

1 引言
新冠肺炎疫情是近代以来感染规模最大、影响最为深远的一次突发公共卫生事件,其造成的灾难性后果、暴露出疫情防控中的弊端以及存在的潜在威胁,向我国的疫情防控体系发起了新的挑战。在疫情防控的各项工作中,模拟病毒传播、快速评估疫区风险是科学判断疫情、精准把控疫情的重要依据。因此,有必要在疫情发生时应用科学的方法识别潜在疫区、精细化评估疫情风险。
如今,随着信息技术的发展,具备空间位置属性的生态要素数据和社会要素数据增长迅速,汇集成丰富的时空数据集,使构建科学有效的疫情传播风险预测模型成为可能。基于多源时空数据预测疫情传播风险,我们首先需要模拟精细空间尺度下的疫情空间演变过程。目前学者主要通过建立动力学模型和统计学模型实现对传染病时空传播的模拟。其中,仓室模型在动力学模型中一直占据着主流地位,是疫情模拟和预测研究的重要方法之一[1,2],仓室模型可分为SI [3]、SIS[4]、SIR[5]、SEIR[6,7,8]等基本类型。仓室模型侧重于研究传染病传播的机理,从而反映出疫情传播的内在规律,可以考虑人口流动、空间异质性以及结合具体场所数据,修改模型参 数及设定,在微观尺度上模拟传染病时空扩散过程[9,10,11],但其建模复杂度和对数据粒度的细化标准相对较高,确诊病例的空间分布模拟还具有较大的不确定性。统计学模型侧重于学习历史数据中的规律,从而实现对疫情传播趋势的模拟和预测,相比传统的动力学模型,统计学模型参数相对较少,应用更加简便高效,如经验贝叶斯模型[12]、自回归综合移动平均(ARIMA)模型[13,14]以及Logistic增长曲线模型[15]在传染病流行时间以及规模研究中的预测效果较好。此外,随着近几年人工智能的发展,将历史数据作为训练数据集,应用机器学习模拟疫情传播的预测方法也得到了快速发展,已广泛应用于疫情发展趋势及停止时间的模拟预测。研究表明,机器学习方法可以更好地模拟疫情传播与时空影响因素的关系[16,17],相比SEIR等动力学模型,建模时需要对参数(如基本再生数R0)进行假设而导致模型模拟精度低的问题,只需借助实时数据就能计算模型参数的机器学习方法在非线性系统演变模拟中展现出巨大的优势[18],结合地理信息系统的机器学习演变模型打开了传染病疫情空间演变模拟研究的新思路。如BP神经网络[19,20,21]、支持向量机模型[22,23]、随机森林模型[24,25]已初步尝试应用于疫情时空传播模拟,结果显示真实值和模拟值间的误差较小,表明了机器学习方法在传染病时空扩散模拟应用中的可行性。
虽然以上机器学习方法解决了传统数学模型在非线性系统建模的局限性,但在建模时,输入变量常被认为是彼此独立的,忽略了疫情数据是一个时间序列数据集,数据间存在时序关系,疫情空间演变存在随趋势变化的情况,所以应用于疫情传播风险预测,模型模拟的精度还有待提高。此外,虽然目前针对传染病风险评估的研究已取得不错的成果,但是仍存在只将确诊病例作为疫情风险评估的单一评价指标,风险评估结果不够客观、准确,无法反映风险演变趋势的不足[8],基于模拟结果和疫情传播时空影响因素,如何定量化的描述评估单元的风险等级,快速、客观地为疫情防控工作人员提供决策支持的研究还较少。
鉴于此,本文提出了耦合长短期记忆(Long Short-term Memory, LSTM)算法和云模型的疫情传播风险预测模型。相较已有研究,本文所提模型有如下改进:对于传染病确诊病例点要素,考虑距离衰减效应的影响,应用核密度分析处理模拟模型的输入数据,并以1 km×1 km为空间尺度、以天为时间尺度来研究,提高模拟精细程度;将深度学习算法——LSTM算法引入疫情时空建模的构建中来,并与常规机器学习模型作比较,验证LSTM模型模拟疫情时空演变的优势;在模拟结果的基础上展开更深层次的研究,构建LSTM算法和云模型的耦合模型,基于模拟确诊病例数据和疫情传播时空影响因素构建风险评价指标,应用自适应策略,实现了不同空间分辨率下(县(区)、乡镇(街道)、 1 km格网尺度)的疫情风险定量评估,从而预测出各区域疫情传播的风险。
2 研究方法
本文提出模型的设计思路为:① 数据层:通过网站设置的API接口以及Python爬虫等渠道获取相关影响因素数据;② 分析处理层:借助GIS,将数据层的数据,以1 km×1 km格网为单位进行分析、处理,形成模型层的输入数据;③ 模型模拟层:将处理后的输入数据输入LSTM神经网络模型,训练模拟传染病疫情的空间演变过程;④ 风险评估层:输入疫情模拟结果与疫情风险评价指标,应用云模型和自适应策略,输出疫情风险评价结果。模型构建流程如图1所示,模型的主要构建过程简述如下。
2.1 基于GIS的数据分析处理
地理信息系统技术凭借着强大的制图功能和空间分析、统计功能成为国内外学者研究疫情时空演变规律的重要基础工具[26],被广泛应用于埃立克体病、非典型性肺炎(SARS)、疟疾、H5N1高致病性禽流感、登革热、新冠肺炎疫情等流行传染病的时空演变规律的研究。因此,本文基于数据层得到影响传染病传播的相关影响因素数据后,借助GIS对数据进行分析处理。主要方法有:
