金项目(41801368)
版权
A Remote Sensing Image Classification Method based on Deep Transitive Transfer Learning
Received date: 2021-07-25
Request revised date: 2021-10-05
Online published: 2022-05-25
Supported by
National Natural Science Foundation of China(41801233)
National Natural Science Foundation of China(41801368)
Copyright
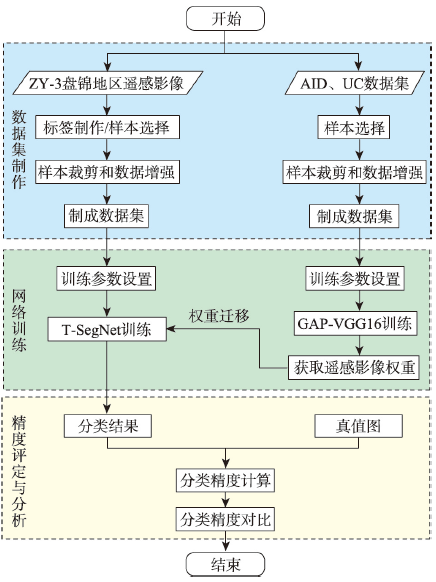
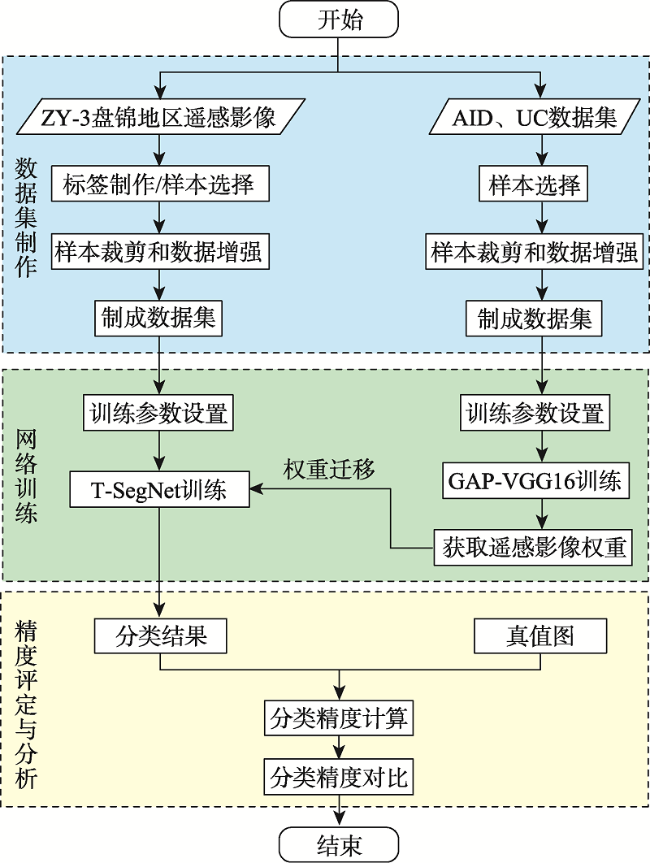
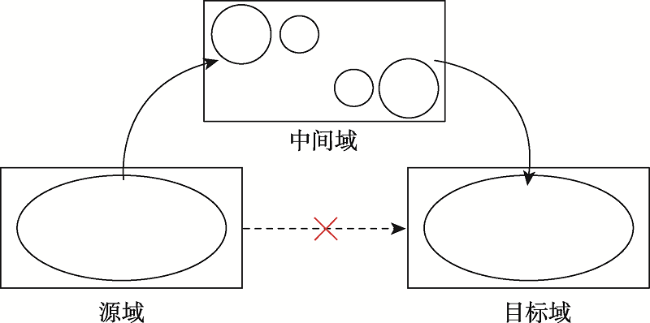
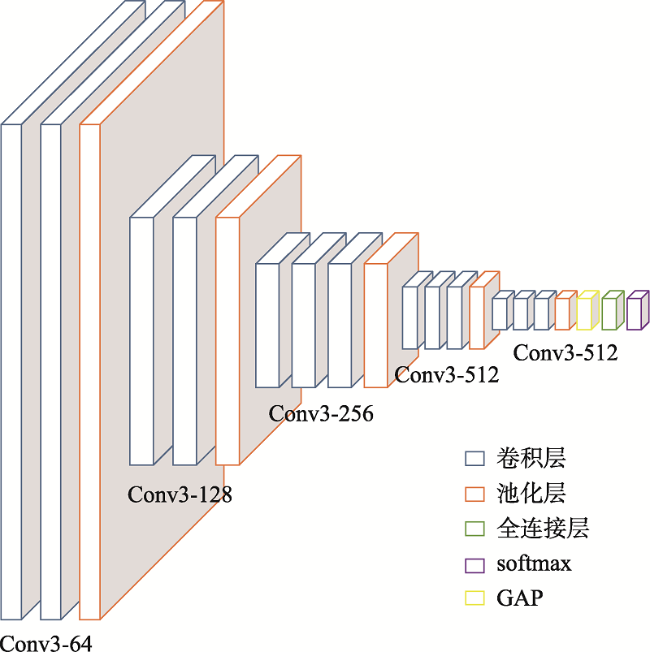
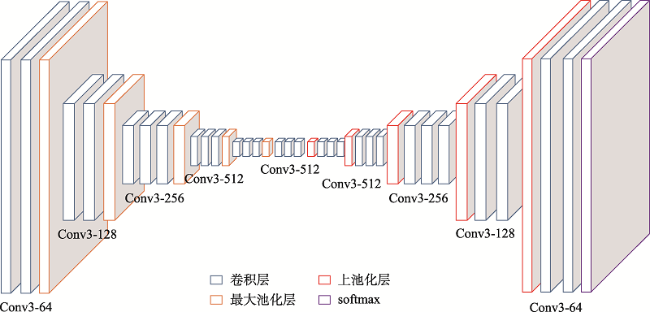
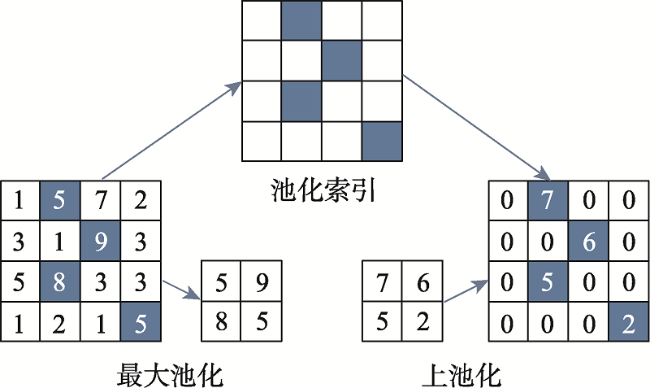
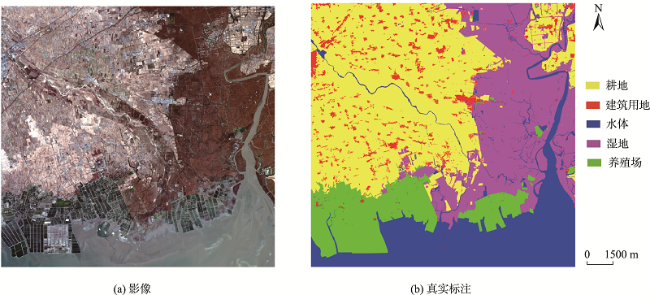
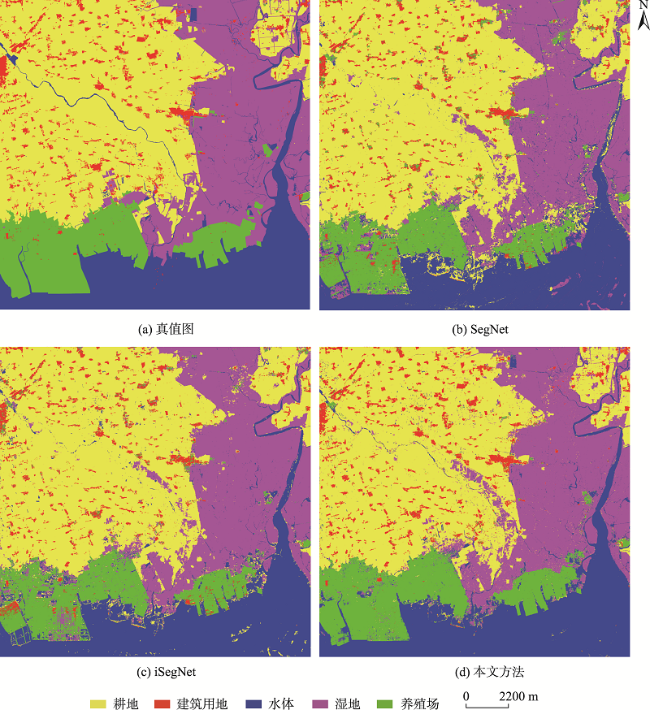
面对实际的遥感影像分类任务,采用深度神经网络的方法存在的最大问题是缺乏充足的标注样本,如何使用较少的标注样本实现较高精度的遥感影像分类,是目前需要解决的问题。ImageNet作为世界上最大的图像识别数据集,在其上训练出的模型有着丰富的底层特征。对ImageNet预训练模型进行微调是最常见的迁移学习方法,能够一定程度利用其丰富的底层特征,提高分类精度。但ImageNet影像特征与遥感影像差距较大,对分类效果提升有限。为了解决上述问题,本文基于传递迁移学习思想,结合深度神经网络,提出一种基于深度传递迁移学习的遥感影像分类方法。该方法通过构建以开源遥感场景识别数据集为源域的中间域,并以ImageNet预训练权重为源域、待分类遥感影像为目标域进行迁移学习,提高遥感影像分类精度。首先,以ImageNet预训练VGG16网络为基础,为加速卷积层权重更新而将全连接层替换为全局平均池化层,构建GAP-VGG16,使用中间域数据集训练ImageNet预训练GAP-VGG16以获取权重;然后,以SegNet网络为基础,在SegNet中加入卷积层设计了T-SegNet,以对获取的权重进一步地提取。最后,将获取的权重迁移到T-SegNet中,使用目标域数据集训练,实现遥感影像分类。本文选取Aerial Image Dataset和UC Merced Land-Use DataSet作为中间域数据集的数据源,资源三号盘锦地区影像为目标域影像,并分别选取了50%和25%数量的训练样本进行实验。实验结果表明,在50%和25%数量的训练样本下,本文方法分类结果相比SegNet的Kappa系数分别提高了0.0459和0.0545,相比ImageNet预训练SegNet的Kappa系数分别提高了0.0377和0.0346,且在样本数较少的类别上,本文方法分类精度提升更明显。
