
VoxTNT:基于多尺度Transformer的点云3D目标检测方法
作者贡献:Author Contributions
郑强文和吴升参与方法设计;郑强文和魏婧卉参与实验设计;郑强文完成实验操作;郑强文和魏婧卉参与实验结果分析;郑强文完成论文初稿;郑强文和吴升参与论文的写作和修改;吴升提供资助经费。所有作者均阅读并同意最终稿件的提交。
ZHENG Qiangwen and WU Sheng contributed to methodology design; ZHENG Qiangwen and WEI JInghui contributed to experimental design; ZHENG Qiangwen performed the experiments; ZHENG Qiangwen and WEI Jinghui analyzed the experimental results; ZHENG Qiangwen drafted the manuscript; ZHENG Qiangwen and WU Sheng contributed to writing and revising the manuscript; WU Sheng provided funding. All the authors have read the last version of manuscript and consented for submission.
|
郑强文(1990—),男,福建龙岩人,博士生,主要从自动驾驶领域感知技术研究。E-mail: 593161522@qq.com |
收稿日期: 2025-03-14
修回日期: 2025-04-18
网络出版日期: 2025-06-06
基金资助
公共数据开发利用科技创新团队(闽教科〔2023] 15 号)
VoxTNT: A Multi-Scale Transformer-based Approach for 3D Object Detection in Point Clouds
Received date: 2025-03-14
Revised date: 2025-04-18
Online published: 2025-06-06
Supported by
Fujian Provincal Program for Innovative Research Team, Fujian ES [2023] No.15.]
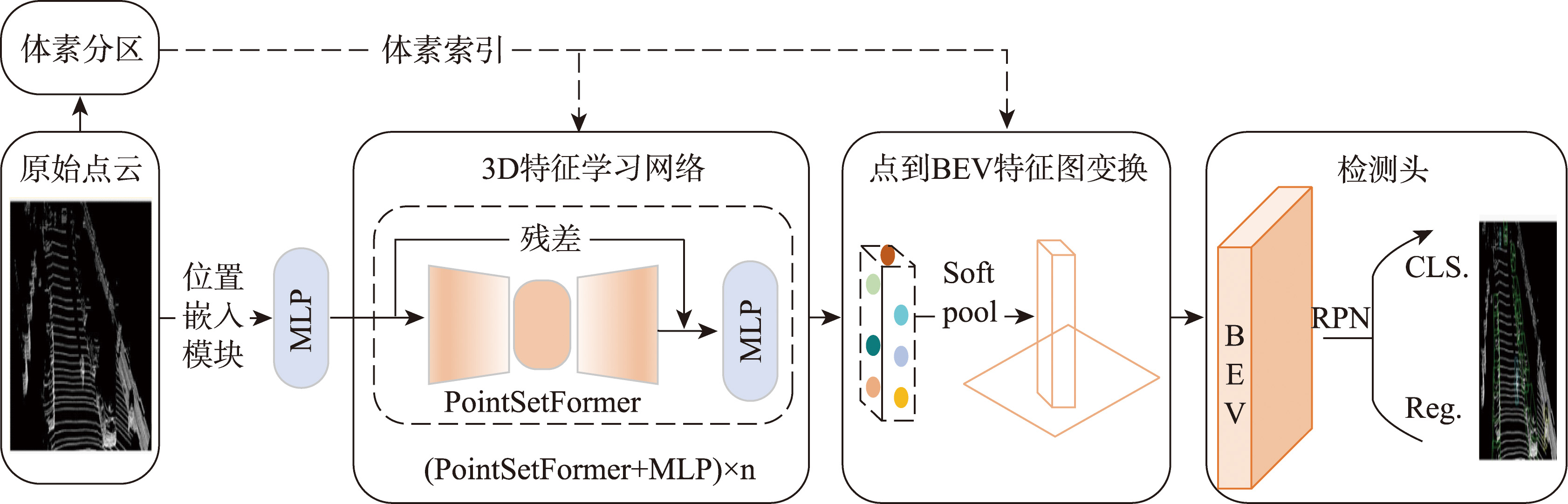
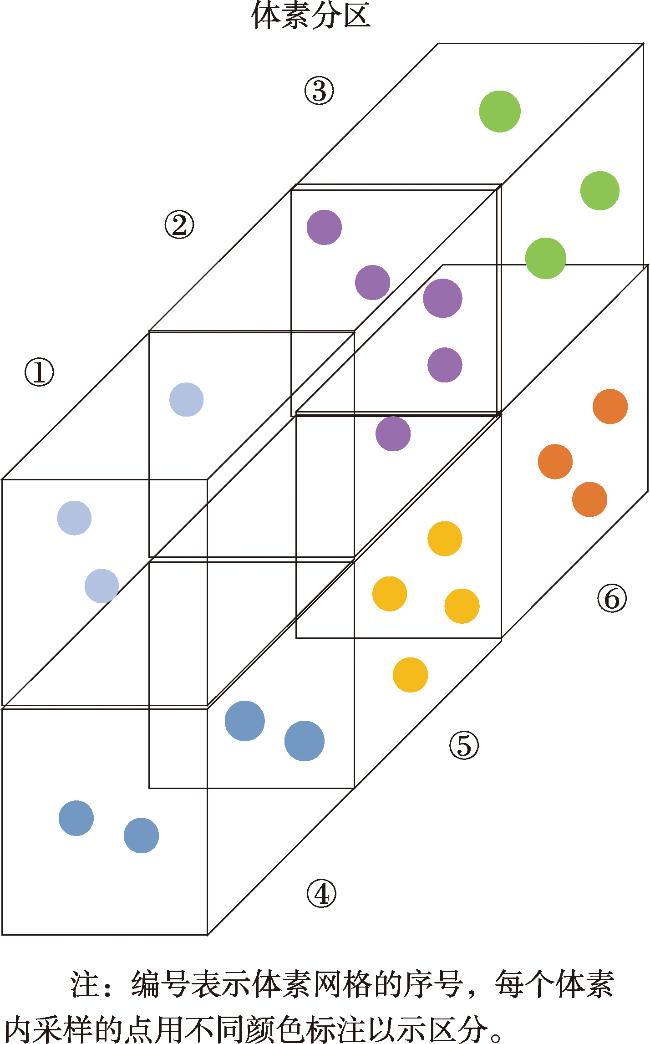
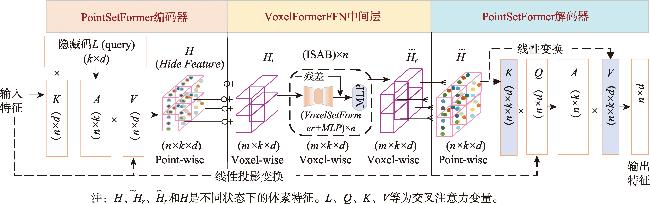
【背景】传统方法因静态感受野设计较难适配城市自动驾驶场景中汽车、行人及骑行者等目标的显著尺度差异,且跨尺度特征融合易引发层级干扰。【方法】针对自动驾驶场景中多类别、多尺寸目标的3D检测中跨尺度表征一致性的关键挑战,本研究提出基于均衡化感受野的3D目标检测方法VoxTNT,通过局部-全局协同注意力机制提升检测性能。在局部层面,设计了PointSetFormer模块,引入诱导集注意力模块(Induced Set Attention Block, ISAB),通过约简的交叉注意力聚合高密度点云的细粒度几何特征,突破传统体素均值池化的信息损失瓶颈;在全局层面,设计了VoxelFormerFFN模块,将非空体素抽象为超点集并实施跨体素ISAB交互,建立长程上下文依赖关系,并将全局特征学习计算负载从O(N 2)压缩至O(M 2)(M<<N, M为非空体素数量),规避了复杂的Transformer 直接使用在原始点云造成的高计算复杂度。该双域耦合架构实现了局部细粒度感知与全局语义关联的动态平衡,有效缓解固定感受野和多尺度融合导致的特征建模偏差。