
基于迭代局部搜索的区划问题算法研究
|
孔云峰(1967— ),男,河南洛阳人,教授,主要从事空间分析、空间优化等研究。E-mail: yfkong@henu.edu.cn |
收稿日期: 2022-03-30
修回日期: 2022-05-10
网络出版日期: 2022-11-25
基金资助
国家自然科学基金项目(41871307)
An Improved Iterative Local Search Algorithm for the Regionalization Problem
Received date: 2022-03-30
Revised date: 2022-05-10
Online published: 2022-11-25
Supported by
National Natural Science Foundation of China(41871307)
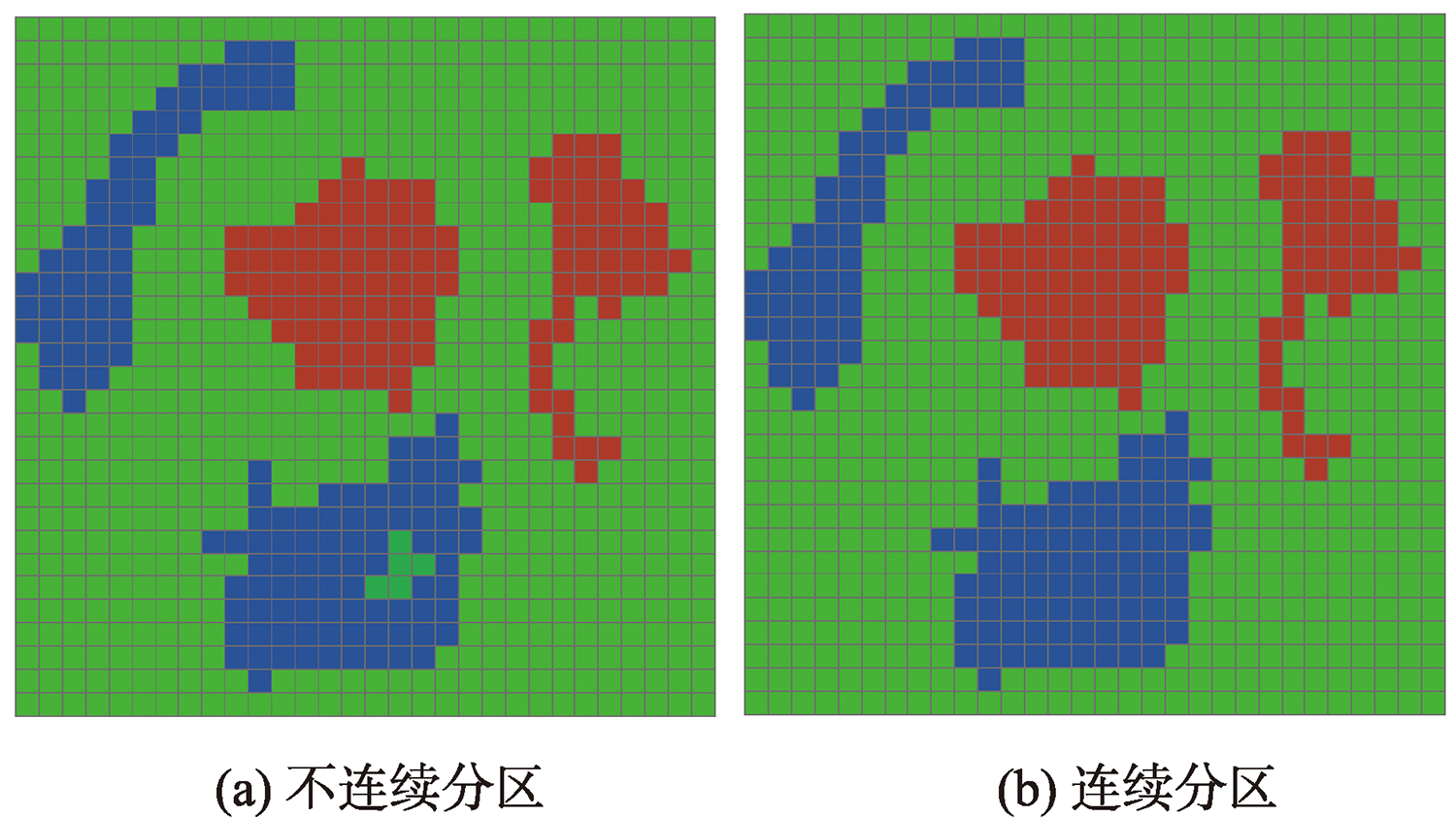
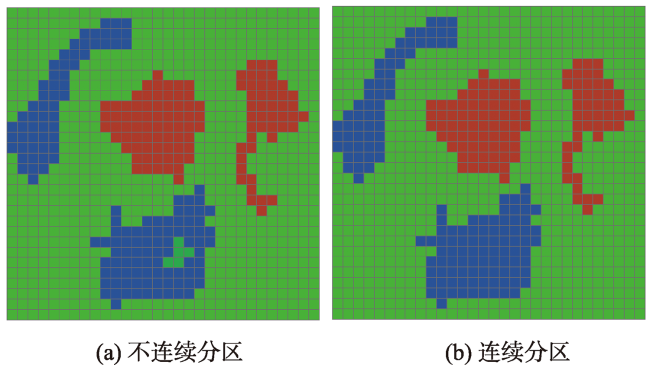
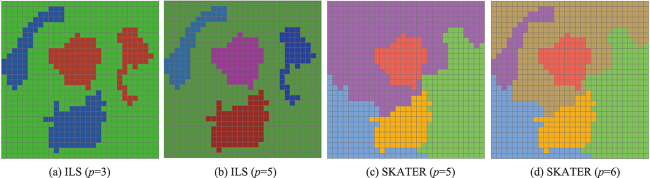
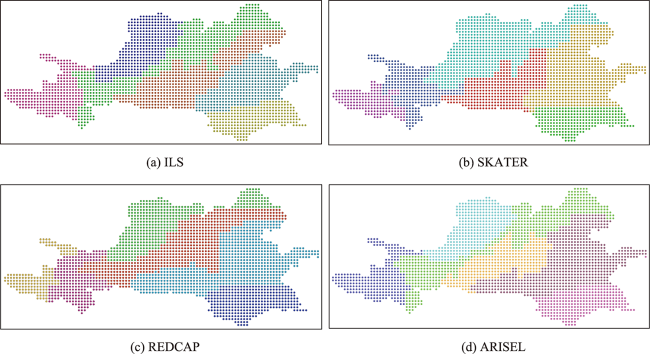
区划问题是将特定地理区域划分为若干空间连续的分区,满足分区内差异最小和分区间差异最大这一基本原则,广泛应用于地理、环境、生态、经济、农业、城市等领域。1960s以来,学者尝试建立各种区划问题数学模型,设计了一系列的求解算法,代表性的算法主要有:AZP、ARISEL、SKATER和REDCAP。本文提出了一个基于迭代局部搜索(ILS)的区划问题算法,进一步提升算法性能。该算法主要机制包括:邻域单元移动搜索改进分区质量;参照中心单元快速计算分区方差,提升算法速度;使用扰动机制跳出当前解局部最优状态;更新分区中心点提升分区方案目标值;使用群搜索探索更大的解空间;以及算法各步骤中通过分区空间连续判断和破碎修复保持分区空间连续。55个基准案例测试表明: ILS算法求解质量优于ARISEL和SKATER算法。一个多指标气候分区实验也表明: ILS算法求解质量优于SKATER、REDCAP和ARISEL算法。
孔云峰 . 基于迭代局部搜索的区划问题算法研究[J]. 地球信息科学学报, 2022 , 24(9) : 1730 -1741 . DOI: 10.12082/dqxxkx.2022.220139
Regionalization is to divide a large geographic area into a number of homogenous and spatially contiguous regions. It has been widely used in fields such as geography, cartography, ecology, environment management, socio-economy, and urban planning. Since the general regionalization problem has been proven to be NP-Hard, various models and solution methods for regionalization have been proposed since 1960s. The regionalization methods can be classified into four categories: exact, clustering-based, heuristic, and tree-based. However, the commonly used regionalization algorithms, such