林禹 , 赵泉华 , 李玉 . 一种基于深度传递迁移学习的遥感影像分类方法[J]. 地球信息科学学报, 2022 , 24(3) : 495 -507 . DOI: 10.12082/dqxxkx.2022.210428
In the practical task of remote sensing image classification, the biggest problem with the use of deep neural network method is the lack of sufficient labeled samples. How to use fewer labeled samples to achieve higher accuracy of remote sensing image classification is a problem that needs to be solved at present. ImageNet is the largest image recognition dataset in the world, the model trained on it has rich underlying features. Fine-tuning the ImageNet pre-training model is the most common transfer learning method, which can make use of the rich underlying features to improve the classification accuracy. However, there is a big difference between ImageNet image features and remote sensing image features, and the improvement of classification effect is limited. In order to solve the above problems, a remote sensing image classification method based on deep transitive transfer learning combined with deep neural network is proposed in this paper. This method constructs an intermediate domain using the open-source remote sensing scene recognition datasets as the data source and uses ImageNet pre-training weight as the source domain and remote sensing images to be classified as the target domain for transfer learning to improve remote sensing image classification accuracy. First, based on ImageNet pre-training VGG16 network, the fully connected layer is replaced by the global average pooling layer in order to speed up the weight update of convolutional layer, and the GAP-VGG16 is constructed. The intermediate domain dataset is used for training the ImageNet pre-training GAP-VGG16 to obtain the weight. Then, based on the SegNet, the T-SegNet is designed by adding the convolutional layer into the SegNet to further extract the obtained weight. Finally, the obtained weight is transferred to T-SegNet, and the remote sensing image classification is achieved by training the target domain dataset. In this paper, the Aerial Image Dataset and UC Merced Land-Use Dataset are selected as the data sources of the intermediate domain dataset, and the ZY-3 Panjin area image is selected as the target domain image, 50% and 25% of the training samples are selected for the experiment. The experimental results show that using 50% and 25% of the training