【结果】实验表明,该方法在KITTI数据集单阶段检测下,中等难度级别的行人检测精度AP(Average Precision)值达到59.56%,较SECOND基线提高约12.4%,两阶段检测下以66.54%的综合指标mAP(mean Average Precision)领先次优方法BSAODet的66.10%。同时,在WOD数据集中验证了方法的有效性,综合指标mAP达到66.09%分别超越SECOND和PointPillars基线7.7%和8.5%。消融实验进一步表明,均衡化局部和全局感受野的3D特征学习机制能显著提升小目标检测精度(如在KITTI数据集中全组件消融的情况下,中等难度级别的行人和骑行者检测精度分别下降10.8%和10.0%),同时保持大目标检测的稳定性。【结论】本研究为解决自动驾驶多尺度目标检测难题提供了新思路,未来将优化模型结构以进一步提升效能。
郑强文 , 吴升 , 魏婧卉 . VoxTNT:基于多尺度Transformer的点云3D目标检测方法[J]. 地球信息科学学报, 2025 , 27(6) : 1361 -1380 . DOI: 10.12082/dqxxkx.2025.250122
[Background] Traditional methods, due to their static receptive field design, struggle to adapt to the significant scale differences among cars, pedestrians, and cyclists in urban autonomous driving scenarios. Moreover, cross-scale feature fusion often leads to hierarchical interference. [Methodology] To address the key challenge of cross-scale representation consistency in 3D object detection for multi-class, multi-scale objects in autonomous driving scenarios, this study proposes a novel method named VoxTNT. VoxTNT leverages an equalized receptive field and a local-global collaborative attention mechanism to enhance detection performance. At the local level, a PointSetFormer module is introduced, incorporating an Induced Set Attention Block (ISAB) to aggregate fine-grained geometric features from high-density point clouds through reduced cross-attention. This design overcomes the information loss typically associated with traditional voxel mean pooling. At the global level, a VoxelFormerFFN module is designed, which abstracts non-empty voxels into a super-point set and applies cross-voxel ISAB interactions to capture long-range contextual dependencies. This approach reduces the