(1)应用空间可视化功能,将影响疫情演变的时空数据可视化呈现。同时,为了更精确地模拟传染病的传播过程,将疫区划分为1 km×1 km的格网,以此为单位进行研究。
(2)对各影响因素量化处理。其中确诊病例点要素,应用核密度分析工具分析处理,核密度分析方法不同于常见的密度分析方法,它在计算某一点S处的核密度值时考虑了距离衰减效应的影响[27]。点S处的核密度值可表示如下:
式中:
(3)应用叠加分析功能,形成空间样本点,使每个样本点同时具有空间数据和各影响因素的属性数据(如人口聚集程度、温度等)。但由于输入特征的信息存在重叠时会对模型训练的收敛速度和精度产生影响,因此本文应用因子分析提取共性特征作为模型的输入特征,形成模型层的输入数据。
图1
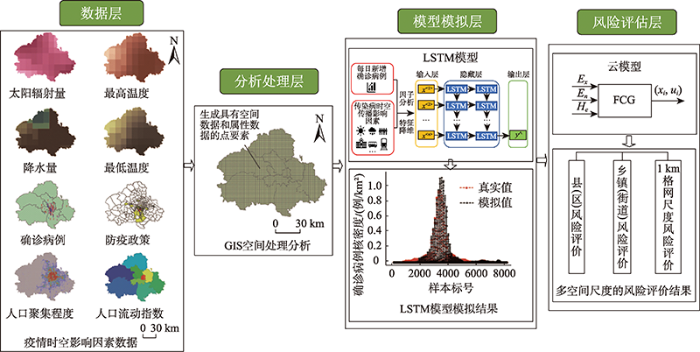
2.2 基于LSTM模型的传染病扩散模拟
近年来,深度学习技术逐渐成熟,凭借着出色的非线性映射能力和学习能力,被广泛应用于众多领域。其中,作为递归神经网络(Recursive Neural Network, RNN)一个变种的LSTM模型,不仅能够学习历史时序数据中的时间信息进行模拟,还解决了RNN模型梯度消失和梯度爆炸的不足,提高其长期记忆能力。在语音识别、交通流速预测、机器翻译、故障时间序列预测等领域表现出强大的适应能力[28]。因此,本文将LSTM模型引入到疫情空间演变模拟模型的构建中来。
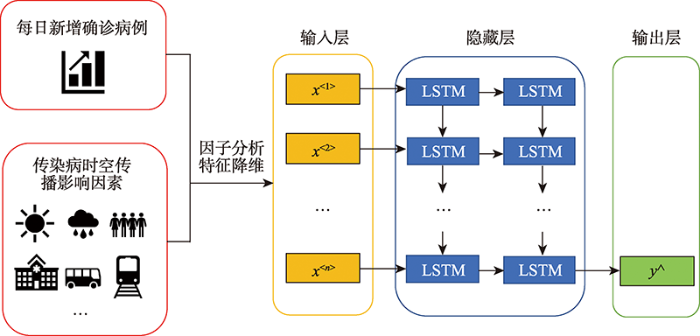
LSTM模型是由Hochreiter等[29]提出,是循环神经网络的改良版,具有记忆功能,它可以学习历史数据中存在的时间依赖关系,将时间序列上的信息关联起来,从而模拟疫情的空间演变过程,输出模拟时间段新增确诊病例核密度的模拟值。传染病发病率受到多方因素的影响,为了训练LSTM模型通过学习历史数据模拟疫情传播与时空影响因素的关系,构建多变量时间序列作为模型输入特征。模型输入特征由每个时间段新增确诊病例数据和量化的传染病时空传播影响因素组成。但考虑到当各因素之间存在相关性以及输入特征过多时,会对模型的学习效果产生不利影响,因此,首先应用因子分析在保留原有数据信息量的同时对原有特征进行降维,将降维后的共性特征作为输入变量。接下来,应用历史疫情数据训练神经网络各层节点之间的连接权值,神经网络各层节点之间的连接权值可以反映各影响因素对传染病时空传播的影响,其连接权值基于模型的最佳学习效果确定。最后,多变量LSTM模型通过学习各时空影响因素对新增确诊病例的影响以及时间序列随趋势变化的关系,从而模拟或预测未来的新增确诊病例情况。模型的网络结构如图2所示。其中,n表示模型的输入时间序列长度,
图2
2.3 基于云模型和自适应策略的疫情风险评估
由LSTM模型得到传染病传播的模拟数据后,为了更直观、准确地给予政府防疫部门提供决策支持,需要充分地评价各区域的疫情风险状况。
云模型作为可以实现定性概念与定量概念的不确定转换模型[30],可以辅助我们依据模拟结果和开源时空数据实现对各区域的疫情风险定量评价。该模型可用期望值Ex、熵En和超熵He表示模型的特征。其中,期望值Ex是将定性概念量化最典型的值,熵En表示定性概念的模糊程度,超熵He可以度量熵En的不确定性。计算公式如下:
表1 疫情风险评价指标
Tab. 1
| 一级指标 | 二级指标 |
|---|---|
| 传染源因素A | 模拟新增确诊病例核密度A1 |
| 天气因素B | 2 m处最高温度B1 |
| 2 m处最低温度B2 | |
| 总降水量B3 | |
| 总天空直接太阳辐射量B4 | |
| 疫情防御因素C | 防疫政策C1 |
| 疫情扩散因素D | 人口聚集程度D1 |
| 人口流动指数D2 |
此外,为了实现快速评估区域疫情风险,本文采用自适应策略,先评价低空间分辨率下的疫情风险,再针对高风险区以高空间分辨率进一步评价,从而实现多空间尺度的疫情风险评价,满足不同精度的疫情防控要求。
3 实验数据与模型设计
3.1 实验区域及数据来源
表2 实验数据
Tab. 2
图3
3.2 实验环境及设计
本研究应用深度学习库Keras搭建LSTM模型。将2020年6月11日至2020年6月25日共计15 d的疫情数据作为训练集,2020年6月26日至2020年7月1日共计6 d的疫情数据作为测试集。以3 d为一个时间段,用前3个时间段的数据作为输入样本,模拟未来1个时间段的新增确诊病例情况。LSTM模型的参数调试主要包括隐藏层节点个数和模型深度。此外,新冠肺炎发病率与天气、人口密度、人口聚集、人口流动以及政策等因素有明显的联系[31,32,33,34]。LSTM模型输入特征具体为:每个时间段的新增确诊病例核密度、2 m处最高温度、2 m处最低温度、总降水量、总天空直接太阳辐射量、人口流动指数、人口聚集程度以及量化的防疫政策(根据区域风险等级进行量化,低风险区记为“0”,中风险地区记为“1”,高风险地区记为“2”)共计8个指标因素。实验对比模型分别是LSTM模型、GA-BP神经网络模型、决策树模型、随机森林模型和支持向量机模型。
3.2.1 模型性能评价指标
