

1 引言
遥感影像场景分类基于全局语义信息识别每幅影像斑块的场景类别。传统的基于人工特征描述符的遥感影像场景分类方法针对纹理特征等全局描述符直接分类[4],或是对尺度不变特征变换等局部描述符进行视觉词袋等编码表示整个场景[5]。由于人工特征的表示能力有限并不适用于复杂场景影像,研究者们转而使用稀疏编码等无监督学习方法[6]。然而,无监督学习方法不能充分利用数据类信息。近年来,随着深度学习的快速发展,卷积神经网络以其强大的特征提取能力广泛应用于场景分类领域并取得了巨大成功[7]。例如,郭子慧等[8]利用经典网络模型对场景进行自动分类,Yu等[9]联合卷积神经网络与集成学习提高场景分类精度。复杂的遥感影像导致场景分类任务面临诸多挑战,针对场景数据类内高差异性和类间低可分性问题,Sun等 [10]嵌入了类内紧凑和类间离散性约束,Chen等[11]引入了全局上下文空间注意模块解决全局多尺度特征提取不充分问题,Wang等[12]则为表征不同尺度特征提出全局-局部双流结构,Peng等[13]在标注样本有限的条件下提出基于多尺度对比学习的弱监督方法分类,Zhang等[14]则提出噪声标签蒸馏方法解决伪标签问题。为应对上述挑战提高分类精度,高性能模型设计的越来越庞大复杂,这严重限制了场景分类算法在机载和星载嵌入式系统上的部署,因而,Zhang等[15]致力于研究紧凑高效的场景分类模型,Chen等[16]则引入知识蒸馏来压缩模型。
知识蒸馏的思想最早可追溯到Bucilua等[21]提出的复杂集成模型可以通过模型压缩转化成简单神经网络的理论。Ba等[22]通过实验完成了验证,提出最小化大模型和小模型的逻辑单元值之间的L2损失可以实现小模型的模拟。然而,这种未经过softmax函数的全连接层的输出值不受约束,在模型训练测试时可能包含噪声。为此,Hinton等[23]提出使用“软目标”,由带温度系数的softmax函数软化输出的类概率,并通过KL散度拟合类概率分布。这种将知识从复杂的教师模型转移到简单的学生模型的过程被开创性的定义为知识蒸馏。随着知识蒸馏的进一步探索,蒸馏的知识得到丰富的扩展。根据知识种类的不同,现有方法可分为基于响应、特征、实例关系和网络层间关系的知识蒸馏。
Romero等[24]认为网络中间隐含层的输出特征图可以作为知识,首次提出以教师网络的中间层(Hint层)为提示指导学生网络对应层(Guided层)学习。随后,Zagoruyko等[25]提出迁移注意力信息,直接模仿教师网络的基于激活或梯度的空间注意力图。Huang等[26]则归纳了激活注意力信息,提出转移神经元的选择性知识。相比于提示知识,激活知识无需额外调整师生网络输出的特征维度。Kim等[27]设计了一个自编码器对教师网络的特征知识进行编解码,将原本难以理解的知识翻译成通俗的信息给学生。Heo等[28]分析了特征蒸馏的设计层面,提出使用margin ReLU激活函数变换教师模型的输出特征,并在ReLU之前使用局部L2距离函数跳过不必要的信息进行蒸馏。Ahn等[29]则从互信息的角度提出最大化师生网络间互信息的变分下界激发知识传递。基于特征的知识蒸馏只学习网络中间某层的输出特征是一种硬约束,忽略了网络结构的知识。Yim等[30]开始将网络不同层间的关系编码为知识,定义两层特征之间的内积为FSP矩阵转移两层间的流动信息。Lee等[31]引入奇异值分解来消除层间特征映射的空间冗余,以径向基函数衡量层模块输入输出端压缩特征的相关性。Chen等[32]提出利用教师网络的多层信息指导学生网络中一层的学习,进一步研究了跨层连接的影响,以基于注意力的融合模块和分层上下文损失函数迁移不同级特征的融合知识。Passalis等[33]探索了图像样本之间的关系,认为单体知识蒸馏默认了数据样本间相互独立,而教师模型中隐式编码了样本及其分布的信息,并提出匹配数据样本的概率密度分布。Tung等[34]进一步构造了实例间的成对相似矩阵。Park等[35]提出关系知识蒸馏,以距离和角度表征结构信息。最近,Zhao等[36]对高度耦合的经典蒸馏损失重新表述,提出解耦知识蒸馏,发掘最初的响应知识的蒸馏潜力。
作为模型压缩的高效手段,知识蒸馏在计算机视觉[37]等领域均取得了令人瞩目的成绩。然而,遥感影像场景分类领域对知识蒸馏的研究相对较少,Chen等[16]最早将经典知识蒸馏引入遥感影像场景分类中,通过匹配深网络与浅网络的softmax层的输出,可有效提高浅网络的性能。Yang等[38]引入知识蒸馏来补偿模型剪枝所引起的精度损失以压缩模型。Zhao等[17]引入成对相似知识蒸馏,并使用mixup技术混合不同标签的样本,通过额外迁移虚拟样本之间相似度的相关性知识来提高学生网络精度。然而,这些方法大多直接应用现有的知识蒸馏算法,忽略了场景分类任务中类内高差异性以及类间低可分性的挑战,丢失了场景数据的类内多样性、类间相似性的判别信息,一定程度上降低了学生网络的分类精度,导致压缩效果表现一般。
