
基于多源空间数据和随机森林模型的长沙市茶颜悦色门店选址与预测研究
|
黄 钦(1995— ),男,湖北神农架人,硕士生,主要从事空间数据挖掘与机器学习。E-mail: 1182674026@qq.com |
收稿日期: 2021-08-16
修回日期: 2021-09-17
网络出版日期: 2022-06-25
基金资助
国家自然科学基金项目(41171342)
湖南省教育厅重点项目(17A127)
版权
Location Selection and Prediction of SexyTea Store in Changsha City based on Multi-source Spatial Data and Random Forest Model
Received date: 2021-08-16
Revised date: 2021-09-17
Online published: 2022-06-25
Supported by
National Natural Science Foundation of China(41171342)
Key Project of Hunan Provincial Education Department(17A127)
Copyright
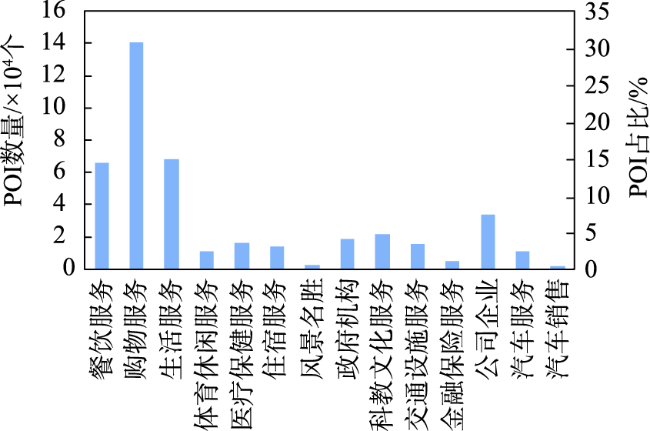
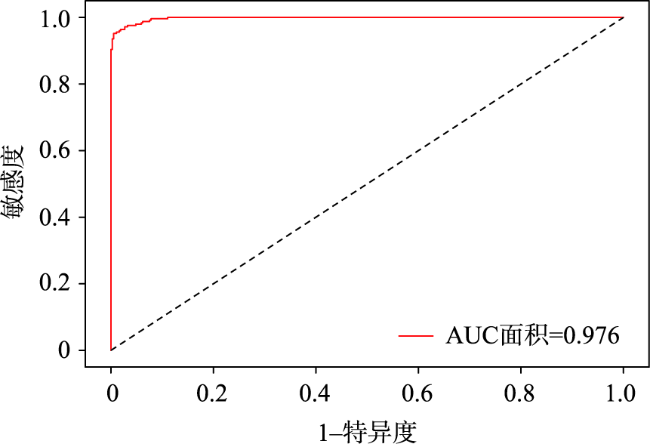
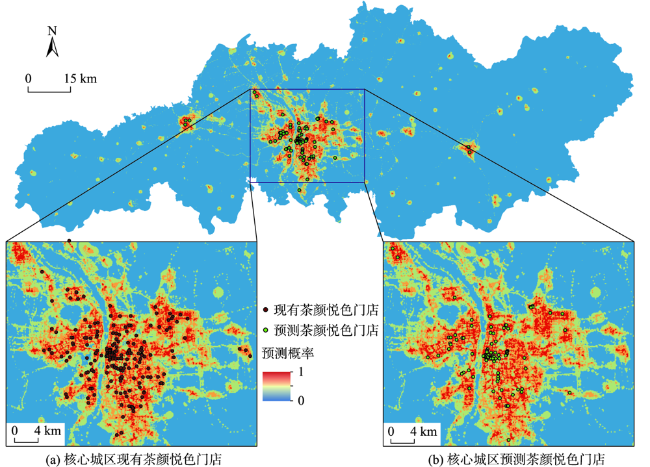
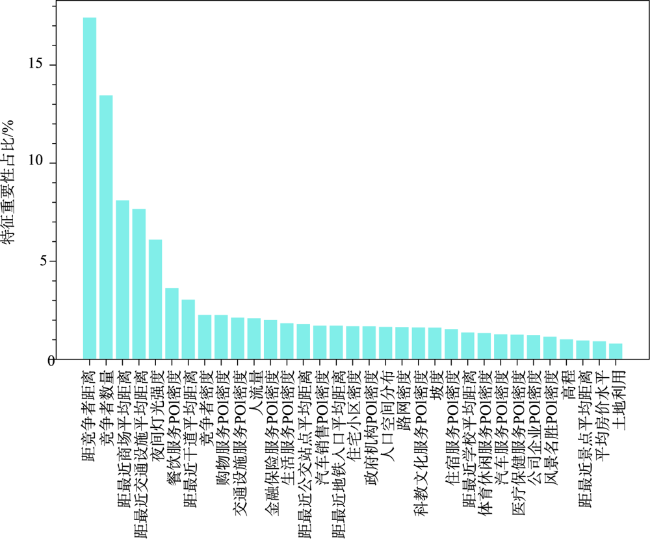
茶颜悦色作为中国本土奶茶品牌,将中国传统茶文化与时尚元素相结合,融入浓郁中国风,成为来长旅游者打卡必喝的一种奶茶饮品。探索其空间分布并对其门店选址适宜性进行评估对于优化门店布局、促进经济发展和提升旅游服务水平等具有重要的实际意义。本文基于高德地图API爬取长沙市茶颜悦色POI,运用平均最近邻指数、地理集中指数、不平衡指数、标准差椭圆、核密度估计等方法分析其空间格局,在此基础上融合多源异构空间数据选取一系列影响其空间分布的指示因子并运用随机森林模型对其门店布局适宜性开展实证研究。分析结果表明:① 长沙市茶颜悦色空间分布整体上为集聚型(ANN=0.354,G=40.283),围绕城市核心商圈集聚分布,形成了“一超多核”的空间格局;② 随机森林模型优化后的平均测试精度为92.18%,OOB测试精度为93.45%,其评价结果能够准确反映长沙市茶颜悦色门店选址适宜性与空间分布的异质性;③ 茶颜悦色选址适宜性结果表明,长沙市核心商圈内适宜性概率整体较高,存在明显的高值集聚现象,符合弗里德曼“中心-外围”理论。若将各商圈抽象为不同等级的中心地,其所提供的服务职能和影响范围受到空间距离衰减作用的影响,在空间分布上符合地理学第一定律;④ 特征重要性排序结果显示竞争环境、交通区位和社会经济发展因素对模型的贡献率较大,这与最小差异化准则强调集聚效应和传统商业选址强调区位选择相得益彰,因此在进行门店选址时可以重点考虑此类因素。本研究融合多源空间数据运用数据挖掘技术解决选址问题的方法和结论可以为茶颜悦色门店选址和空间布局提供参考和借鉴。