samples, the Kappa coefficient of the classification results using the proposed method in this paper is increased by 0.0459 and 0.0545, respectively compared to SegNet, and is increased by 0.0377 and 0.0346, respectively compared to ImageNet pre-training SegNet. For classes with a smaller number of samples, the classification accuracy of the method in this paper is improved more significantly.
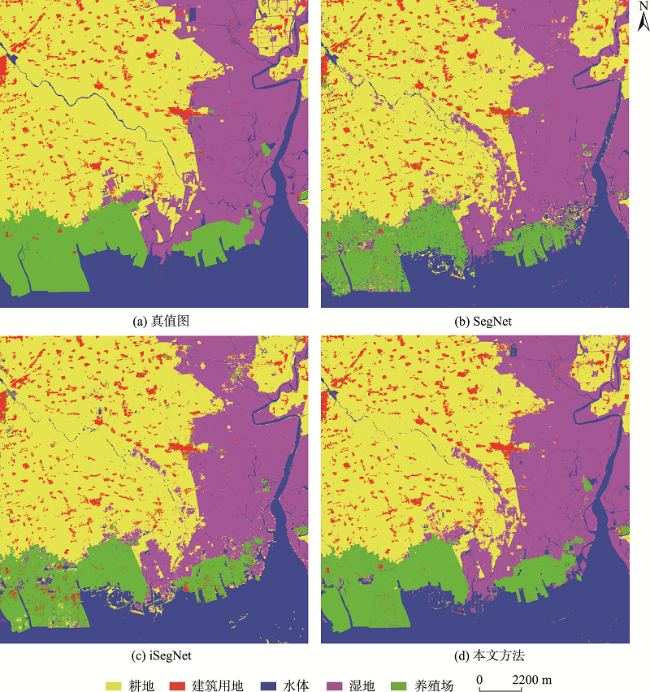
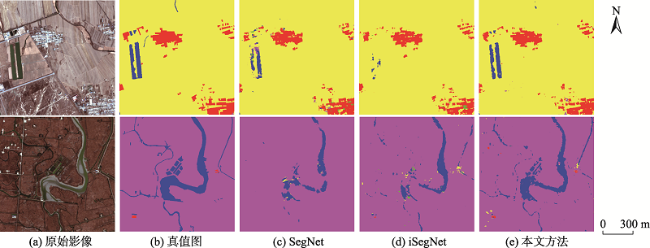
图10 各算法50%样本局部分类结果Fig. 10 Local classification results of 25% samples for each methods |
表1 50%样本下分类定量评价结果比较Tab. 1 Quantitative evaluation results of 50% samples for different methods |
| 地物 | IoU | OA | Kappa | ||||
|---|---|---|---|---|---|---|---|
| 耕地 | 建筑用地 | 水体 | 湿地 | 养殖场 | |||
| SegNet | 0.8771 | 0.6456 | 0.8511 | 0.8103 | 0.7795 | 0.9100 | 0.8744 |
| iSegNet | 0.8838 | 0.6357 | 0.8662 | 0.8274 | 0.7909 | 0.9161 | 0.8826 |
| 本文方法 | 0.9161 | 0.6971 | 0.9068 | 0.8697 | 0.9007 | 0.9426 | 0.9203 |
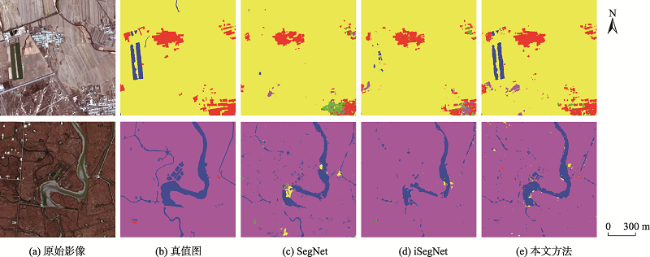
图12 各算法25%样本局部分类结果Fig. 12 Local classification results of 25% samples for each methods |
表2 25%样本下分类定量评价结果比较Tab. 2 Quantitative evaluation results of 25% samples for different methods |
| 地物 | IoU | OA | Kappa | ||||
|---|---|---|---|---|---|---|---|