as AZP, AZP-SA, AZP-Tabu, ARISEL, SKATER, and REDCAP, are difficult to solve the problem in an effective and efficient manner simultaneously. An improved iterative local search algorithm is proposed in this paper for the regionalization problem. There are six key mechanisms in the new algorithm: the search of moving boundary units to improve the current solution, the center-based approach to accelerate the computation of solution objective, the solution perturbation to escape from the state of local optimum, the frequent update of regional centers to reevaluate the solution, the population-based search to explore larger solution space, and the region repair to keep spatially contiguous regions. The regionalization experimentations on 55 benchmark instances show that the proposed algorithms outperform ARISEL algorithm and SKATER algorithm in terms of sum-squared errors and adjusted Rand index. A case study of the climate regionalization using 60 attributes illustrates that the improved ILS is effective to delineate climate regions, and outperforms the well-known algorithms such as SKATER, REDCAP, and ARISEL.
| 算法1 改进ILS算法 |
|---|
| 参数:群大小 (psize),破环强度(strength),连续未更新最好解循环数(mloops)。 1. P = GenerateInitialSolutions(psize); 2. sbest=Best(P); 3. notImpr=0; 4. While notImpr < mloops: 5. Select a solution s from P randomly; 6. s′=Perturbation (s, strength); 7. s′′=LocalSearch(s′); 8. s*=UpdateCenters(s′′); 9. If f(s*)<f(sbest): sbest=s*, notImpr=0; 10. else: notImpr+=1; 11. P =UpdatePopulation (P, s*); 12. Output sbest |
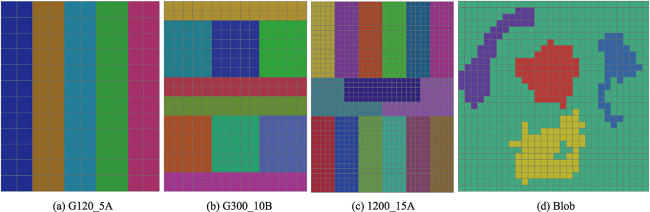
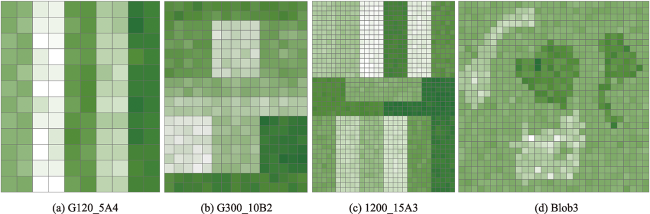