computational complexity of global feature learning from O(N2) to O(M2) (where M << N, M is the number of non-empty voxels), avoiding the high computational complexity associated with directly applying complex Transformers to raw point clouds. This dual-domain coupled architecture achieves a dynamic balance between local fine-grained perception and global semantic association, effectively mitigating modeling bias caused by fixed receptive fields and multi-scale fusion. [Results] Experiments demonstrate that the proposed method achieves a single-stage detection Average Precision (AP) of 59.56% for moderate-level pedestrian detection on the KITTI dataset, an improvement of approximately 12.4% over the SECOND baseline. For two-stage detection, it achieves a mean Average Precision (mAP) of 66.54%, outperforming the second-best method, BSAODet, which achieves 66.10%. Validation on the WOD dataset further confirms the method’s effectiveness, achieving 66.09% mAP, which outperforms the SECOND and PointPillars baselines by 7.7% and 8.5%, respectively. Ablation studies demonstrate that the proposed equalized local-global receptive field mechanism significantly improves detection accuracy for small objects. For example, on the KITTI dataset, full component ablation resulted in a 10.8% and 10.0% drop in AP for moderate-level pedestrian and cyclist detection, respectively, while maintaining stable performance for large-object detection. [Conclusions] This study presents a novel approach to tackling the challenges of multi-scale object detection in autonomous driving scenarios. Future work will focus on optimizing the model architecture to further enhance efficiency.