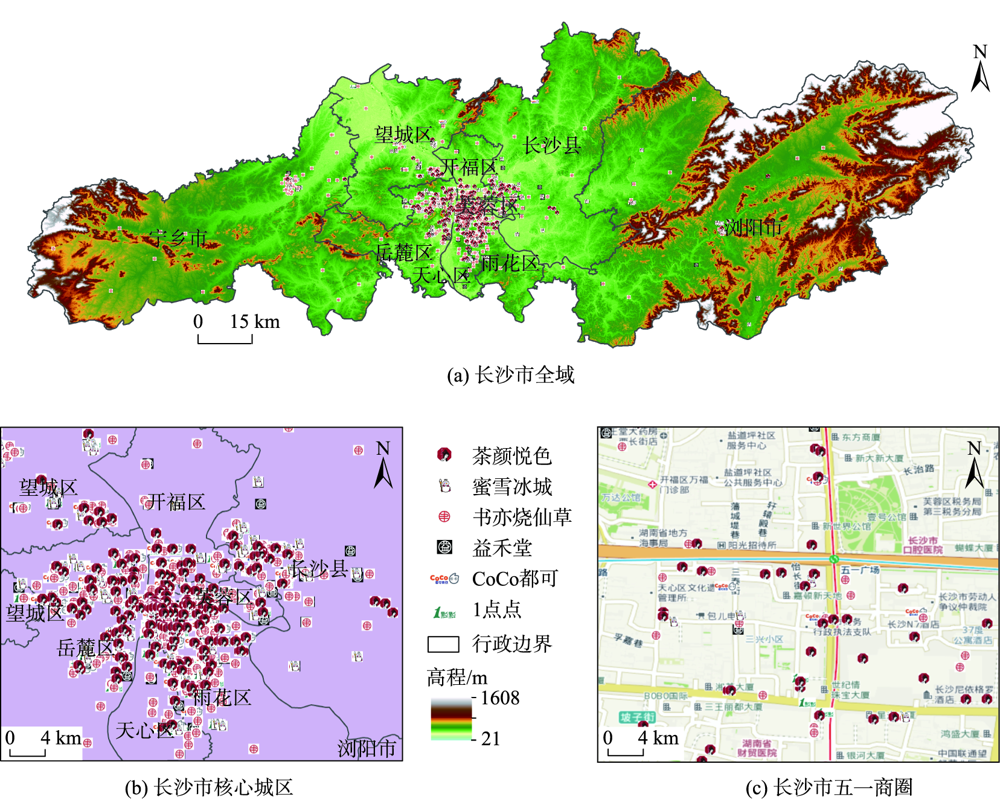
黄钦 , 杨波 , 徐新创 , 郝汉舟 , 梁莉莉 , 王敏 . 基于多源空间数据和随机森林模型的长沙市茶颜悦色门店选址与预测研究[J]. 地球信息科学学报, 2022 , 24(4) : 723 -737 . DOI: 10.12082/dqxxkx.2022.210478
SexyTea, as a local milk tea brand in China, combines traditional Chinese tea culture with fashion elements and incorporates a strong Chinese style, making it a must-drink milk tea drink for tourists who visit Changsha. Exploring its spatial distribution and evaluating the suitability of its store location is of great practical significance for optimizing store layout, promoting economic development, and improving tourism service level. This article is based on the API of AMAP to crawl the SexyTea POI in Changsha City, and the spatial pattern is analyzed using the average nearest neighbor index, geographic concentration index, unbalanced index, standard deviation ellipse, kernel density estimation, and other methods. We integrate multi-source heterogeneous spatial data to select a series of factors that affect its spatial distribution and use the random forest model to evaluate the suitability of the store layout. The analysis results show that: ① The spatial distribution of SexyTea in Changsha is agglomerated as a whole (ANN=0.558, G=40.283), clustered around the city's core business clusters, forming a spatial pattern of "one super-multi-core"; ② The average test accuracy after optimization of the random forest model is 92.18%, and the OOB test accuracy is 93.45%. The evaluation results can accurately reflect the suitability and spatial distribution heterogeneity of the SexyTea store in Changsha City; ③ SexyTea location suitability results show that the suitability probability in the core business clusters of Changsha City is generally high, and there is an obvious high-value agglomeration phenomenon, which is in line with Friedman's "center-periphery" theory. If the business clusters are stratified into centers of different levels, the service functions and scope of influence provided by them will be affected by the attenuation of spatial distance, and the spatial distribution conforms to the Tobler's First Law of Geography; ④ The ranking result of feature importance shows that competitive environment, transportation location, and socio-economic development have the greatest contribution to the model. This is complementary to the minimum difference criterion emphasizing agglomeration effect and traditional commercial location strategy emphasizing location selection. Therefore, such factors can be considered when selecting store locations. The methods and conclusions of this research that integrate multi-source spatial data and use data mining technology to solve the location problem can provide reference for the location and spatial layout of SexyTea stores.
