
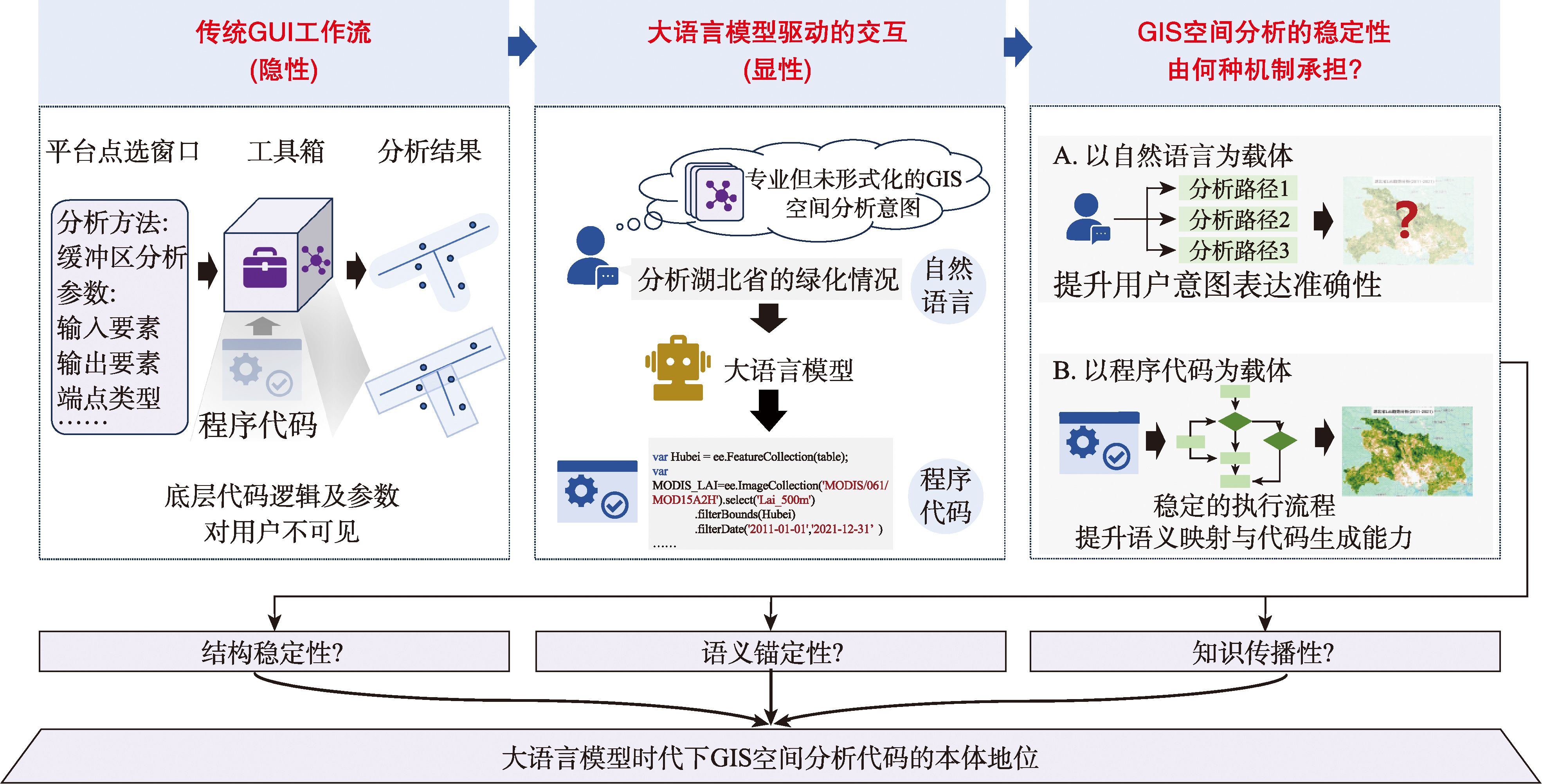
【背景】大语言模型(Large Language Model, LLM)的出现推动地理信息系统(Geographic Information System, GIS)空间分析的交互范式发生深刻变革:由早期“用户直接编写代码驱动分析”、中期“通过GUI工具链配置间接调用代码”的模式,逐步转向“自然语言-代码-空间分析”的新型交互范式。在此范式下,自然语言与程序代码并列登台,成为驱动GIS空间分析的媒介。然而,二者在执行结构的稳定性、空间语义的明确性及分析过程的可传播性上存在差异,辨析何者为当下GIS空间分析的本体,有助于明确大语言模型驱动GIS空间分析的优化方向。 【分析】在此背景下,本文对GIS空间分析代码的本体定位展开论证:首先界定GIS空间分析代码的概念内涵,将其归纳为5种功能类型,并从本地通用编程环境、空间资源托管型云平台、数据库内嵌环境及知识图谱环境4类执行平台刻画其能力边界。其次,从结构稳定性、语义锚定性与知识传播性3个维度阐释代码的驱动机制,论证代码作为空间分析科学有效性得以成立的最小完备单元所具备的本体地位。 【进展与展望】在此基础上,综述LLM时代以GIS空间分析代码为核心的研究进展,并辨证讨论空间语义结构感知、领域自适应学习、自主智能体生态、知识迁移与积累、代码定位修复等具备研究条件但尚未系统展开的方向,以及数据与知识治理、空间计算能力、因果解释能力、地理空间表征模型等仍缺乏基础支撑却亟待探索的方向。 【目的】本文围绕驱动机制展开的系统化分析,明确LLM时代下GIS空间分析代码的理论角色与方法论意义,阐明该领域的理论框架与能力边界,为GIS空间智能化研究提供理论参考。