本研究使用平均绝对误差(MAE)(式(3))来评判模型模拟的偏离程度,使用决定系数(R-square)(式(4))来评判模型的拟合能力。MAE越小表示模型模拟精度越高,R-square越接近1,表示模型拟合的效果越好,输入变量对模拟值的解释能力也越强。
式中:
3.2.2 隐含层节点个数
目前研究中,隐藏层神经元个数通常情况下按照式(5)选取神经元个数,其中,
在本文研究中,应用因子分析提取可代表所有特征的共性特征数量共计4个,因此,n为4,m为1,根据公式N应为3~12。将模型深度设置为1,调整隐藏层神经元个数,根据模型模拟结果的平均绝对误差来衡量模型模拟的偏离程度,从而确定隐藏层神经元个数。
模拟结果显示,当N调整为8时,模型的MAE最小,模拟效果最好。测试集的模拟结果如表3所示。
表3 隐藏层调整的模拟结果
Tab. 3
| 隐藏层神 经元个数 | MAE (6-25—6-28) | MAE (6-29—7-1) | MAE 合计 |
|---|---|---|---|
| 3 | 0.002 06 | 0.001 65 | 0.003 71 |
| 4 | 0.002 14 | 0.001 54 | 0.003 68 |
| 5 | 0.002 12 | 0.001 69 | 0.003 81 |
| 6 | 0.002 05 | 0.001 31 | 0.003 36 |
| 7 | 0.001 86 | 0.001 23 | 0.003 09 |
| 8 | 0.001 85 | 0.001 02 | 0.002 87 |
| 9 | 0.001 83 | 0.001 13 | 0.002 96 |
| 10 | 0.001 91 | 0.001 27 | 0.003 18 |
| 11 | 0.002 12 | 0.001 22 | 0.003 34 |
| 12 | 0.002 05 | 0.001 17 | 0.003 22 |
3.2.3 模型深度
鉴于本例研究疫情数据相对较少,若模型隐藏层数量过高会导致模型过拟合,因此,实验设定模型深度为1~5层,每层隐藏神经元数量仍为8个,根据模型模拟结果的平均绝对误差和决定系数来评判模型性能,从而确定模型深度。根据模拟结果(表4)可知,LSTM模型模型深度设置为2层时,模型模拟的偏离程度最小,拟合的效果最好,输入影响因素值对模拟值的解释能力也最强。
表4 模型深度调整的模拟结果
Tab. 4
| 层数 | MAE | R-square |
|---|---|---|
| 1 | 0.00287 | 0.9391 |
| 2 | 0.00261 | 0.9455 |
| 3 | 0.00314 | 0.9361 |
| 4 | 0.00353 | 0.9206 |
| 5 | 0.00374 | 0.9132 |
4 结果及分析
4.1 COVID-19确诊病例模拟空间分布
将LSTM模型模拟结果进行空间可视化展示。由疫情的空间分布模拟结果可视化图与真实分布情况对比(图4)可知:疫情呈聚集分布,新增确诊病例主要集中在丰台区,表明丰台区模拟时间段新增确诊病例数量多且聚集程度高;二者空间分布具有较大的相似性,尤其是对新增确诊病例核密度较高的地区识别更为准确,这说明该模型对于疫情聚集的区域模拟精准度较高;新增确诊病例核密度在0~0.1例/km2的空间分布有一定的差异,这一方面是由于模型本身存在一定的误差,另一方面则因为零星确诊病例的分布受多方因素的影响,其空间分布模拟具有较大的不确定性,定量模拟模型难以非常准确的模拟出其空间传播过程。总而言之,该模型对新冠肺炎的空间分布模拟精度较高,能够较为准确地模拟出潜在确诊病例区。
图4
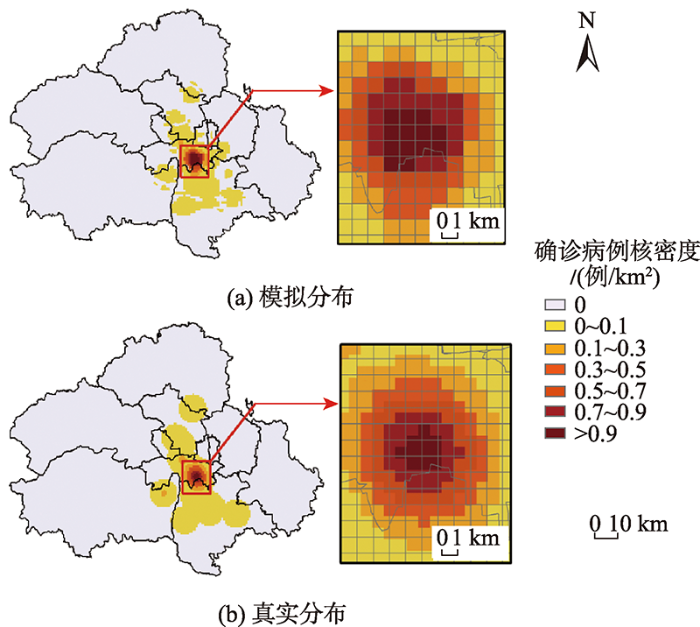
图4
疫情的空间真实分布与模拟分布对比
Fig. 4
Comparison of spatial real distribution and simulated distribution of epidemic situation
4.2 LSTM模型模拟结果及对比验证
图5
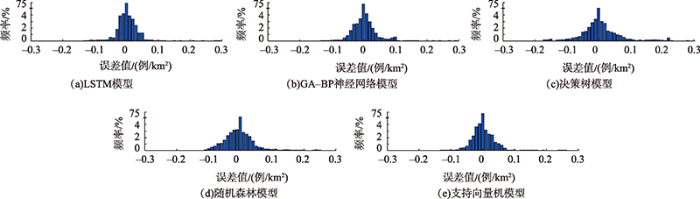
表5 模型模拟结果对比
Tab. 5
| 评判标准 | LSTM模型 | GA-BP神经网络 | 决策回归树 | 随机森林 | 支持向量机 |
|---|---|---|---|---|---|
| 平均绝对误差 | 0.002 61 | 0.003 20 | 0.008 72 | 0.007 43 | 0.003 79 |
| 决定系数 | 0.945 50 | 0.936 80 | 0.860 10 | 0.912 20 | 0.925 60 |