为此,本文面向遥感影像场景分类任务,为压缩重量级网络以获得轻量级网络,提出一种类中心知识蒸馏算法,整体框架包括教师网络微调、师生网络蒸馏和学生网络预测3个部分。为使轻量网络能应对场景分类任务中类内高差异性以及类间低可分性的挑战,设计了一种新的蒸馏损失函数,通过约束师生网络提取的同类特征分布中心的距离,高效地转移教师网络强大的特征提取能力,使得学生网络提取的特征类内紧凑并类间离散。本文在四个公开的数据集上评估了所提方法及现有的基于响应、特征、实例关系和网络层间关系的知识蒸馏方法在遥感影像场景分类任务上的性能,实验结果证明了类中心知识蒸馏方法的优效性。
2 理论与方法
本文提出的用于遥感影像场景分类的类中心知识蒸馏算法的模型框架如图1所示,它由教师网络和学生网络2个流组成。首先,将遥感影像场景分类数据集送入经大规模数据集预训练的教师网络中进行参数微调;然后,从调整后的教师网络中提取知识,利用网络中间隐含层的类中心知识指导学生网络进行蒸馏训练,蒸馏损失函数将在2.1节详细介绍;此外,师生网络蒸馏阶段过程中,学生网络还需结合真值标签加以监督,总体损失函数将在2.2节说明。最后,将训练好的学生网络单独用于遥感影像场景预测。模型框架的具体步骤将在2.3节列出。
图1
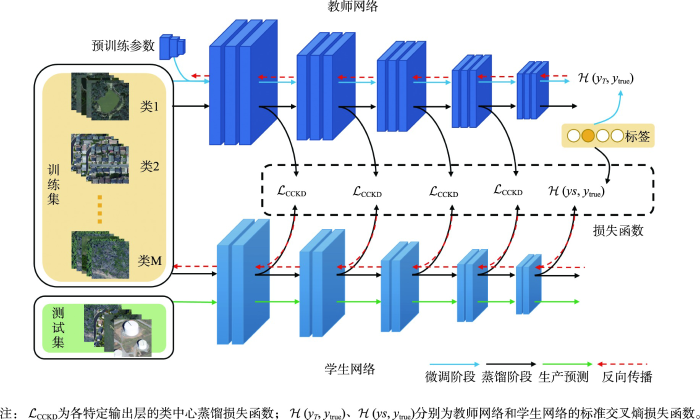
图1
类中心知识蒸馏模型框架
Fig. 1
Framework of class-centered knowledge distillation model
2.1 蒸馏损失函数
遥感影像场景分类面临类内高差异性以及类间低可分性的挑战,现有的知识蒸馏方法忽略了场景数据类内多样性及类间相似性的判别信息,因而未能较好的学习教师模型的特征提取能力。为此,本文设计了一种用于遥感影像场景分类的类中心知识蒸馏损失函数,通过约束师生网络提取的同类特征分布中心的距离完成关于类的知识转移,期望学生模型提取的特征能同教师模型一般具有良好的类内紧凑性和类间离散性。
2.1.1 神经元选择性迁移算法
式中:样本
NST算法视每个空间位置的激活值为一个特征
受上述方法启发,本文进一步将同类的特征分布凝练为知识。同类实例的特征分布相似,将其映射到高维空间中会形成一个簇,教师模型提取的类内紧凑并类间离散的特征体现在簇的信息中,将其表征为类特征知识,供学生模型学习。具体而言,针对师生网络的某一个或几个特定层的输出特征按标签分类,求解同标签各实例的特征分布的中心,通过最小化师生间的每类中心的距离实现学生模型学习教师模型提取的类特征知识。
2.1.2 类中心知识蒸馏损失
本文将网络中某一特定输出层的特征图表示为
注意,师生网络对应输出层的特征图应具有相同的空间维数
映射函数
式中:
然后,对M个类中心距离求和得到某一特定输出层的类中心知识蒸馏损失函数值
本文设计对网络中间多个输出层的特征图进行蒸馏(图1),输出层的选取将在实验设置介绍。
2.2 总体损失函数
在训练过程中,强制学生模型使用标准交叉熵损失函数匹配地面真值标签有利于学生模型提高性能,如式(6)所示。
式中:
因而,在训练过程中整个目标函数包含类中心蒸馏损失和标准交叉熵损失两部分,可表示为
式中:
2.3 算法具体流程
首先用标准的监督学习策略训练教师模型,为使教师模型获得良好的特征表示能力,采用预训练-微调机制,提前于ImageNet数据集对教师模型进行预训练,再将模型送入遥感场景分类数据集进行微调。微调后的教师网络指导学生网络训练,学生网络按照类中心蒸馏损失学习教师网络提取特征的能力,并受真值标签的监督。最后,单独测试学生网络预测性能。类中心知识蒸馏算法如下。
| 算法1 类中心知识蒸馏算法 |
|---|
| 第一阶段:微调教师网络 |
| 输入:教师网络模型 |
| 计算标准交叉熵损失函数 |
| 反向传播更新 |
| 输出:教师网络模型 |
| 第二阶段:通过类中心蒸馏训练学生网络 |
| 输入:教师网络模型 |
| 初始化:学生网络参数 |
| 按标签 抽取随机的样本 |
| 根据式(7)计算总体损失函数 |
| 反向传播更新学生网络的参数 |
| 输出:学生网络模型 |
| 第三阶段:测试学生网络 |
| 输入:学生网络模型 |
| 输出:预测结果 |
| 按标签 抽取随机的样本 |
3 实验与分析
3.1 数据集
本文在RSC11[41]、UC Merced Land-use(UCM)[42]、RSSCN7[43]和Aerial Image Dataset(AID)[44] 4个主流的遥感影像场景分类数据集上进行综合实验,数据集详细情况如表1所示。从数据集中随机抽取一些图像作为示例样本,如图2所示。从图2左边2列可以发现这些场景分类数据集的类内多样性大,如种植地、住宅区、草地、旅游胜地等;从图2右四列可以观察到数据集中某些场景类具有很高的相似性,如RSC11数据集中的公路、立交、铁路三类,UCM 数据集中各种细分的住宅区与建筑物,RSSCN7数据集中的工业区与住宅区、农田与草地,AID数据集中的沙漠与裸地、湖泊与公园都非常相似,难以区分。这对结构紧凑的轻量级分类网络提出巨大的挑战。
表1 遥感影像场景分类数据集
Tab. 1