表1 本文数据来源Tab. 1 Data source for this article |
| 数据类型 | 数据年份 | 数据来源 | 数据描述 |
|---|---|---|---|
| POI数据 | 2020 | 高德地图API数据开放接口(https://lbs.amap.com/) | 通过Python网络爬虫技术调用高德地图API爬取,共计14个类别429 839条数据 |
| 人口数据 | 2020 | WorldPop全球高分辨率人口计划项目数据集(www.worldpop.org) | 空间分辨率为3弧度(在赤道处约为100 m) |
| 百度热力图数据 | 2020 | 百度地图API 数据开放接口(http://api.map.baidu.com/lbsapi/cloud/index.htm) | 反映人流量空间分布差异 |
| 路网数据 | 2020 | OpenStreetMap(https://www.openstreetmap.org) | 反映城市交通状况,计算加权路网密度 |
| DEM数据 | 2019 | NASA EARTH DATA (https://earthdata.nasa.gov/) | 空间分辨率为30 m,反映区域高程,也可用以计算坡度 |
| 土地利用数据 | 2020 | 地球大数据科学工程数据共享服务系统(http://data.casearth.cn/sdo/detail/5fbc7904819aec1ea2dd7061) | 空间分辨率为30 m,反映地表覆盖状况 |
| 房价数据 | 2020 | 房天下(https://cs.fang.com/) | 通过Python网络爬虫技术爬取,再经克里金插值[23]得到,用以近似代替城市各地租金水平 |
| 夜间灯光数据 | 2019 | 珞珈一号(http://59.175.109.173:8888/app/login.html) | 夜间灯光与二、三产业GDP具有高度相关性 |
| 行政区划数据 | 2020 | 湖南省国土资源规划院(http://www.hngtghy.com/) | 表征长沙市行政区划边界,通过矢量底图掩膜提取出各因子栅格 |
| 统计数据 | 2020 | 长沙市统计局(http://tjj.changsha.gov.cn/) | 反映城市社会经济、社会发展情况 |
表2 统计分析模型及其释义Tab. 2 Statistical analysis model and its interpretation |
| 模型名称 | 模型公式 | 模型释义 | 地理意义 | 编号 |
|---|---|---|---|---|
| 平均最近邻指数 | 为平均最近邻指数; 表示每个要素与最邻近要素之间的平均观测距离; 表示随机模式下要素间的预期平均距离 | <1时,要素分布趋势为集聚型; =1时为随机型; >1时为离散型 | (1) | |
| 地理集中指数 | 为地理集中指数; 为第 个区县内茶颜悦色门店的数量; 为茶颜悦色门店总数; 为长沙市区县数量 | 的取值介于0~100之间, 值越小,表明门店分布越分散; 值越高,则分布越集中 | (2) | |
| 不平衡指数 | 为不平衡指数; 为区县个数; 为各区县茶颜悦色门店数量在全市总数所占比重从小到大排序后,第 位的累计百分比 | 的取值介于0~1之间, 值越大表明不平衡性越高 | (3) | |
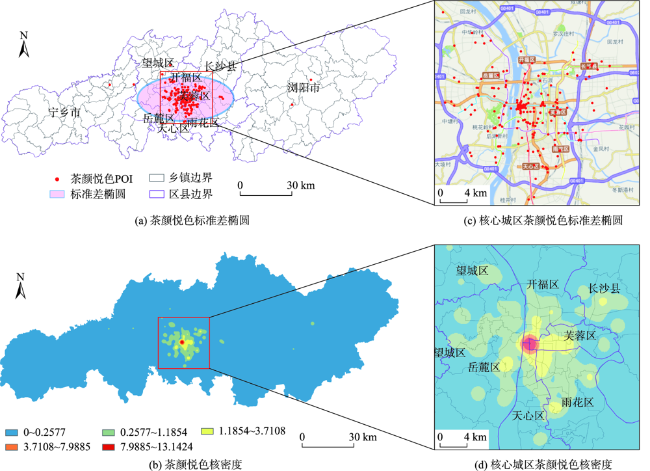
| 标准差椭圆 | 、 分别为标准差椭圆x、y轴方向上的轴长; 为茶颜悦色门店的空间坐标; 为门店的平均中心; 为门店总数 | 对地理要素的集中、离散和方向趋势进行定量描述,直观展现其空间分布的中心性及延展性 | (4) | |