表1 数据增强技术及使用概率一览表Tab. 1 List of data enhancement technologies and probability of use |
| 方法 | 是否使用 | 概率 |
|---|---|---|
| 全局缩放 | ✓ | 0.25 |
| 全局旋转 | ✓ | 0.25 |
| 全局翻转 | ✓ | 0.25 |
| 扰动 | ✓ | 0.25 |
表2 模型参数配置Tab. 2 Model parameter configuration |
| 检测 类别 | 体素大小 | 局部和全局 隐藏码(单阶段) | 点云范围 | 其他配置 |
|---|---|---|---|---|
| 汽车 | 0.32 | KITTI: (8, 16) | KITTI: X: [0 m, 69.12 m], Y: [-39.68 m, 39.68 m], Z: [-3 m, 1 m] WOD: X: [-74.24 m, 74.24 m], Y: [-74.24 m, 74.24 m], Z: [-2 m, 4 m] | 在KITTI中,使用前景图像分割范围 |
| 行人 | KITTI: 0.16 WOD: 0.32 | KITTI:(8, 8) | KITTI: X: [0 m, 69.12 m], Y: [-39.68 m, 39.68 m], Z: [-3 m, 1 m] WOD: X: [-74.24 m, 74.24 m], Y: [-74.24 m, 74.24 m], Z: [-2 m, 4 m] | 在KITTI中,使用前景图像分割范围 |
| 骑行者 | 0.32 | KITTI:(16, 16) | KITTI: X: [0 m, 69.12 m], Y: [-39.68 m, 39.68 m], Z: [-3 m, 1 m] WOD: X: [-74.24 m, 74.24 m], Y: [-74.24 m, 74.24 m], Z: [-2 m, 4m] | 在KITTI中,使用前景图像分割范围 |
表3 训练参数配置Tab. 3 Training parameter configuration |
| 检测类型 | 单阶段检测 | 两阶段检测 |
|---|---|---|
| 适用任务 | 通用检测 | 汽车/骑行者检测(结合 Voxel R-CNN) 行人检测(结合 Part-A2-free) |
| GPU硬件 | 1×RTX 4090 | 1×RTX 4090 |
| 训练周期 | 120 epochs | 汽车/骑行者:110 epochs 行人:100 epochs |
| 优化策略 | Adam | 沿用对应方法(Voxel R-CNN / Part-A2-free) |
| 学习率 | 初始 0.015,单周期衰减 | 初始 0.015,单周期衰减 |
| 动量阻尼范围 | [0.85, 0.95] | [0.85, 0.95] |
| 批大小 | 2 | 2 |
| 权重衰减 | 0.01 | 0.01 |
| 隐藏码设置 | - | KITTI:(16, 8) WOD: (4, 4) |
| 其他参数 | - | 汽车/骑行者:其他参数与 Voxel R-CNN[47]一致 行人:其他参数与 Part-A2-free[58]一致 |
表4 VoxTNT与经典的基线方法在KITTI验证集上单阶段3D检测对比Tab. 4 Comparison of VoxTNT and classic baseline methods for single-stage 3D detection on KITTI validation set |
| 方法 | 汽车 | 行人 | 骑行者 | mAP | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | ||||
| VoxelNet[10] | 81.97 | 65.46 | 62.85 | 57.86* | 53.42* | 48.87* | 67.17 | 47.65 | 45.11 | 58.93 | ||
| SECOND[22] | 88.61 | 78.62 | 77.22 | 56.55 | 52.98 | 47.73 | 80.58* | 67.15* | 63.10* | 68.06* | ||
| PointPillars[34] | 86.46* | 77.28 | 74.65 | 57.75 | 52.29 | 47.90 | 80.04 | 62.61 | 59.52 | 66.50 | ||
| VoxSeT[45] | 88.45 | 78.48 | 77.07 | 60.62 | 54.74 | 50.39 | 84.07 | 68.11 | 65.14 | 69.67 | ||
| VoxTNT(最佳组合) | 88.52 | 78.20* | 77.03* | 65.76 | 59.56 | 53.20 | 85.66 | 70.07 | 66.04 | 71.56 | ||
| 增量 | -0.09 | -0.42 | -0.35 | +5.14 | +4.82 | +2.81 | +1.59 | +1.96 | +0.90 | |||
| VoxTNT(统一参数模型) | 87.58 | 77.83 | 76.48 | 61.12 | 57.21 | 52.21 | 85.66 | 70.07 | 66.04 | 70.47 | ||
| 增量 | -1.03 | -0.79 | -0.90 | +0.50 | +2.47 | +1.82 | +1.59 | +1.96 | +0.90 | |||
注:排前3的方法分别以粗体、下划线和*号突出。 |