| 数据集 | 分辨率/m | 类别数/个 | 尺寸/mm | 每类样本数/个 | 样本总数/个 | 特点 |
|---|---|---|---|---|---|---|
| RSC11 | 0.2 | 11 | 512 × 512 | 约100 | 1232 | 小型的遥感影像场景分类数据集 |
| UCM | 0.3 | 21 | 256 × 256 | 100 | 2100 | 经典的高分辨率土地利用数据集 |
| RSSCN7 | - | 7 | 400 × 400 | 400 | 2800 | 涵盖4个采样尺度的, 类内多样性大的场景分类数据集 |
| AID | 0.5~0.8 | 30 | 600 × 600 | 200~400 | 10000 | 复杂的多源、多分辨率、类间相似性高、样本不均衡的航空图像数据集 |
图2

图2
4个遥感影像场景分类数据集的示例样本
Fig. 2
Example samples of four remote sensing image scene classification datasets
3.2 实验设置
表2 师生网络结构及输出层特征信息
Tab. 2
| 网络名称 | ResNet50 | ResNet18 | MobileNetV2 |
|---|---|---|---|
| 卷积池化层 | |||
| 卷积层1 | |||
| 输出层特征1 | |||
| 卷积层2 | |||
| 输出层特征2 | |||
| 卷积层3 | |||
| 输出层特征3 | |||
| 卷积层4 | |||
| 输出层特征4 | |||
| 全局池化层 |
注:F表示设计蒸馏网络中间输出层的特征图;
实验配置。本文使用NVIDIA Tesla 4在PyTorch环境下进行综合实验。在训练阶段,我们采用随机翻转和随机半径的高斯模糊进行数据增强。在测试阶段,不对测试数据进行增强。教师网络微调过程设置批大小为64,初始学习率为1e-4,按指数衰减调整学习率,使用动量为0.9的随机梯度下降(SGD)作为优化器,迭代次数设置为160。学生网络单独训练过程和知识蒸馏过程均设置批大小为32,初始学习率为0.05,仍按指数衰减调整学习率,使用动量为0.9的随机梯度下降(SGD)作为优化器,迭代次数设置为240。所有训练均采用提前终止策略,如果验证损失在连续30次迭代计算后没有降低,则终止训练。
超参数设置。本文设置平衡因子
3.3 实验结果与分析
3.3.1 有效性实验
表3 UCM数据集上各种知识蒸馏方法的总体精度
Tab. 3
| 蒸馏方法 | 师生架构 (Model T/S) | 同系列 (ResNet-50/ ResNet-18) | 不同系列 (ResNet-50/MobileNet-V2) | ||
|---|---|---|---|---|---|
| 训练比率 | 80% | 60% | 80% | 60% | |
| Baseline | 92.14 | 90.00 | 91.43 | 90.48 | |
| 响应 | KD | 95.48 | 92.38 | 93.33 | 90.24 |
| DKD | 95.71 | 91.91 | 94.52 | 92.14 | |
| 特征 | NST | 94.05 | 91.67 | 92.62 | 90.48 |
| VID | 93.57 | 89.41 | 92.38 | 89.05 | |
| 网络层间关系 | KDSVD | 92.62 | 90.36 | 92.62 | 89.88 |
| ReviewKD | 94.29 | 92.62 | 94.29 | 91.07 | |
| 实例关系 | RKD | 94.52 | 92.02 | 92.38 | 87.38 |
| SP | 93.33 | 91.43 | 80.48 | 59.05 | |
| 类中心 | 本文方法 | 97.14 | 95.36 | 94.76 | 92.62 |
注:Baseline是指单独训练学生网络的结果。在所有方法中精度最高的结果表示为粗体,次高的表示为下划线。结果取10次实验平均值。
在师生网络属同系列的实验中可以观察到,类中心知识蒸馏方法与单独训练学生网络相比提高了超5%的分类总体精度,在80%的训练比率下与最先进的DKD方法相比实现了1.43%的改进,总体精度高达97.14%,训练比率为60%时则较精度最优的ReviewKD方法提升了2.74%,达到95.36%的总体精度。
在师生网络属不同系列的实验中,精度同样有提升,以MobileNet-V2为学生模型的蒸馏结果显示所提方法在80%、60%的训练比率下分别获得了94.76%和92.62%的精度,比单独训练提高了3.33%、2.14%,分别超性能第二的蒸馏方法0.24%、0.48%。
实验结果表明,本文提出的方法与单独训练相比取得了显著的改进,并优于目前先进的知识蒸馏方法。因此,本文认为所提方法可以有效地从教师模型中提取有价值的信息转化为知识迁移至学生模型供其学习。综合2组实验来看,训练比率越低,所提方法精度提升的幅度越大,类中心知识蒸馏的优势越明显。