依据模拟结果误差分布图和模型性能对比结果,从模拟结果误差分布来看, LSTM模型测试集中90%的模拟误差值集中分布在区间[-0.02,0.02],GA-BP神经网络、决策回归树、随机森林以及支持向量机4个机器学习模型测试集中90%的模拟误差值分别集中分布在区间[-0.03,0.02]、[-0.05,0.04]、[-0.04,0.03]、[-0.02,0.03],相较之下,LSTM模型的模拟结果与真实结果更为接近,误差值更小;从模拟精度来看,LSTM模型平均绝对误差最小,精度最高,GA-BP神经网络模型和支持向量机模型性能次之,精度最低、误差最大的是随机森林模型和决策树模型;从拟合效果来看,LSTM模型能较好的模拟传染病时空传播过程,R-square最接近1,模拟值与真实值之间的拟合效果最好,其次是GA-BP神经网络模型和支持向量机模型,拟合度较差的是随机森林模型和决策树模型。因此,在这5种机器学习模型中,考虑数据间时序关系的LSTM神经网络模型更适用于疫情的空间分布预测。由此证明LSTM模型在考虑多因素的、精细空间尺度下的疫情空间演变模拟中具有一定的可靠性。
4.3 多空间尺度的疫情风险评估
本文所提出的模型可以实现快速、定量地评估多空间尺度的疫情风险,多空间尺度分3级,分别是:北京县(区)、乡镇(街道)和1 km格网尺度。另外,由于在2020年6月26日—7月1日政府部门公示的疫情风险等级查询结果只精确至乡镇(街道),因此本文仅以北京县(区)和乡镇(街道)为评估单元进行模型可靠性的验证。
4.3.1 县(区)风险评价
根据2.3节所述公式,云模型的计算参数矩阵如表6所示。对于上文提到的每个指标,根据表6所示的云模型参数矩阵,我们可以通过前向云生成器生成隶属度矩阵。考虑到计算结果的随机性,我们计算了1000次以获得更高的精度。在得到各指标的隶属度矩阵后,结合熵权法计算出的权重系数,可以对北京市含确诊病例的11个县级区域进行疫情风险综合评价。疫情风险评估结果如图6所示。丰台区的风险最高,其次,风险较高的是大兴区,中风险区包括西城区和东城区2个区,较低风险区包括石景山区、海淀区和朝阳区,其余区则属于低风险区。这与北京的实际疫情风险状况基本相符,据北京市新冠肺炎疫情防控工作新闻发布会对高中风险地区变化的回复以及国务院客户端小程序的“疫情风险等级查询”结果(
图6
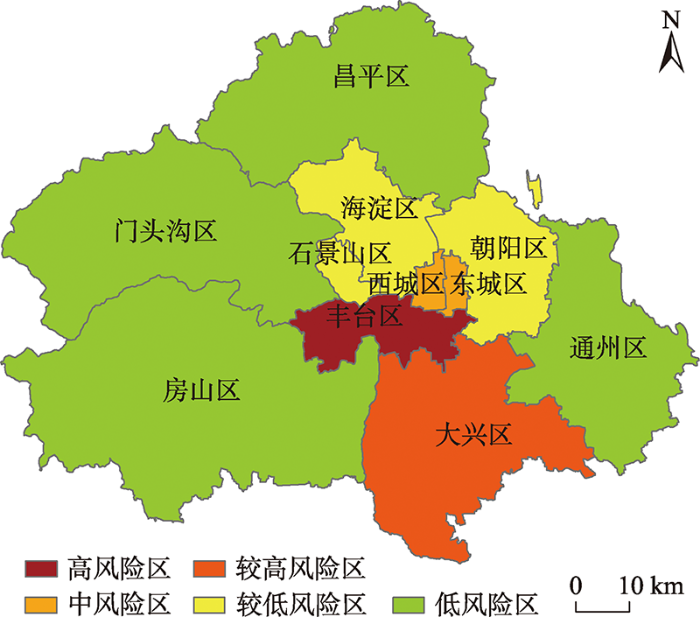
图6
北京市含确诊病例县(区)风险评价结果
Fig. 6
Risk assessment results of counties (districts) with confirmed cases in Beijing
表6 云模型的计算参数矩阵
Tab. 6
| 指标 | 低风险 | 较低风险 | 中风险 | 较高风险 | 高风险 |
|---|---|---|---|---|---|
| A1 | (0.0005, 0.0003, 0.1) | (0.0030, 0.0013, 0.1) | (0.0065, 0.0010, 0.1) | (0.0540, 0.0307, 0.1) | (0.1100, 0.0067, 0.1) |
| B1 | (146.42, 97.61, 0.1) | (293.97, 0.76, 0.1) | (296.08, 0.65, 0.1) | (298.14, 0.72, 0.1) | (300.15, 0.62, 0.1) |
| B2 | (144.63, 96.42, 0.01) | (290.35, 0.72, 0.01) | (292.29, 0.57, 0.01) | (294.10, 0.64, 0.01) | (295.83, 0.52, 0.01) |
| B3 | (0.0008, 0.0005, 0.1) | (0.0020, 0.0002, 0.1) | (0.0029, 0.0003, 0.1) | (0.0041, 0.0004, 0.1) | (0.005 9, 0.000 8, 0.1) |
| B4 | (1 288 026, 858 684,0.1) | (2 691 607, 77037, 0.1) | (2 902 592, 63620, 0.1) | (3120 919, 81 931, 0.1) | (3 379 396, 90 387, 0.1) |
| C1 | (0.1500, 0.1000, 0.01) | (0.4000, 0.0667, 0.01) | (0.6000, 0.0667, 0.01) | (0.7500, 0.0333, 0.01) | (0.850 0, 0.0333, 0.01) |
| D1 | (0.5000, 0.3333, 0.01) | (1.5000, 0.3333, 0.01) | (2.5000, 0.3333, 0.01) | (4.0000, 0.6667, 0.01) | (6.000 0, 0.6667, 0.01) |
| D2 | (0.4409, 0.2940, 0.01) | (1.5724, 0.4603, 0.01) | (3.1944, 0.6210, 0.01) | (5.3173, 0.7942, 0.01) | (8.2675, 1.1726, 0.01) |
4.3.2 乡镇(街道)风险评价