表5 VoxTNT与基于点云的主要方法在KITTI测试集上两阶段3D检测对比Tab. 5 Comparison of VoxTNT and Point Cloud based 3D Detection Methods in Two Stages on KITTI test set |
| 方法 | 汽车 | 行人 | 骑行者 | mAP | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | ||||
| PV-RCNN++[51] | 90.14 | 81.88 | 77.15* | - | - | - | 82.22 | 67.33 | 60.04 | - | ||
| DFAF3D[40] | 88.59 | 79.37 | 72.21 | 47.58 | 40.99 | 37.65 | 82.09 | 65.86 | 59.02 | 63.71 | ||
| BSAODet[41] | 88.89 | 81.74 | 77.14 | 51.71 | 43.63 | 41.09 | 82.65* | 67.79 | 60.26 | 66.10 | ||
| PG-RCNN[42] | 89.38* | 82.13* | 77.33 | - | - | - | 82.77 | 67.82* | 61.25 | - | ||
| PASS-PV-RCNN++[43] | 87.65 | 81.28 | 76.79 | 47.66 | 41.95 | 38.90* | 80.43 | 68.45 | 60.93* | 64.89* | ||
| PV-GNN_Cyc&Ped[52] | - | - | - | 48.78* | 42.00* | 36.91 | 78.58 | 62.54 | 55.28 | - | ||
| VoxTNT | 90.51 | 81.74* | 77.22 | 50.92 | 43.87 | 40.53 | 83.37 | 68.53 | 62.13 | 66.54 | ||
| 增量 | +0.37 | -0.39 | -0.11 | -0.79 | +0.24 | -0.56 | +0.60 | +0.08 | +0.88 | +0.44 | ||
注:排前3的方法分别以粗体、下划线和*号突出。 |
表6 VoxTNT与经典基线方法在WOD验证集上的单阶段3D检测对比(AP指标)Tab. 6 Comparison of VoxTNT and classical baseline methods for single-stage 3D detection on WOD validation set (AP metric) |
| 方法 | Vec_L1 | Vec_L2 | Ped_L1 | Ped_L2 | Cyc_L1 | Cyc_L2 | mAP |
|---|---|---|---|---|---|---|---|
| SECOND[22] | 70.96 | 62.58 | 65.23 | 57.22 | 57.13 | 54.97 | 61.35 |
| PointPillars[34] | 70.43 | 62.18 | 66.21 | 58.18 | 55.26 | 53.18 | 60.91 |
| CenterPoint[25] | 71.33 | 63.16 | 72.09 | 64.27 | 68.68 | 66.11 | 67.61 |
| VoxTNT | 69.74 | 61.32 | 72.49 | 63.86 | 65.76 | 63.35 | 66.09 |
注:排前2的方法分别以粗体和下划线突出。 |
表7 VoxTNT与经典基线方法在WOD验证集上的单阶段3D检测对比(APH指标)Tab. 7 Comparison of VoxTNT and classical baseline methods for single-stage 3D detection on WOD validation set (APH metric) |
| 方法 | Vec_L1 | Vec_L2 | Ped_L1 | Ped_L2 | Cyc_L1 | Cyc_L2 | mAPH |
|---|---|---|---|---|---|---|---|
| SECOND[22] | 70.34 | 62.02 | 54.24 | 47.49 | 55.62 | 53.53 | 57.21 |
| PointPillars[34] | 69.83 | 61.64 | 46.32 | 40.64 | 51.75 | 49.80 | 53.33 |
| CenterPoint[25] | 70.76 | 62.65 | 65.49 | 58.23 | 67.39 | 64.87 | 64.90 |
| VoxTNT | 69.19 | 60.83 | 62.29 | 54.71 | 64.46 | 62.09 | 57.21 |
注:排前2的方法分别以粗体和下划线突出。 |
表8 KITTI验证集上不同隐藏码组合的影响(V=0.16)Tab. 8 The impact of different combinations of latent codes on KITTI validation set (V=0.16) |
| 体素 尺寸 | Ll | Lg | 汽车 | 行人 | 骑行者 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | |||||