表4展示了网络模型压缩前后尺寸的对比,以计算量(Floating Point Operations, FLOPs)衡量模型运算的复杂度,以参数量(Parameters)衡量模型存储的大小,压缩率是指学生网络(模型压缩后)与教师网络(模型压缩前)大小之比。
表4 网络模型尺寸对比
Tab. 4
| 模型 | FLOPs (G) | Parameters (M) | 压缩率/% |
|---|---|---|---|
| ResNet50 | 32.88 | 23.55 | |
| ResNet18 | 14.55 | 11.19 | 47.52 |
| MobileNetV2 | 2.50 | 2.25 | 9.55 |
结果表明,在训练率为60% UCM数据集上,相比于ResNet50模型,ResNet18模型实现了47.52%的压缩率并补偿了5.36%的精度,MobileNetV2模型则达到9.55%的压缩率并将计算复杂度降低至原来的7.6%。
3.3.2 适用性实验
为验证类中心知识蒸馏方法的普适性,本文将在RSC11少类少样本的小型数据集、RSSCN7少类多样本的多尺度数据集及AID多类不均样本的大型复杂数据集上进行补充实验。表5展示了在训练比率为60%的多个数据集上进行的师生网络同属一系列的实验结果,本文提出的方法在RSC11和AID数据集上分别获得了94.37%和94.10%的精度,与单独训练相比,提高了4.23%和5.12%,相较于性能第二的知识蒸馏方法分别有 2.42%和1.07%的提升。
表5 多个数据集在60%训练比率及同构师生网络条件下的总体精度
Tab. 5
| 数据集 | 教师网络 | 学生网络 | 响应 | 特征 | 网络层间关系 | 实例关系 | 类中心 | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| KD | DKD | NST | VID | KDSVD | ReviewKD | RKD | SP | 本文方法 | |||
| RS_C11 | 92.35 | 90.14 | 91.95 | 90.95 | 89.74 | 88.13 | 87.73 | 90.34 | 89.74 | 87.73 | 94.37 |
| RSSCN7 | 91.07 | 88.75 | 88.30 | 87.32 | 87.59 | 87.41 | 87.05 | 88.21 | 88.75 | 86.52 | 91.70 |
| AID | 95.68 | 88.98 | 92.73 | 93.03 | 91.43 | 88.96 | 89.20 | 92.58 | 91.45 | 91.65 | 94.10 |
注:教师网络为ResNet-50,展示的是经预训练-微调后的分类结果,学生网络为ResNet-18,表示的是不经蒸馏单独训练的结果。在所有方法中精度最高的结果表示为粗体,次高的表示为下划线,斜体粗体意味着超过教师分类精度。结果取10次实验平均值。
值得注意的是,目前先进的知识蒸馏方法在RSSCN7数据集上的表现较差,精度相较于单独训练学生网络不升反降,仅有RKD方法保持了精度,而本文提出的方法则有2.95%的提升,精度达到91.70%。还可以观察到,在RSC11和RSSCN7 2类别较少的数据集上,所提蒸馏方法不仅实现了与单独训练相比的显著改进,甚至超过了预训练微调下教师模型的精度,说明类中心知识蒸馏方法相比于其他蒸馏方法转移了更专用的知识,具体原因将在后续分析。
综上分析,在不同架构的师生网络、不同比率的训练样本和不同规模的数据集的3组实验中,本文提出的方法表现优异,精度与单独训练学生网络和先进知识蒸馏方法相比均有提升,说明所提方法具有良好的泛化能力。
3.3.3 技术对比实验
本文受NST算法启发而提出类中心知识蒸馏方法,为验证所提方法的优越性,本文在RSC11 Dataset数据集上对2种蒸馏方法进行对比实验,并结合微调的ResNet-50教师网络、单独训练的ResNet-18学生网络的实验结果进行分析。为保证变量唯一,先对NST蒸馏方法进行改进,针对本文同样的输出层特征进行匹配,以研究类中心知识的有效性。
表6 RSC11数据集上对比实验的结果
Tab.6
| Student | Teacher | NST | NST_all | 本文方法 | 较次高 提升精度 | |
|---|---|---|---|---|---|---|
| 总体精度 | 90.14 | 92.35 | 89.74 | 92.56 | 94.37 | 1.81 |
注:精度最高的结果表示为粗体,次高的表示为下划线
表7 对比实验在RSC11数据集上的精度混淆矩阵
Tab. 7
| 单独训练的学生网络 | 微调的教师网络 | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 密林 | 草地 | 港口 | 高建筑 | 低建筑 | 立交 | 铁路 | 居民区 | 公路 | 疏林 | 储存罐 | 密林 | 草地 | 港口 | 高建筑 | 低建筑 | 立交 | 铁路 | 居民区 | 公路 | 疏林 | 储存罐 | ||