经过对北京区域疫情风险的初步评估,我们得知丰台区是疫情传播的高风险区,由此,我们可以根据自适应策略,针对丰台区以乡镇(街道)为评估单元作更详细的风险评估,而不需对每一个区域以高空间分辨率进行风险评价,从而大大节省了时间成本,有利于快速给予政府防疫工作部门决策支持。由疫情风险评估可视化图(图7)可知,花乡、卢沟桥以及丰台街道是疫情防控重点地区,需加强疫情防控政策,减少疫情扩散风险,此外,太平桥街道、马甲堡街道以及南苑乡虽然疫情风险性较小,但仍不可放松警惕,要防范疫情二次传播的风险。在模拟阶段,实际乡镇(街道)疫情风险等级的情况为:花乡一直处于高风险区;卢沟桥、丰台街道、南苑、马甲堡街道、右安门街道一直处于中风险区;西罗园街道、太平桥街道、大红门街道、长辛店镇则随着疫情防控措施的落实,发病趋势逐渐平稳并回落,变为低风险区;其余区一直为低风险区。疫情风险评估结果与实际情况基本相符。
图7
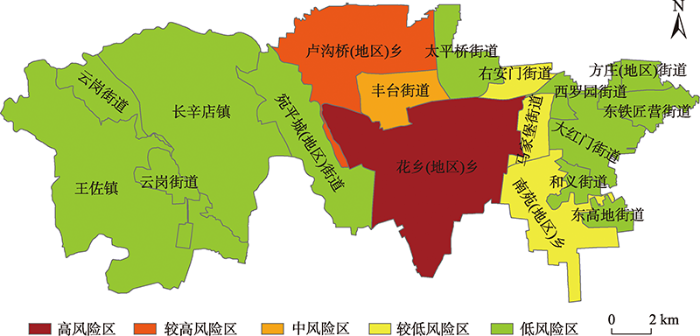
图7
丰台区乡镇(街道)风险评价结果
Fig. 7
Risk assessment results of towns (streets) in Fengtai District
4.3.3 1 km格网尺度风险评价
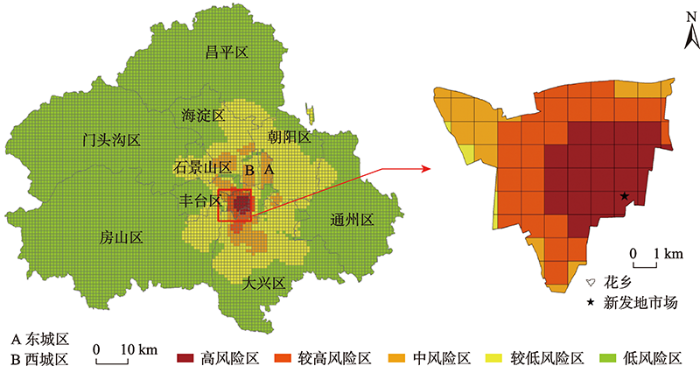
以1 km格网为空间尺度评估北京含确诊病例区的疫情风险,得到的风险评价结果如图8所示。其中,高风险区主要集中分布在丰台区,较高风险区主要分布在丰台区以及大兴区,中风险区在丰台区、大兴区、海淀区、东城区、西城区、朝阳区、石景山区则有不同程度的分布,较低风险区和低风险区分布的区域最广,在所研究的北京11个含确诊病例区中都有所包含。这与实际的县(区)和乡镇(街道)风险评估结果具有较大的一致性。此外,基于自适应策略和乡镇(街道)风险评估结果,以花乡为例作进一步的分析。以县(区)、乡镇(街道)为评估单元,花乡所处的区域被评定为高风险区;以1 km格网尺度为评估单元,花乡的高风险区主要集中在新发地市场及周边3~4 km范围内的区域,离新发地市场较远的区域则疫情风险相对较低。相比以县(区)、乡镇(街道)为评估单元,1 km格网尺度的风险评价结果更加详尽。
图8
5 结论与讨论
本文提出了基于LSTM算法和云模型耦合的疫情传播风险预测模型,该模型融合开源时空数据,基于GIS和LSTM算法模拟精细空间尺度下疫情的空间演变过程,并在模拟结果的基础上,进一步应用云模型和自适应策略实现多空间分辨率下的疫情风险评估。以北京2020年6月份突发新冠肺炎疫情为实例,验证了模型的可行性与合理性。主要结论如下:
(1)本文提出的耦合模型从3个层面提升了传染病传播风险评估结果的客观性和准确性:在分析处理层,对确诊病例点要素通过核密度分析的方法较准确地表达了传染源因素在传染病传播中产生的影响,同时,精细化研究尺度(将1 km×1 km作为空间尺度、天为时间尺度),提高了模拟的精细程度;在模型模拟层,应用LSTM模型模拟疫情的时空传播过程,解决了常规机器学习模型未考虑疫情数据间时序关系的不足;在风险评估层,构建了包含传染源因素、天气因素、疫情扩散因素及疫情防御因素的疫情风险评价指标,应用云模型和自适应策略,充分考虑各区域的疫情风险状况,实现了快速定量评估不同空间分辨率的疫情风险状况。这为识别潜在疫区、针对性地制定传染病防控政策提供了强有力的技术支撑。
(2)本文依据2020年6月11日至2020年6月25日的北京COVID-19疫情数据,模拟了2020年6月26日至2020年7月1日疫情空间演变过程,相较GA-BP神经网络、决策回归树、随机森林、支持向量机模型,LSTM模型的模拟精度更高(MAE为 0.002 61),拟合度更好(R-square为0.945 5),这表明考虑疫情数据间时序关系的LSTM模型更适用于疫情空间演变建模。在此基础上得到的北京县(区)、乡镇(街道)和1 km格网3个空间尺度上的疫情风险评估结果与实际情况基本吻合,证实了本文所提耦合模型的有效性与可靠性。
(3)本文提出的耦合LSTM算法和云模型的疫情传播风险预测模型,适用于实时和短期的传染病空间传播模拟和风险评估,模型参数较少,能够较为高效、准确地评估出疫情风险,实用性和适用性较强,为模拟传染病时空传播、科学有效地评估疫情风险提供了方法借鉴。
本文提出的疫情传播风险预测模型是耦合深度学习算法和云模型,应用于传染病空间传播模拟及风险评估的初步尝试,实现了短期的疫情传播风险预测,但对于长期疫情传播风险预测的可行性还需后续研究;其次,在考虑影响新冠肺炎传播的因素上,本文未考虑输入性疫情、无症状感染者等因素的影响,随着疫情防控进入不同阶段,模型输入特征及疫情传播风险评估指标还应根据当地疫情发展特点进行调整,从而更好的为防疫工作者制定防疫措施提供技术支持;最后,本文以1 km×1 km为空间尺度、天为时间尺度展开疫情空间演变研究,数据粒度精细,影响因素对数据的波动性较大,如何处理异常数据、提高模型的鲁棒性将是未来改善模型性能的重要课题。
参考文献
A systematic review on AI/ML approaches against COVID-19 outbreak
[J].