| 核密度估计 | 为核密度函数;n为与空间位置x的距离小于或等于r的要素数;k为空间权重函数;r为距离衰减阈值;n为与位置x的距离小于或等于r的要素点数 | 用以测度点状要素在空间上的集聚状态,核密度值越大,表明其空间分布越密集 | (5) |
表3 长沙市茶颜悦色门店选址特征选择Tab. 3 Feature selection of the location of the SexyTea store in Changsha City |
| 影响因素 | 特征选取 | 特征释义 | 特征粒度 |
|---|---|---|---|
| 自然环境 | 高程 | 地形、地势是门店选址需要考虑的重要因素,海拔高度在一定程度上影响门店选址的适宜性[30] | -84~1595 m |
| 坡度 | 坡度影响着建筑选址,是经济发展的限制性因子 | 0~50.15° | |
| 土地利用 | 不同土地利用类型其环境承载力不同,通过分析土地使用情况可以排除不合适的区域和空置土地,进而优化门店选址[30] | 涉及11个土地利用类别 | |
| 交通区位 | 路网密度 | 路网密度是衡量区域交通可达性的重要指标之一,商业集聚程度高的区域一般路网密度高[12] | 0~6.49 km/km2 |
| 距最近干道平均距离 | 城市交通可达性一般以干道为轴线向外围递减,商业门店趋于邻近交通干线布局[12] | 0~49.24 km | |
| 距最近地铁出入口平均距离 | 城市快速轨道交通可提高区域交通可达性,对商业集聚和人流产生正向的外部影响[12] | 0~114.31 km | |
| 距最近公交站点平均距离 | 公交站点提升区域交通可达性,会串联居民区和重要景点、商场等,促进人口空间流动[19] | 0~62.41 km | |
| 距最近交通设施平均距离 | 交通设施的空间分布可以在一定程度上反应城市的交通格局,城市发展水平高、人流量大的地方交通设施越完善 | 0~52.64 km | |
| 社会经济 | 平均房价水平 | 城市房价与居民平均收入水平正相关,居民收入水平越高,购买力越强,房价就越高[31] | 0~30 852 元/m2 |
| 夜间灯光强度 | 夜间灯光与国民生产总值GDP或区域生产总值GRP存在较高的相关性[32],门店布局往往选择经济发展程度高的区域 | 辐射校正后的DN值介于0~0.044 | |
| 人口空间分布 | 门店布局与人口空间分布存在明显的相互吸引效应,人口规模越大,消费需求的积累越容易产生,市场潜力越大[12] | 0~2974.72 人/单位格网 | |
| 住宅小区密度 | 商业与房地产业在空间上高度相关,茶颜悦色作为消费性服务业与城市居住用地具有地域共生性[12] | 核密度值介于0~85.47 | |
| 客源市场 | 人流量 | 人流量对商业空间分布具有显著的正向效应[13],是影响商业布局的首要因素之一 | 分为8个等级 |
| 距最近景点平均距离 | 在大多数城市中,景点、学校和商业机构等在选址上具有高度相关性[33],其强大吸引力是影响人员到访重要的外部因素 | 0~53.12 km | |
| 距最近学校平均距离 | 0~55.19 km | ||
| 距最近商场平均距离 | 0~64.96 km | ||
| 竞争环境 | 竞争者数量[3] | 本文将不同品牌连锁奶茶店(蜜雪冰城、书亦烧仙草、益禾堂、CoCo都可等)认为是茶颜悦色门店布局潜在的竞争者,通过计算每个格网中竞争者的数量、300 m(Chen等[34])范围内的竞争者密度与距竞争者的欧氏距离来衡量竞争强度 | 0~9个/单位格网 |
| 竞争者密度[34] | 核密度值介于0~41.46 | ||
| 距竞争者距离[35] | 0~57.12 km | ||
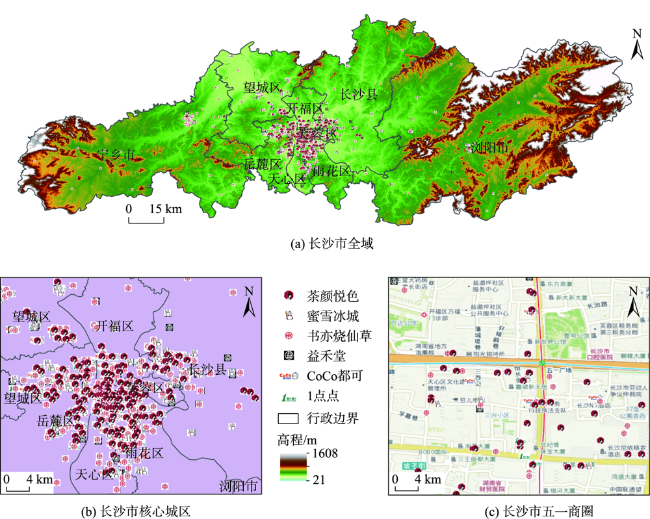