| 密林 | 98.21 | 1.79 | 密林 | 100 | |||||||||||||||||||
| 草地 | 100 | 草地 | 100 | ||||||||||||||||||||
| 港口 | 97.22 | 2.78 | 港口 | 100 | |||||||||||||||||||
| 高建筑 | 91.11 | 2.22 | 2.22 | 4.44 | 高建筑 | 97.62 | 2.38 | ||||||||||||||||
| 低建筑 | 85.42 | 6.25 | 8.33 | 地建筑 | 91.67 | 4.17 | 2.08 | 2.08 | |||||||||||||||
| 立交 | 2.33 | 74.42 | 2.33 | 18.6 | 2.33 | 立交 | 2.27 | 68.18 | 9.09 | 20.45 | |||||||||||||
| 铁路 | 3.12 | 3.12 | 87.5 | 6.25 | 铁路 | 8.00 | 88.00 | 4.00 | |||||||||||||||
| 居民区 | 1.61 | 1.61 | 87.1 | 4.84 | 4.84 | 居民区 | 1.79 | 98.21 | |||||||||||||||
| 公路 | 1.89 | 1.89 | 9.43 | 3.77 | 83.02 | 公路 | 3.28 | 13.11 | 8.20 | 75.41 | |||||||||||||
| 疏林 | 2.17 | 97.83 | 疏林 | 100 | |||||||||||||||||||
| 储存罐 | 5.71 | 2.86 | 91.43 | 储存罐 | 100 | ||||||||||||||||||
| 基于改进NST方法训练的学生网络 | 基于本文方法训练的学生网络 | ||||||||||||||||||||||
| 密林 | 草地 | 港口 | 高建筑 | 低建筑 | 立交 | 铁路 | 居民区 | 公路 | 疏林 | 储存罐 | 密林 | 草地 | 港口 | 高建筑 | 低建筑 | 立交 | 铁路 | 居民区 | 公路 | 疏林 | 储存罐 | ||
| 密林 | 100 | 密林 | 100 | ||||||||||||||||||||
| 草地 | 100 | 草地 | 100 | ||||||||||||||||||||
| 港口 | 92.31 | 2.56 | 5.13 | 港口 | 100 | ||||||||||||||||||
| 高建筑 | 90.91 | 4.55 | 2.27 | 2.27 | 高建筑 | 97.73 | 2.27 | ||||||||||||||||
| 地建筑 | 2.50 | 95.00 | 2.5 | 低建筑 | 95.24 | 2.38 | 2.38 | ||||||||||||||||
| 立交 | 89.19 | 5.41 | 5.41 | 立交 | 86.11 | 5.56 | 2.78 | 5.56 | |||||||||||||||
| 铁路 | 3.12 | 3.12 | 87.5 | 3.12 | 3.12 | 铁路 | 3.33 | 6.67 | 90.00 | ||||||||||||||
| 居民区 | 1.67 | 91.67 | 3.33 | 3.33 | 居民区 | 1.69 | 1.69 | 1.69 | 93.22 | 1.69 | |||||||||||||
| 公路 | 14.75 | 3.28 | 81.97 | 公路 | 15.15 | 3.03 | 81.82 | ||||||||||||||||
| 疏林 | 2.17 | 97.83 | 疏林 | 100 | |||||||||||||||||||
| 储存罐 | 7.14 | 92.86 | 储存罐 | 2.33 | 97.67 | ||||||||||||||||||
由表7可知,本文提出的方法对所有分类都提升了精度,其中港口和高建筑相比于改进的NST蒸馏方法提高了7.69%和6.80%,其他类别的精度也都有1%~4%的提升。分类精度相对较低的是公路、立交和铁路,值得注意的是,也正是这三类的分类精度不仅比单独训练的学生模型高甚至都大幅度超过了教师模型,本文分析认为这些具有挑战性的类别经蒸馏后不仅保持了学生网络对这些类的区分能力,还学习到教师网络中的知识,达到较高精度。另外,从可视化测试误差曲线(图3)中可以观察到与单独训练(绿色线)相比,本文方法(蓝色线)能够快速收敛,改进的NST蒸馏方法(红色线)的测试误差曲线同样快速收敛但紧接着发生振荡并有上浮趋势,说明NST蒸馏损失受随机样本的影响大,训练模型存在过拟合的风险,而我们所提出的类中心蒸馏损失能够很好处理噪声,损失值快速收敛并趋于稳定。
图3
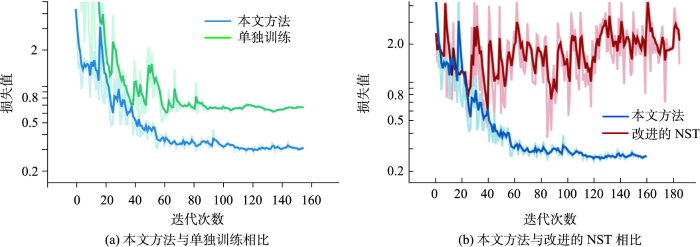