| V=0.16 | 8 8 16 16 | 8 16 8 16 | 87.58 88.57 86.92 87.60 | 76.16 77.12 75.74 76.15 | 70.32 71.15 70.50 70.76 | 65.76 62.42 63.79 63.16 | 59.56 56.20 57.90 57.17 | 53.20 50.95 52.63 51.97 | 84.43 82.34 81.23 86.00 | 66.08 65.97 64.14 68.99 | 63.86 62.43 60.69 64.70 | ||
| Range | 1.65 | 1.38 | 0.83 | 3.34 | 3.36 | 2.25 | 4.77 | 4.85 | 4.01 | ||||
| Avg | 87.67 | 76.29 | 70.68 | 63.78 | 57.71 | 52.19 | 83.50 | 66.30 | 62.92 | ||||
| MAD | 0.45 | 0.41 | 0.27 | 0.99 | 1.02 | 0.73 | 1.72 | 1.35 | 1.36 | ||||
| 最佳 组合 | 汽车(Ll=8、 Lg=16) 行人(Ll=8、 Lg=8) 骑行者(Ll=16、 Lg=16) | 88.57 | 77.12 | 71.15 | 65.76 | 59.56 | 53.20 | 86.00 | 68.99 | 64.70 | |||
表9 KITTI验证集上不同隐藏码的影响(V=0.32)Tab. 9 The impact of different combinations of latent codes on KITTI validation set (V=0.32) |
| 体素 尺寸 | Ll | Lg | 汽车 | 行人 | 骑行者 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | |||||
| V=0.32 | 8 8 16 16 | 8 16 8 16 | 88.20 88.52 87.81 87.58 | 78.20 78.20 78.06 77.83 | 76.92 77.03 76.66 76.48 | 60.21 58.01 62.27 61.12 | 55.68 53.29 56.58 57.21 | 51.07 48.93 51.98 52.12 | 84.93 85.06 81.97 85.66 | 66.51 71.03 64.90 70.07 | 63.51 64.95 62.24 66.04 | ||
| Range | 0.94 | 0.37 | 0.55 | 4.26 | 3.92 | 3.19 | 3.69 | 6.13 | 3.80 | ||||
| Avg | 88.03 | 78.07 | 76.77 | 60.40 | 55.69 | 51.03 | 84.41 | 68.12 | 64.19 | ||||
| MAD | 0.33 | 0.13 | 0.20 | 1.29 | 1.21 | 1.05 | 1.22 | 2.42 | 1.31 | ||||
| 最佳组合 | 汽车 (Ll=8、 Lg=16) 行人\骑行者 (Ll=16、 Lg=16) | 88.52 | 78.20 | 77.03 | 61.12 | 57.21 | 52.12 | 85.66 | 70.07 | 66.04 | |||
表10 在KITTI验证集上最佳检测方案和平均值对比Tab. 10 Comparison of best detection scheme and average value on KITTI validation set |
| 体素 尺寸 | 对比项 | 汽车 | 行人 | 骑行者 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | ||||
| V=0.16 | 最佳组合 | 88.57 | 77.12 | 71.15 | 65.76 | 59.56 | 53.20 | 86.00 | 68.99 | 64.70 | ||
| V=0.32 | 最佳组合 | 88.52 | 78.20 | 77.03 | 61.12 | 57.21 | 52.12 | 85.66 | 70.07 | 66.04 | ||
| 最佳: 汽车\骑行者(V=0.32) 行人(V=0.16) | 88.52 | 78.20 | 77.03 | 65.76 | 59.56 | 53.20 | 85.66 | 70.07 | 66.04 | |||
| V=0.16 | Avg | 87.67 | 76.29 | 70.68 | 63.78 | 57.71 | 52.19 | 83.50 | 66.30 | 62.92 | ||
| V=0.32 | Avg | 88.03 | 78.07 | 76.77 | 60.40 | 55.69 | 51.03 | 84.41 | 68.12 | 64.19 | ||
表11 在KITTI验证集上VoxTNT中各组件消融结果比较Tab. 11 Comparison of ablation results of various components in VoxTNT on KITTI validation set |
| 体素 尺寸 | 组件 | 汽车 | 行人 | 骑行者 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointSet Former | Voxel Former FNN | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | ||||
| V=0.16 | √ | √ | 88.57 | 77.12 | 71.15 | 65.76 | 59.56 | 53.20 | 86.00 | 68.99 | 64.70 | |||