| 城市功能结构 | 各类POI密度[10] | POI数据可以有效反映城市内部功能结构[19],本文通过计算14类POI核密度以反映其空间分布模式和集聚特征 | 涉及14个类别POI核密度 |
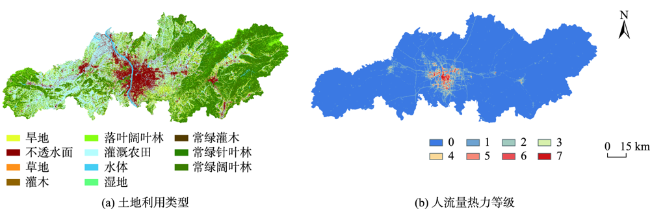
图4 2020年长沙市土地利用及人流量空间分布Fig. 4 Spatial distribution of land use and human flow in Changsha City in 2020 |
| [1] |
石忆邵, 杨凤龙. 上海星巴克咖啡店的空间分布特征及其影响因素[J]. 经济地理, 2018,38(5):126-132.
[
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
金安楠, 李钢, 王建坡, 等. 社区化新零售的布局选址与优化发展研究——以南京市盒马鲜生为例[J]. 地理科学进展, 2020,39(12):2013-2027.
[
|
| [11] |
方远平, 闫小培, 毕斗斗. 1980 年以来我国城市商业区位研究述评[J]. 热带地理, 2007(5):435-440.
[
|
| [12] |
王珏晗, 周春山. 广州市商业型健身房空间分布及其影响因素[J]. 热带地理, 2018,38(1):120-130.
[
|
| [13] |
杨秋彬, 何丹, 高鹏. 上海市体验型商业空间格局及其影响因素[J]. 城市问题, 2018(3):34-41.
[
|
| [14] |
汪凡, 林玥希, 汪明峰. 第三空间还是无限场景:新零售的区位选择与影响因素研究[J]. 地理科学进展, 2020,39(9):1522-1531.
[
|
| [15] |
朱涛. 零售企业选址的博弈分析[J]. 商业经济与管理, 2004(7):18-21.
[
|
| [16] |
戴晓爱, 仲凤呈, 兰燕, 等. GIS与层次分析法结合的超市选址研究与实现[J]. 测绘科学, 2009,34(1):184-186.
[
|
| [17] |
翟书颖, 郝少阳, 杨琪, 等. 多源异构数据融合的智能商业选址推荐算法[J]. 现代电子技术, 2019,42(14):182-186.
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
张嘉琪, 杜开虎, 任书良, 等. 多源空间大数据场景下的家装品牌线下广告选址布局研究[J/OL]. 武汉大学学报•信息科学版):1-14[2021-09-09]. https://doi.org/10.13203/j.whugis20190468.
[
|
| [22] |
汪晓春, 熊峰, 王振伟, 等. 基于POI大数据与机器学习的养老设施规划布局——以武汉市为例[J]. 经济地理, 2021,41(6):49-56.
[
|
| [23] |
|
| [24] |
|
| [25] |
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
姚尧, 任书良, 王君毅, 等. 卷积神经网络和随机森林的城市房价微观尺度制图方法[J]. 地球信息科学学报, 2019,21(2):168-177.
[
|
| [32] |
李德仁, 张过, 沈欣, 等. 珞珈一号01星夜光遥感设计与处理[J]. 遥感学报, 2019,23(6).
[
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
周超, 方秀琴, 吴小君, 等. 基于三种机器学习算法的山洪灾害风险评价[J]. 地球信息科学学报, 2019,21(11):1679-1688.
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}