3.3.4 可视化分析
本文在具有挑战性的RSSCN7数据集上使用T-SNE算法[47]可视化模型的特征提取能力。T-SNE算法用于高维数据降维,可将高维特征表示在二维可视空间中。通过T-SNE算法将模型提取的高维特征可视化,以衡量所提方法能否有效地解决类内多样性和类间相似性问题。
如图4所示,与单独训练的学生模型和基于改进的NST方法相比,本文方法所提取的特征,类别相同的特征簇更紧凑,而类别不同的特征簇相对分散,尤其是红色圈内的三类特征簇,表现的最为明显。说明本文方法提取的特征具有良好的类内紧凑性和类间离散性,有效地应对了遥感影像场景类内多样性和类间相似性问题。
图4
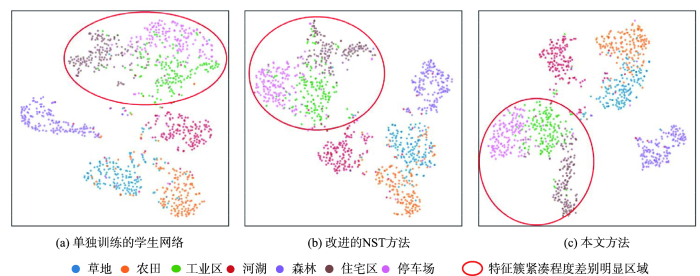
图4
RSSCN7数据集经T-SNE算法可视化的特征散点图
Fig. 4
Characteristic scatter plot of RSSCN7 dataset visualized by T-SNE algorithm
为了进一步分析学生网络学习的效果,本文对蒸馏过程中设计匹配的四个网络中间输出层进行可视化,利用Selvaraju等[48]提出的Grad-CAM(Gradient-weighted Class Activation Mapping)绘制热力图来显示网络中间层关注的区域及特征信息,以此探查学生网络的特征提取能力。如图5所示,热力图中颜色越深的区域为关注度越高。横向分析可以发现不同网络输出层的侧重点不同,层级越深关注的特征越抽象,如特征层1主要关注边缘特征,特征层4则重点关注语义场景特征。纵向分析不同方法同一输出层关注区域的差别,相比于单独训练方法和改进的NST方法,本文方法综合了教师网络和学生网络关注区域,说明本文方法很好的传递了教师网络的特征提取能力。
图5
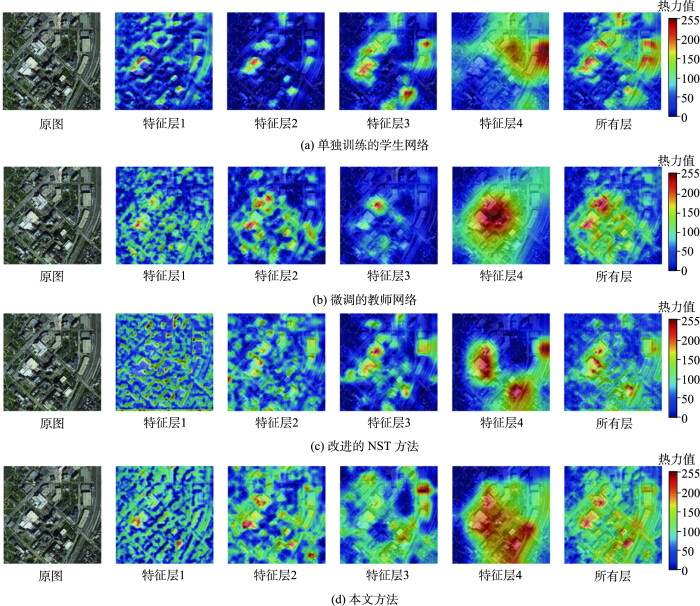
图5
输出特征层的热力图
注:热力值表示模型注意力的可视化结果,数值高代表模型关注该区域。
Fig. 5
Gradient-weighted class activation mapping of output the feature layer
从所有输出层的热力图来看,本文方法关注感受野更大,不容易因过于聚焦场景内类间相似性地物而预测错误。原图为工业区,改进的NST方法因过于关注图中房屋而错误预测为住宅区,受噪声影响大,同时也说明了本文方法提取的特征能有效应对类间相似性挑战。
4 结论
本文面向遥感影像场景分类任务提出了一种类中心知识蒸馏方法,通过教师网络微调、师生网络蒸馏两步训练,获得一个能部署到边缘计算设备中的高性能轻量网络。本文设计的类中心蒸馏损失函数通过匹配师生网络提取的同类特征分布的中心,高效地转移了复杂网络强大的特征提取能力,使得轻量网络在场景分类任务中能应对类内高差异性以及类间低可分性的挑战。本文在4个公开的遥感影像场景分类基准数据集上进行了一系列综合实验,以评估类中心知识蒸馏方法的优效性实验结论总结如下:
(1)本文在经典的UCM高分辨率土地利用数据集上,于60%和80% 2种训练比率以及ResNet50与ResNet18和ResNet50与MobileNet-V2两种师生架构的条件下进行了有效性实验,并与4类8种现有的先进知识蒸馏方法进行了对比。实验结果表明,类中心知识蒸馏方法在同构、异构的师生网络中表现均最优,尤其是训练比率越低精度提升幅度越大。随后,本文在RSC11少类少样本的小型数据集、RSSCN7少类多样本的多尺度数据集及AID多类不均样本的大型复杂数据集上进行了适用性实验,实验结果证明所提方法具有良好的泛化能力。
(2)本文还与改进的NST算法进行了技术对比实验,通过混淆矩阵发现在具有挑战性的类别中类中心知识蒸馏方法仍能保持优异性,不仅保持了学生网络的分类能力,还学习到教师网络中的知识,测试误差曲线则表明了所提蒸馏损失函数能较好地处理噪声而使损失值快速收敛并趋于稳定,验证了本文方法的优越性。此外,本文基于T-SNE算法可视化了模型的特征提取能力,并基于Grad-CAM绘制了热力图可视化输出层关注区域,结果表明本文方法提取的特征具有良好的类内紧凑性和类间离散性。
综上,本文提出的类中心知识蒸馏方法提高了紧凑网络的分类精度,与其他蒸馏方法相比表现最优。本文重点关注了如何更好地衡量师生特征间的接近程度,限于篇幅和时间暂时没有探索何处的知识最佳,后续将进一步的深入研究最佳蒸馏位置的选择和组合问题。未来研究还将进一步探索类中心知识蒸馏方法的价值,实现在目标检测、语义分割任务上的应用。
参考文献
A multi-level semantic scene interpretation strategy for change interpretation in remote sensing imagery
[J].
Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery
[J].