| √ | 87.82 | 77.61 | 76.26 | 65.16 | 57.84 | 51.90 | 85.09 | 65.71 | 63.33 | |||||
| × | × | 87.79 | 77.30 | 71.42 | 59.07 | 53.13 | 48.40 | 81.55 | 62.06 | 58.78 | ||||
| V=0.32 | √ | √ | 88.52 | 78.20 | 77.03 | 61.12 | 57.21 | 52.12 | 85.66 | 70.07 | 66.04 | |||
| √ | 87.59 | 77.79 | 76.57 | 59.89 | 54.57 | 48.82 | 82.50 | 63.62 | 62.28 | |||||
| × | × | 87.04 | 76.77 | 73.30 | 53.76 | 46.69 | 42.81 | 81.25 | 63.99 | 60.21 | ||||
注:加粗的表示最佳值。 |
表12 关键组件在WOD验证集上的消融结果对比Tab. 12 Comparison of ablation results of key components in VoxTNT on WOD validation set |
| 组件 | Vec_L1 (AP) | Vec_L1 (APH) | Vec_L2 (AP) | Vec_L2 (APH) | Ped_L1 (AP) | Ped_L1 (APH) | ||
|---|---|---|---|---|---|---|---|---|
| PointSetFormer | VoxelFormerFFN | |||||||
| √ | √ | 69.74 | 69.19 | 61.32 | 60.83 | 72.49 | 62.29 | |
| √ | 69.63 | 69.10 | 61.23 | 60.75 | 72.66 | 62.45 | ||
| × | × | 64.84 | 64.21 | 56.72 | 56.15 | 63.39 | 46.12 | |
| Ped_L2 (AP) | Ped_L2 (APH) | Cyc_L1 (AP) | Cyc_L1 (APH) | Cyc_L2 (AP) | Cyc_L2 (APH) | |||
| PointSetFormer | VoxelFormerFFN | |||||||
| √ | √ | 63.86 | 54.71 | 65.76 | 64.46 | 63.35 | 62.09 | |
| √ | 64.03 | 54.86 | 65.38 | 63.99 | 62.99 | 61.65 | ||
| × | × | 54.99 | 39.91 | 56.86 | 53.86 | 54.70 | 51.83 | |
注:加粗数值表示最佳值。 |
利益冲突:Conflicts of Interest 所有作者声明不存在利益冲突。
All authors disclose no relevant conflicts of interest.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
张尧, 张艳, 王涛, 等. 大场景SAR影像舰船目标检测的轻量化研究[J]. 地球信息科学学报, 2025, 27(1):256-270.
[
|
| [8] |
高定, 李明, 范大昭, 等. 复杂背景下轻量级SAR影像船舶检测方法[J]. 地球信息科学学报, 2024, 26(11):2612-2625.
[
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
孔德明, 李晓伟, 杨庆鑫. 基于伪点云特征增强的多模态三维目标检测方法[J]. 计算机学报, 2024, 47(4):759-775.
[
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
彭颖, 张胜根, 黄俊富, 等. 基于自注意力机制的两阶段三维目标检测方法[J]. 科学技术与工程, 2024, 24(25):10825-10831.
[
|
| [63] |
鲁斌, 杨振宇, 孙洋, 等. 基于多通道交叉注意力融合的三维目标检测算法[J]. 智能系统学报, 2024, 19(4):885-897.
[
|
| [64] |
张素良, 张惊雷, 文彪. 基于交叉自注意力机制的LiDAR 点云三维目标检测[J]. 光电子·激光, 2024, 35(1):75-83.
[
|
| [65] |
刘明阳, 杨啟明, 胡冠华, 等. 基于Transformer的3D点云目标检测算法[J]. 西北工业大学学报, 2023, 41(6):1190-1197.
[
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
刘慧, 董振阳, 田帅华. 融合点云和体素信息的目标检测网络[J]. 计算机工程与设计, 2024, 45(9):2771-2778.
[
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
PyTorch. Torch.scatter[EB/OL].[5-24]. https://pytorch.org/docs/2.3/generated/torch.scatter.html#torch.scatter.
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}