COVID-19疫情时空分析与建模研究进展
[J].
DOI:10.12082/dqxxkx.2021.200434
[本文引用: 1]

COVID-19疫情是进入21世纪以来最为严重的全球公共卫生事件,并成为不同学科共同关注的热点。根据文献计量学分析结果,从疫情开始直至近期,关于COVID-19疫情的文章已经超过13 000篇,相关研究除从医学及生物学角度探讨病毒致病机理、特效药物和疫苗研制之外,更多的是探索疫情的非药物防控方法。本文针对后者,从传播关系识别、疫情时空模式分析、疫情预测模型、疫情传播模拟、疫情风险评估和疫情影响评价6个方面梳理近期研究进展。传播关系识别的研究主要包括:聚集性疫情和传播关系的识别,其中,个体轨迹大数据已成为此类研究的关键。针对疫情的时空模式分析发现,疫情分布具有显著的时空异质性,而时空传播则呈现出典型的网络特征。针对疫情的预测仍主要依赖于动力学模型,而从宏观到微观的预测模型,人群流动的影响不容忽视,并成为模型预测精度的关键要素之一。针对疫情的情景模拟主要侧重于通过模拟手段评估交通限制、社区防控和医疗资源调配等措施的效果。在非药物的干预中,交通阻断和社区防控措施被证明是目前最有效的手段;医疗资源的保障和优化调配则是防控的基础;而复工复产的情景模拟显示,在防控措施到位的情况下,复工进程必须有序有节。针对疫情风险评估的研究,目前主要关注生物因素、自然因素和社会因素。具体地,疫情感染风险与个体是否具有基础性疾病关系密切,而感染病毒后的死亡率存在性别差异;在自然因素中,如温度、降水、气候等会影响疫情的传播,但影响有限;而社会因素中,除了人群流动和人口密度的影响外,社会不公平性所导致的就医条件差异也会对感染率产生显著影响。针对疫情对未来的影响,本文主要关注公众心理、自然环境和经济发展3个方面,即疫情对公众心理和经济的影响主要以负面为主,而对自然环境的影响则起正向作用。通过对现有研究的系统梳理,可以看出,大数据尤其是个体轨迹和群体大数据在非药物干预的各个方面均发挥了重要的作用;重大疫情的防控已经不是单一学科和手段所能解决的问题,需要多学科的交叉以及不同领域人员的协作;疫情期间各种防控措施的效果、影响因素等均已被明确的揭示,但疫情的空间溯源、精准预测以及对未来的影响仍然是未解的难题。
Review on spatiotemporal analysis and modeling of COVID-19 pandemic
[J].
A diffusive SI model with Allee effect and application to FIV
[J].A minimal reaction-diffusion model for the spatiotemporal spread of an infectious disease is considered. The model is motivated by the Feline Immunodeficiency Virus (FIV) which causes AIDS in cat populations. Because the infected period is long compared with the lifespan, the model incorporates the host population growth. Two different types are considered: logistic growth and growth with a strong Allee effect. In the model with logistic growth, the introduced disease propagates in form of a travelling infection wave with a constant asymptotic rate of spread. In the model with Allee effect the spatiotemporal dynamics are more complicated and the disease has considerable impact on the host population spread. Most importantly, there are waves of extinction, which arise when the disease is introduced in the wake of the invading host population. These waves of extinction destabilize locally stable endemic coexistence states. Moreover, spatially restricted epidemics are possible as well as travelling infection pulses that correspond either to fatal epidemics with succeeding host population extinction or to epidemics with recovery of the host population. Generally, the Allee effect induces minimum viable population sizes and critical spatial lengths of the initial distribution. The local stability analysis yields bistability and the phenomenon of transient epidemics within the regime of disease-induced extinction. Sustained oscillations do not exist.
The N-intertwined SIS epidemic network model
[J].DOI:10.1007/s00607-011-0155-y URL [本文引用: 1]
Dynamics of measles epidemics: Estimating scaling of transmission rates using a time series sir model
[J].DOI:10.1890/0012-9615(2002)072[0169:DOMEES]2.0.CO;2 URL [本文引用: 1]
COVID-19: Analytic results for a modified SEIR model and comparison of different intervention strategies
[J].DOI:10.1016/j.chaos.2020.110595 URL [本文引用: 1]
A modified SEIR model to predict the COVID-19 outbreak in Spain and Italy: Simulating control scenarios and multi-scale epidemics
[J].DOI:10.1016/j.rinp.2020.103746 URL [本文引用: 1]
一种基于改进SEIR模型的突发公共卫生事件风险动态评估与预测方法—以欧洲十国COVID-19为例
[J].
DOI:10.12082/dqxxkx.2021.200356
[本文引用: 2]
突发公共卫生事件会严重影响社会公众生命健康,风险评估和预测可为突发公共卫生事件有效防控提供科学依据。本文提出了一种基于SEIR模型的突发公共卫生事件风险动态评估与预测方法,将突发公共卫生事件传播与人口、医疗、经济情况相结合,耦合危险性与脆弱性,建立合理的风险评估综合指标体系,利用熵值—层次分析组合模型实现突发公共卫生事件风险动态评估。此外,本文建立了传染病传播动力学修正SEIR模型,将传染病传播动力学模拟预测与风险评估相结合,实现突发公共卫生事件演变趋势的预测和风险的动态预测。2019年12月底的COVID-19疫情是一次传播速度快、感染范围广、防控难度大的重大突发公共卫生事件。本文以欧洲10国COVID-19疫情为例,开展风险评估与风险动态预测研究,依据欧洲10国自疫情开始至2020年4月16日的疫情数据,预测了2020年4月17日—2020年5月10日疫情演变的趋势,进而实现了10国的疫情风险动态预测。本文模型预测结果表明至2020年5月10日欧洲10国疫情形势仍然严峻,预测数据与真实数据的拟合优度R <sup>2</sup>大于0.92,预测结果与疫情真实情况基本一致,在此情况下,复工复产对于疫情防控仍然是不利的。本文提出的基于SEIR模型的公共卫生事件风险动态评估与预测方法为疫情已然传播开的国家和地区提供了风险持续评估和预测的可能,为后期疫情防控决策提供了支持,同时也可用于今后新的疫情发生时期或其他突发性公共卫生事件下风险的应急评估和预测。
A method for dynamic risk assessment and prediction of public health emergencies based on an improved SEIR model: COVID-19 in ten European countries
[J].