A survey on deep learning-driven remote sensing image scene understanding: Scene classification, scene retrieval and scene-guided object detection
[J].
Multiresolution gray-scale and rotation invariant texture classification with local binary patterns
[J].
Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery
[J].
Unsupervised deep feature extraction for remote sensing image classification
[J].
Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities
[J].
深度学习和遥感影像支持的矢量图斑地类解译真实性检查方法
[J].
DOI:10.12082/dqxxkx.2020.200001
[本文引用: 1]

空间数据质量检查是数据准确可靠的重要保障,是数据的生命线。然而,目前的空间数据质量检查主要针对拓扑关系、属性一致性以及数据间的相关性进行检查,往往忽视矢量图斑地类解译真实性问题。因此,本文提出深度学习和高分遥感影像支持的矢量图斑地类解译真实性检查方法,选用深度学习经典模型Inception_v3进行迁移学习,对分割后的影像进行自动场景分类,以高分遥感影像块的场景分类结果作为参照依据,对场景分类结果与矢量图斑原始数据进行叠加分析,自动查找出类别信息不符的分割单元,从而提取出可疑图斑,实现矢量图斑地类解译真实性自动检查,并在徐州市贾汪区青山泉镇和大吴镇的矢量图斑地类解译真实性检查中进行验证。实验结果表明,本文方法在研究区图斑地类解译真实性检查中的精确率和召回率分别高达0.925和0.817,可为矢量图斑地类解译真实性检查提供可靠的技术支撑。
Land type interpretation authenticity check of vector patch supported by deep learning and remote sensing image
[J].
联合卷积神经网络与集成学习的遥感影像场景分类
[J].
Scene classification of remote sensing image using ensemble convolutional neural network
[J].
Convolutional neural networks based remote sensing scene classification under clear and cloudy environments
[C]//
GCSANet: A global context spatial attention deep learning network for remote sensing scene classification
[J].
Looking closer at the scene: Multiscale representation learning for remote sensing image scene classification
[J].
基于多尺度对比学习的弱监督遥感场景分类
[J].
DOI:10.12082/dqxxkx.2022.210809
[本文引用: 1]
遥感场景分类作为一种理解遥感影像的重要方式,在目标检测、影像快速检索等方向有着重要的应用,当前主流的场景分类方法多关注影像深层次特征的准确提取,忽略了场景目标在不同分布尺度下的差异性。此外,有限的高质量场景标签进一步限制了模型分类性能。为了解决以上问题,本研究提出了基于多尺度对比学习的弱监督遥感场景分类方法,首先利用多尺度对比学习的自监督策略,从大量无标注数据中自动获取影像不同尺度下的特征表示。其次,基于多尺度稳健特征对分类模型利用少量标签进行微调,并结合标签传播方法生成高质量样本标签。最后,结合大量无标签数据构建弱监督分类模型,进一步提升场景分类的能力。本研究在遥感场景AID数据集和NWPU-RESISC45数据集上分别使用1%、5%和10%的标注样本下分类精度分别达到了87.7%、93.67%、95.56%和86.02%、93.15%和95.38%,在有限标注样本条件下与其他基准模型相比有着明显的优势,证明了本文模型的有效性。
Multi-scale contrastive learning based weakly supervised learning for remote sensing scene classification
[J].
Remote sensing image scene classification with noisy label distillation
[J].