表1 基准测试案例特征Tab. 1 Characteristics of The benchmark instances |
| 地图名称 | 网格大小 | 分区形状 | 分区数量/个 | 属性数值模拟参数 | 产生区划方案数量/件 | 数值模拟次数/次 |
|---|---|---|---|---|---|---|
| G120 | 10 12 | A, B | 5, 10, 15 | 2, 3, 4 | 18 | 100 |
| G300 | 15 20 | A, B | 5, 10, 15 | 2, 3, 4 | 18 | 100 |
| G1200 | 30 40 | A, B | 5, 10, 15 | 2, 3, 4 | 18 | 100 |
| Blob | 30 30 | 不规则 | 4 | 3 | 1 | 100 |
表2 基准案例ARI指数和R2指数均值统计Tab. 2 ARI and R2 indexes from 55 benchmark instances |
| 案例名称 | 100个ARI指数均值 | 100个R2指数均值 | ||||
|---|---|---|---|---|---|---|
| ILS | SKATER | ARISEL | ILS | SKATER | ARISEL | |
| G120_5A2 | 0.8037 | 0.6650 | 0.7170 | 0.9010 | 0.8696 | 0.9014 |
| G120_5A3 | 0.9442 | 0.7949 | 0.9160 | 0.9523 | 0.9151 | 0.9523 |
| G120_5A4 | 0.9788 | 0.9123 | 0.9715 | 0.9711 | 0.9526 | 0.9708 |
| G120_5B2 | 0.8609 | 0.7483 | 0.7348 | 0.9027 | 0.9022 | 0.9124 |
| G120_5B3 | 0.9586 | 0.8842 | 0.9267 | 0.9520 | 0.9486 | 0.9529 |
| G120_5B4 | 0.9866 | 0.9245 | 0.9791 | 0.9707 | 0.9658 | 0.9709 |
| G120_10A2 | 0.8518 | 0.8007 | 0.7758 | 0.9718 | 0.9742 | 0.9734 |
| G120_10A3 | 0.9627 | 0.8817 | 0.8849 | 0.9884 | 0.9854 | 0.9862 |
| G120_10A4 | 0.9871 | 0.9258 | 0.9526 | 0.9932 | 0.9910 | 0.9923 |
| G120_10B2 | 0.8515 | 0.7646 | 0.7564 | 0.9736 | 0.9743 | 0.9731 |
| G120_10B3 | 0.9627 | 0.8839 | 0.8900 | 0.9883 | 0.9864 | 0.9868 |
| G120_10B4 | 0.9912 | 0.9342 | 0.9537 | 0.9932 | 0.9915 | 0.9922 |
| G120_15A2 | 0.8504 | 0.8063 | 0.7651 | 0.9864 | 0.9890 | 0.9860 |
| G120_15A3 | 0.9493 | 0.8886 | 0.8685 | 0.9939 | 0.9940 | 0.9928 |
| G120_15A4 | 0.9862 | 0.9313 | 0.9233 | 0.9966 | 0.9963 | 0.9961 |
| G120_15B2 | 0.8505 | 0.8064 | 0.7789 | 0.9876 | 0.9879 | 0.9850 |