城市时空大数据驱动的新型冠状病毒传播风险评估——以粤港澳大湾区为例
[J].
COVID-19 risk assessment driven by urban spatiotemporal big data: A case study of Guangdong-Hong Kong-Macao Greater Bay Area
[J].
交通分析区尺度上的新型冠状病毒肺炎时空扩散推估方法:以武汉市为例
[J].
Traffic analysis zone-based epidemic estimation approach of COVID-19 based on mobile phone data: an example of Wuhan[J/OL]
Interventions to mitigate early spread of SARS-CoV-2 in Singapore: A modelling study
[J].DOI:10.1016/S1473-3099(20)30162-6 URL [本文引用: 1]
Flexible modeling of epidemics with an empirical Bayes framework
[J].DOI:10.1371/journal.pcbi.1004382 URL [本文引用: 1]
Application of the ARIMA model on the COVID-2019 epidemic dataset
[J].
DOI:10.1016/j.dib.2020.105340
PMID:32181302
[本文引用: 1]
Coronavirus disease 2019 (COVID-2019) has been recognized as a global threat, and several studies are being conducted using various mathematical models to predict the probable evolution of this epidemic. These mathematical models based on various factors and analyses are subject to potential bias. Here, we propose a simple econometric model that could be useful to predict the spread of COVID-2019. We performed Auto Regressive Integrated Moving Average (ARIMA) model prediction on the Johns Hopkins epidemiological data to predict the epidemiological trend of the prevalence and incidence of COVID-2019. For further comparison or for future perspective, case definition and data collection have to be maintained in real time.© 2020 The Authors.
ARIMA-based forecasting of the dynamics of confirmed Covid-19 cases for selected European countries
[J].DOI:10.24136/eq.2020.009 URL [本文引用: 1]
Forecasting COVID-19 epidemic in India and high incidence states using SIR and logistic growth models
[J].DOI:10.1016/j.cegh.2020.06.006 URL [本文引用: 1]
Mapping the transmission risk of Zika virus using machine learning models
[J].
DOI:S0001-706X(18)30361-9
PMID:29932934
[本文引用: 1]
Zika virus, which has been linked to severe congenital abnormalities, is exacerbating global public health problems with its rapid transnational expansion fueled by increased global travel and trade. Suitability mapping of the transmission risk of Zika virus is essential for drafting public health plans and disease control strategies, which are especially important in areas where medical resources are relatively scarce. Predicting the risk of Zika virus outbreak has been studied in recent years, but the published literature rarely includes multiple model comparisons or predictive uncertainty analysis. Here, three relatively popular machine learning models including backward propagation neural network (BPNN), gradient boosting machine (GBM) and random forest (RF) were adopted to map the probability of Zika epidemic outbreak at the global level, pairing high-dimensional multidisciplinary covariate layers with comprehensive location data on recorded Zika virus infection in humans. The results show that the predicted high-risk areas for Zika transmission are concentrated in four regions: Southeastern North America, Eastern South America, Central Africa and Eastern Asia. To evaluate the performance of machine learning models, the 50 modeling processes were conducted based on a training dataset. The BPNN model obtained the highest predictive accuracy with a 10-fold cross-validation area under the curve (AUC) of 0.966 [95% confidence interval (CI) 0.965-0.967], followed by the GBM model (10-fold cross-validation AUC = 0.964[0.963-0.965]) and the RF model (10-fold cross-validation AUC = 0.963[0.962-0.964]). Based on training samples, compared with the BPNN-based model, we find that significant differences (p = 0.0258* and p = 0.0001***, respectively) are observed for prediction accuracies achieved by the GBM and RF models. Importantly, the prediction uncertainty introduced by the selection of absence data was quantified and could provide more accurate fundamental and scientific information for further study on disease transmission prediction and risk assessment.Copyright © 2018. Published by Elsevier B.V.
Prediction of Shigellosis outcomes in Israel using machine learning classifiers
[J].
DOI:10.1017/S0950268818001498
PMID:29880081
[本文引用: 1]
Shigellosis causes significant morbidity and mortality in developing and developed countries, mostly among infants and young children. The World Health Organization estimates that more than one million people die from Shigellosis every year. In order to evaluate trends in Shigellosis in Israel in the years 2002-2015, we analysed national notifiable disease reporting data. Shigella sonnei was the most commonly identified Shigella species in Israel. Hospitalisation rates due to Shigella flexenri were higher in comparison with other Shigella species. Shigella morbidity was higher among infants and young children (age 0-5 years old). Incidence of Shigella species differed among various ethnic groups, with significantly high rates of S. flexenri among Muslims, in comparison with Jews, Druze and Christians. In order to improve the current Shigellosis clinical diagnosis, we developed machine learning algorithms to predict the Shigella species and whether a patient will be hospitalised or not, based on available demographic and clinical data. The algorithms' performances yielded an accuracy of 93.2% (Shigella species) and 94.9% (hospitalisation) and may consequently improve the diagnosis and treatment of the disease.
Time series forecasting of COVID-19 transmission in Canada using LSTM networks
[J].DOI:10.1016/j.chaos.2020.109864 URL [本文引用: 1]
Design of H7N9 avian influenza management and forecasting system based on GIS
基于反向传播神经网络模型的广东省登革热疫情预测研究
[J].
Prediction of dengue fever based on back propagation neural network model in Guangdong, China
[J].
基于GA-BP神经网络模型的登革热时空扩散模拟
[J].
Simulation of spatio-temporal diffusion of dengue fever based on the GA-BP neural network model
[J].
支持向量机模型的登革热时空扩散预测
[J].
Simulation of spatio-temporal diffusion trend of dengue fever based on the SVM model
[J].