| 耕地 | 建筑用地 | 水体 | 湿地 | 养殖场 | |||
| SegNet | 0.8589 | 0.5492 | 0.7909 | 0.7840 | 0.7240 | 0.8886 | 0.8438 |
| iSegNet | 0.8820 | 0.5745 | 0.8306 | 0.8099 | 0.7151 | 0.9028 | 0.8637 |
| 本文方法 | 0.8973 | 0.7004 | 0.8734 | 0.8354 | 0.8504 | 0.9267 | 0.8983 |
| [1] |
廖小罕, 肖青, 张颢. 无人机遥感:大众化与拓展应用发展趋势[J]. 遥感学报, 2019, 23(6):1046-1052.
[
|
| [2] |
王一达, 沈熙玲, 谢炯, 等. 遥感图像分类方法研究综述[J]. 遥感信息, 2006, 21(5):67-71.
[
|
| [3] |
骆剑承, 王钦敏, 马江洪, 等. 遥感图像最大似然分类方法的EM改进算法[J]. 测绘学报, 2002, 31(3):234-239.
[
|
| [4] |
朱建华, 刘政凯, 俞能海. 一种多光谱遥感图象的自适应最小距离分类方法[J]. 中国图象图形学报, 2000, 5(1):24-27.
[
|
| [5] |
张锦水, 何春阳, 潘耀忠, 等. 基于SVM的多源信息复合的高空间分辨率遥感数据分类研究[J]. 遥感学报, 2006, 10(1):49-57.
[
|
| [6] |
王慧贤, 靳惠佳, 王娇龙, 等. k均值聚类引导的遥感影像多尺度分割优化方法[J]. 测绘学报, 2015, 44(5):526-532.
[
|
| [7] |
沈照庆, 舒宁, 龚衍, 等. 基于改进模糊ISODATA算法的遥感影像非监督聚类研究[J]. 遥感信息, 2008, 23(5):28-32.
[
|
| [8] |
|
| [9] |
|
| [10] |
杨建宇, 周振旭, 杜贞容, 等. 基于SegNet语义模型的高分辨率遥感影像农村建设用地提取[J]. 农业工程学报, 2019, 35(5):251-258.
[
|
| [11] |
朱岩彬, 徐启恒, 杨俊涛, 等. 基于全卷积神经网络的高分辨率航空影像建筑物提取方法研究[J]. 地理信息世界, 2020, 27(2):101-106.
[
|
| [12] |
|
| [13] |
李冠东, 张春菊, 王铭恺, 等. 卷积神经网络迁移的高分影像场景分类学习[J]. 测绘科学, 2019, 44(4):116-123,174.
[
|
| [14] |
滕文秀, 温小荣, 王妮, 等. 基于深度迁移学习的无人机高分影像树种分类与制图[J]. 激光与光电子学进展, 2019, 56(7):277-286.
[
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}