| G120_15B3 | 0.9372 | 0.8813 | 0.8667 | 0.9940 | 0.9933 | 0.9925 |
| G120_15B4 | 0.9865 | 0.9164 | 0.9242 | 0.9971 | 0.9959 | 0.9959 |
| G300_5A2 | 0.8978 | 0.7394 | 0.8164 | 0.8971 | 0.8613 | 0.9004 |
| G300_5A3 | 0.9692 | 0.8906 | 0.9561 | 0.9498 | 0.9258 | 0.9504 |
| G300_5A4 | 0.9906 | 0.9444 | 0.9879 | 0.9707 | 0.9594 | 0.9708 |
| G300_5B2 | 0.9015 | 0.8169 | 0.7978 | 0.8982 | 0.8917 | 0.9030 |
| G300_5B3 | 0.9679 | 0.9176 | 0.9520 | 0.9499 | 0.9457 | 0.9504 |
| G300_5B4 | 0.9907 | 0.9547 | 0.9884 | 0.9707 | 0.9665 | 0.9708 |
| G300_10A2 | 0.8686 | 0.7593 | 0.8036 | 0.9682 | 0.9505 | 0.9606 |
| G300_10A3 | 0.9616 | 0.8436 | 0.8913 | 0.9874 | 0.9735 | 0.9819 |
| G300_10A4 | 0.9911 | 0.8728 | 0.9614 | 0.9929 | 0.9762 | 0.9909 |
| G300_10B2 | 0.8674 | 0.8315 | 0.7849 | 0.9701 | 0.9691 | 0.9679 |
| G300_10B3 | 0.9730 | 0.9151 | 0.8973 | 0.9875 | 0.9851 | 0.9848 |
| G300_10B4 | 0.9942 | 0.9168 | 0.9748 | 0.9929 | 0.9881 | 0.9921 |
| G300_15A2 | 0.8588 | 0.8351 | 0.7836 | 0.9853 | 0.9854 | 0.9814 |
| G300_15A3 | 0.9621 | 0.8945 | 0.8686 | 0.9939 | 0.9924 | 0.9911 |
| G300_15A4 | 0.9907 | 0.9242 | 0.9330 | 0.9967 | 0.9951 | 0.9954 |
| G300_15B2 | 0.8771 | 0.8465 | 0.7951 | 0.9842 | 0.9868 | 0.9845 |
| G300_15B3 | 0.9684 | 0.8995 | 0.8739 | 0.9940 | 0.9930 | 0.9921 |
| G300_15B4 | 0.9931 | 0.9188 | 0.9241 | 0.9968 | 0.9949 | 0.9956 |
| G1200_5A2 | 0.9602 | 0.7946 | 0.9015 | 0.8929 | 0.8544 | 0.8913 |
| G1200_5A3 | 0.9863 | 0.9065 | 0.9817 | 0.9488 | 0.9218 | 0.9489 |
| G1200_5A4 | 0.9949 | 0.9407 | 0.9944 | 0.9703 | 0.9449 | 0.9703 |
| G1200_5B2 | 0.9548 | 0.8973 | 0.8878 | 0.8920 | 0.8854 | 0.8939 |