DOI:10.3390/rs12010012
URL
[本文引用: 1]
The dynamic response of coastal wetlands (CWs) to hydro-meteorological signals is a key indicator for understanding climate driven variations in wetland ecosystems. This study explored the response of CW dynamics to hydro-meteorological signals using time series of Landsat-derived normalized difference vegetation index (NDVI) values at six locations and hydro-meteorological time-series from 1984 to 2015 in Apalachicola Bay, Florida. Spectral analysis revealed more persistence in NDVI values for forested wetlands in the annual frequency domain, compared to scrub and emergent wetlands. This behavior reversed in the decadal frequency domain, where scrub and emergent wetlands had a more persistent NDVI than forested wetlands. The wetland dynamics were found to be driven mostly by the Apalachicola Bay water level and precipitation. Cross-spectral analysis indicated a maximum time-lag of 2.7 months between temperature and NDVI, whereas NDVI lagged water level by a maximum of 2.2 months. The quantification of persistent behavior and subsequent understanding that CW dynamics are mostly driven by water level and precipitation suggests that the severity of droughts, floods, and storm surges will be a driving factor in the future sustainability of CW ecosystems.
A lightweight and discriminative model for remote sensing scene classification with multidilation pooling module
[J].With the growing spatial resolution of satellite images, high spatial resolution (HSR) remote sensing imagery scene classification has become a challenging task due to the highly complex geometrical structures and spatial patterns in HSR imagery. The key issue in scene classification is how to understand the semantic content of the images effectively, and researchers have been looking for ways to improve the process. Convolutional neural networks (CNNs), which have achieved amazing results in natural image classification, were introduced for remote sensing image scene classification. Most of the researches to date have improved the final classification accuracy by merging the features of CNNs. However, the entire models become relatively complex and cannot extract more effective features. To solve this problem, in this paper, we propose a lightweight and effective CNN which is capable of maintaining high accuracy. We use MobileNet V2 as a base network and introduce the dilated convolution and channel attention to extract discriminative features. To improve the performance of the CNN further, we also propose a multidilation pooling module to extract multiscale features. Experiments are performed on six datasets, and the results verify that our method can achieve higher accuracy compared to the current state-of-the-art methods.
Training small networks for scene classification of remote sensing images via knowledge distillation
[J].
Pair-wise similarity knowledge distillation for RSI scene classification
[J].Remote sensing image (RSI) scene classification aims to identify the semantic categories of remote sensing images based on their contents. Owing to the strong learning capability of deep convolutional neural networks (CNNs), RSI scene classification methods based on CNNs have drawn much attention and achieved remarkable performance. However, such outstanding deep neural networks are usually computationally expensive and time-consuming, making them impossible to apply on resource-constrained edge devices, such as the embedded systems used on drones. To tackle this problem, we introduce a novel pair-wise similarity knowledge distillation method, which could reduce the model complexity while maintaining satisfactory accuracy, to obtain a compact and efficient deep neural network for RSI scene classification. Different from the existing knowledge distillation methods, we design a novel distillation loss to transfer the valuable discriminative information, which could reduce the within-class variations and restrain the between-class similarity, from the cumbersome model to the compact model. This method could obtain the compact student model with higher performance compared with existing knowledge distillation methods in RSI scene classification. To be specific, we distill the probability outputs between sample pairs with the same label and match the probability outputs between the teacher and student models. Experiments on three public benchmark datasets for RSI scene classification, i.e., AID, UCMerced, and NWPU-RESISC datasets, verify that the proposed method could effectively distill the knowledge and result in a higher performance.
Pruning filters for efficient ConvNets
[EB/OL].
Designing energy-efficient convolutional neural networks using energy-aware pruning
[C]//
Knowledge distillation: A survey
[J].
Model compression
[C]//
Do deep nets really need to be deep?
[C].
Distilling the knowledge in a neural network
[EB/OL].
FitNets: Hints for thin deep nets
[EB/OL].
Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer
[EB/OL].
Like what You like: Knowledge distill via neuron selectivity transfer
[EB/OL].
Paraphrasing complex network: Network compression via factor transfer
[EB/OL].
A comprehensive overhaul of feature distillation
[C]//
Variational information distillation for knowledge transfer
[C]//
A gift from knowledge distillation: Fast optimization, network minimization and transfer learning
[C]//
Distilling knowledge via knowledge review
[C]//
Similarity-preserving knowledge distillation
[C]//
Relational knowledge distillation
[C]//
Decoupled knowledge distillation
[C]//
Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks
[J].
基于剪枝网络的知识蒸馏对遥感卫星图像分类方法
[J].
Knowledge distillation method for remote sensing satellite image classification based on pruning network
[J].
A kernel two-sample test
[J].
Feature significance-based multibag-of-visual-words model for remote sensing image scene classification
[J].
Deep learning based feature selection for remote sensing scene classification
[J].
Hybrid collaborative representation for remote-sensing image scene classification
[J].
AID: A benchmark data set for performance evaluation of aerial scene classification
[J].
Aggregated residual transformations for deep neural networks
[C]//
MobileNetV2: inverted residuals and linear bottlenecks
[C]//
Visualizing data using t-sne
[J].
Grad-CAM: Visual explanations from deep networks via gradient-based localization
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}