Assessment of the outbreak risk, mapping and infection behavior of COVID-19: Application of the autoregressive integrated-moving average (ARIMA) and polynomial models
[J].DOI:10.1371/journal.pone.0236238 URL [本文引用: 1]
Mapping dengue risk in Singapore using Random Forest
[J].DOI:10.1371/journal.pntd.0006587 URL [本文引用: 1]
Prediction for global African swine fever outbreaks based on a combination of random forest algorithms and meteorological data
[J].DOI:10.1111/tbed.v67.2 URL [本文引用: 1]
GIS基础软件技术体系发展及展望
[J].
DOI:10.12082/dqxxkx.2021.210015
[本文引用: 1]
地理信息系统作为IT系统的重要组成部分,其技术的每一次进步都与最新IT技术的兴起息息相关。随着云计算、大数据、人工智能等技术的发展与应用,如今GIS基础软件已经形成五大技术体系:大数据GIS技术体系,增加了对空间大数据的存储管理、分析处理以及可视化的能力,丰富了空间数据的内涵;人工智能GIS技术体系,GIS通过结合人工智能相关算法,增强了GIS模型的分析预测能力,同时二者之间相互赋能,在增强GIS能力的同时,也让人工智能具备空间分析和可视化能力,拓展了其应用范围;新一代三维GIS技术体系,实现了二三维GIS一体化和多源异构数据的融合,推动了三维GIS从室外走向室内,从宏观走向微观;分布式GIS技术体系,突破了数据类型和容量的限制,数量级提升了GIS软件的性能,让高可用和高可信GIS应用成为可能;跨平台GIS技术体系,使得GIS软件可运行于不同类型的CPU架构和操作系统,满足日益丰富的多终端应用需求。五大技术相辅相成,进一步拓展了GIS基础软件的能力和应用场景。本文以SuperMap GIS为例,详细介绍了GIS五大技术体系的具体内容,阐述了每项技术的难点与创新点,并用光环曲线对五大技术体系的发展阶段进行了划分,探讨了未来GIS技术的发展趋势。
Development and prospect of GIS platform software technology system
[J].
Kernel Density Estimation of traffic accidents in a network space
[J].DOI:10.1016/j.compenvurbsys.2008.05.001 URL [本文引用: 1]
基于LSTM循环神经网络的故障时间序列预测
[J].
Exploring LSTM based recurrent neural network for failure time series prediction
[J].
Long short-term memory
[J].Learning to store information over extended time intervals by recurrent backpropagation takes a very long time, mostly because of insufficient, decaying error backflow. We briefly review Hochreiter's (1991) analysis of this problem, then address it by introducing a novel, efficient, gradient-based method called long short-term memory (LSTM). Truncating the gradient where this does not do harm, LSTM can learn to bridge minimal time lags in excess of 1000 discrete-time steps by enforcing constant error flow through constant error carousels within special units. Multiplicative gate units learn to open and close access to the constant error flow. LSTM is local in space and time; its computational complexity per time step and weight is O(1). Our experiments with artificial data involve local, distributed, real-valued, and noisy pattern representations. In comparisons with real-time recurrent learning, back propagation through time, recurrent cascade correlation, Elman nets, and neural sequence chunking, LSTM leads to many more successful runs, and learns much faster. LSTM also solves complex, artificial long-time-lag tasks that have never been solved by previous recurrent network algorithms.
Comprehensive evaluation for sustainable development based on relative resource carrying capacity-a case study of Guiyang, Southwest China
[J].
DOI:10.1007/s11356-020-08426-8
PMID:32236806
[本文引用: 1]
On the basis of resource carrying capacity, this study used the revised theory of relative resource carrying capacity, took Guiyang as the study object, and calculated relative carrying capacities of natural resources, economic resources, environmental resources, and social resources from 2003 to 2017. Natural resources were composed of three indicators (energy resources, water resources, and land resources). Human capital resources were incorporated into social resources. Therefore, on the basis of the revised model of relative resource carrying capacity, conclusions were drawn: when taking the whole country as the reference area, Guiyang had an overloaded population from 2003 to 2017 whether under traditional or improved resource-carrying capacity model. But there were different results from these two models. When taking the entire province as the reference area, the result was the opposite. Whether taking the whole country or the entire province as the reference area, contributions of economic resources and social resources to comprehensive resource-carrying capacity were obviously higher than that of natural resources and environmental resources. When taking Guizhou as the reference area, other districts and counties were in the state of surplus, except that Qingzhen was overloaded after 2010 and Xiuwen was overloaded in 2010, 2011, and 2012. Therefore, corresponding countermeasures on sustainable development of Guiyang had been put forward in this study. It is necessary to control the population size, increase the cultivated land resources properly, accelerate regional economic development, strengthen ecological environmental protection, and save energy resources.
Eco-epidemiological assessment of the COVID-19 epidemic in China, January-February 2020
[J].DOI:10.1080/16549716.2020.1760490 URL [本文引用: 2]
A spatio-temporal analysis of the environmental correlates of COVID-19 incidence in Spain
[J].DOI:10.1111/gean.v53.3 URL [本文引用: 2]
Population flow drives spatio-temporal distribution of COVID-19 in China
[J].DOI:10.1038/s41586-020-2284-y URL [本文引用: 2]
The mediating effect of air quality on the association between human mobility and COVID-19 infection in China
[J].DOI:10.1016/j.envres.2020.109911 URL [本文引用: 2]
Copernicus Climate Change Service (C3S)
[DB/OL]. https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels?tab=form.
基于微博签到数据的成渝城市群空间结构及其城际人口流动研究
[J].
DOI:10.12082/dqxxkx.2019.180235
[本文引用: 1]
随着区域一体化进程的加快,中国城市群快速地发展起来,城市群城际间的人口流动研究得到了国内外学者的关注。城市群空间结构的研究以地理实体空间分析为主,城际人口流动的研究多使用传统统计数据,而将大数据运用于城市群空构特征,并结合传统的社会经济统计数据对该区域人口流动的影响因素进行分析。研究发现:① 微博签到数据进一步解释了成渝城市群呈现出“双核多中心”的组团特征,成都市和重庆主城构成了“双核”;② 微博人口流动的方向会受到行政区划的影响,微博人口流动的强度呈现出一定的等级差异;③ 微博人口流动的强度与方向同社会经济发展水平呈现出相对一致性,即地区生产总值越高、人口规模越大或交通联系强度越强,则人口流动越强烈。
Spatial structure and population flow analysis in Chengdu-Chongqing urban agglomeration based on weibo check-in big data
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}