| G1200_5B3 | 0.9876 | 0.9702 | 0.9755 | 0.9487 | 0.9469 | 0.9480 |
| 案例名称 | 100个ARI指数均值 | 100个R2指数均值 | ||||
| ILS | SKATER | ARISEL | ILS | SKATER | ARISEL | |
| G1200_5B4 | 0.9963 | 0.9849 | 0.9946 | 0.9702 | 0.9688 | 0.9702 |
| G1200_10A2 | 0.8860 | 0.7842 | 0.8261 | 0.9618 | 0.9467 | 0.9564 |
| G1200_10A3 | 0.9809 | 0.8533 | 0.9260 | 0.9865 | 0.9684 | 0.9801 |
| G1200_10A4 | 0.9952 | 0.8702 | 0.9683 | 0.9926 | 0.9728 | 0.9904 |
| G1200_10B2 | 0.9087 | 0.9008 | 0.8428 | 0.9677 | 0.9687 | 0.9681 |
| G1200_10B3 | 0.9861 | 0.9499 | 0.9094 | 0.9866 | 0.9850 | 0.9839 |
| G1200_10B4 | 0.9969 | 0.9620 | 0.9629 | 0.9926 | 0.9906 | 0.9912 |
| G1200_15A2 | 0.8741 | 0.8814 | 0.8089 | 0.9832 | 0.9850 | 0.9811 |
| G1200_15A3 | 0.9684 | 0.9153 | 0.8958 | 0.9932 | 0.9919 | 0.9906 |
| G1200_15A4 | 0.9928 | 0.9319 | 0.9321 | 0.9964 | 0.9949 | 0.9950 |
| G1200_15B2 | 0.8917 | 0.9148 | 0.8099 | 0.9834 | 0.9860 | 0.9824 |
| G1200_15B3 | 0.9777 | 0.9322 | 0.8911 | 0.9934 | 0.9928 | 0.9917 |
| G1200_15B4 | 0.9929 | 0.9392 | 0.9329 | 0.9964 | 0.9953 | 0.9953 |
| Blob | 0.9409 | 0.9357 | 0.8976 | 0.8700 | 0.8454 | 0.8646 |
| 平均值 | 0.9454 | 0.8789 | 0.8894 | 0.9696 | 0.9618 | 0.9686 |
表3 计算时间统计Tab. 3 Statistics of the computation times |
| 案例 | ARISEL | SKATER | ILS | 案例 | ARISEL | SKATER | ILS |
|---|---|---|---|---|---|---|---|
| G120_05A | 4.81 | 0.53 | 0.78 | G120_05B | 4.25 | 0.45 | 0.80 |
| G120_10A | 3.21 | 0.54 | 0.84 | G120_10B | 3.28 | 0.51 | 0.78 |
| G120_15A | 4.28 | 0.46 | 0.74 | G120_15B | 4.26 | 0.50 | 0.76 |
| G300_05A | 42.76 | 0.55 | 1.72 | G300_05B | 48.30 | 0.60 | 1.60 |
| G300_10A | 25.22 | 0.56 | 1.48 | G300_10B | 21.28 | 0.58 | 1.01 |
| G300_15A | 28.30 | 0.59 | 1.32 | G300_15B | 26.24 | 0.60 | 1.55 |
| G1200_5A | 1296.96 | 0.92 | 10.22 | G1200_5B | 1123.03 | 0.84 | 6.24 |
| G1200_10A | 740.46 | 0.94 | 7.16 | G1200_10B | 508.20 | 0.95 | 7.39 |
| G1200_15A | 481.21 | 0.95 | 5.49 | G1200_15B | 338.53 | 0.95 | 4.78 |
表4 研究区气候区划R2指标统计Tab. 4 The R2 indexes from the case study area |
| p | ILS | SKATER | REDCAP | ARISEL | ||||
|---|---|---|---|---|---|---|---|---|
| R2 | 时间/s | R2 | 时间/s | R2 | 时间/s | R2 | 时间/s | |
| 3 | 0.6874 | 36.5 | 0.6713 | 约1.0 | 0.6754 | 约2.0 | 0.6826 | 89.6 |
| 4 | 0.7958 | 37.9 | 0.7551 | 约1.0 | 0.7794 | 约2.0 | 0.7966 | 94.5 |
| 5 | 0.8290 | 34.9 | 0.7833 | 约1.0 | 0.8126 | 约2.0 | 0.8223 | 62.2 |
| 6 | 0.8547 | 33.2 | 0.8084 | 约1.0 | 0.8443 | 约2.0 | 0.8498 | 60.9 |
| 7 | 0.8694 | 37.8 | 0.8300 | 约1.0 | 0.8597 | 约2.0 | 0.8668 | 58.8 |
| 8 | 0.8848 | 31.6 | 0.8489 | 约1.0 | 0.8721 | 约2.0 | 0.8828 | 51.8 |
| 9 | 0.8942 | 32.1 | 0.8643 | 约1.0 | 0.8831 | 约2.0 | 0.8893 | 38.9 |
| 10 | 0.9045 | 47.2 | 0.8732 | 约1.0 | 0.8956 | 约2.0 | 0.9034 | 49.4 |
| 12 | 0.9172 | 46.6 | 0.8899 | 约1.0 | 0.9102 | 约2.0 | 0.9080 | 41.1 |
| 15 | 0.9301 | 35.4 | 0.9124 | 约1.0 | 0.9230 | 约2.0 | 0.9275 | 37.8 |
| [1] |
郑度, 葛全胜, 张雪芹, 等. 中国区划工作的回顾与展望[J]. 地理研究, 2005, 24(3):330-344.
[
|
| [2] |
刘燕华, 郑度, 葛全胜, 等. 关于开展中国综合区划研究若干问题的认识[J]. 地理研究, 2005, 24(3):321-329.
[
|
| [3] |
郑度, 欧阳, 周成虎. 对自然地理区划方法的认识与思考[J]. 地理学报, 2008, 63(6):563-573.
[
|
| [4] |
高江波, 黄姣, 李双成, 等. 中国自然地理区划研究的新进展与发展趋势[J]. 地理科学进展, 2010, 29(11):1400-1407.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
郭仁忠. 二维有序聚类方法及其在编制区划地图中的应用[J]. 武汉测绘学院学报, 1985, 10(2):21-29.
[
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}