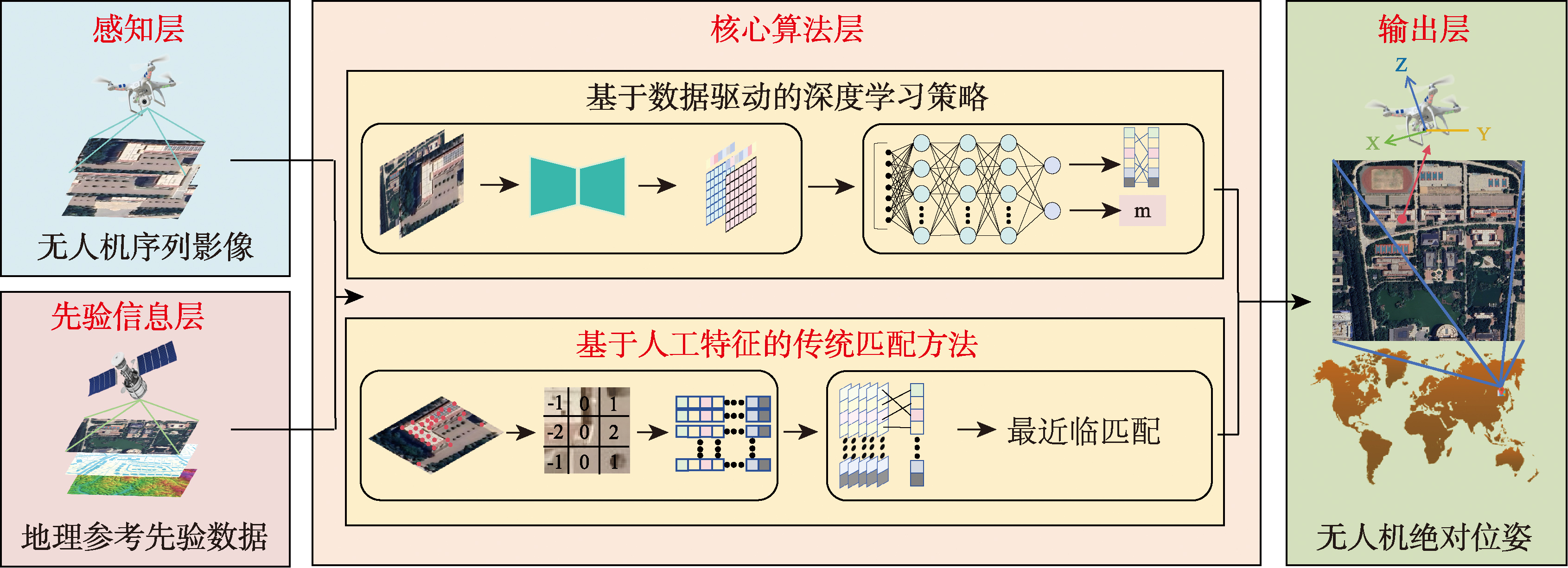
【意义】在全球导航卫星系统(Global Navigation Satellite System, GNSS)拒止环境下,无人机(Unmanned Aerial Vehicle, UAV)自主定位所面临的信号中断与精度衰减挑战严重制约其任务执行效能。视觉绝对定位(Absolute Visual Localization, AVL)方法作为关键的替代方案,通过建立无人机影像与带有地理参考的先验数据,如卫星影像、语义地图等之间的映射关系,实现无人机在全局坐标系中的位姿估计,已然成为全时域、多场景鲁棒定位的重要方法。 【分析】本文系统梳理了无人机AVL方法的研究进展,从“特征表征”和“范式革新” 2个角度,阐述了该领域从传统人工设计特征到深度学习策略的演进过程,对比分析了各类方法在定位精度、计算效率以及环境适应性等方面的性能差异。着重讨论了端到端连续位置回归、视觉—语言模型、几何结构对齐等新兴范式,对传统“检索-匹配”流程的系统性重构,指出其在场景扩展性、跨域泛化能力等方面的优势。在此基础上,整合当前公开数据集与相关评估指标,深入分析了现有方法在模型泛化性、边缘设备部署适配性、多源信息融合等方面存在的关键挑战。 【展望】从多源融合策略、算法轻量化以及跨域泛化性3个角度,探讨了该领域未来可能的发展方向,为推动无人机AVL技术的进一步发展提供参考。
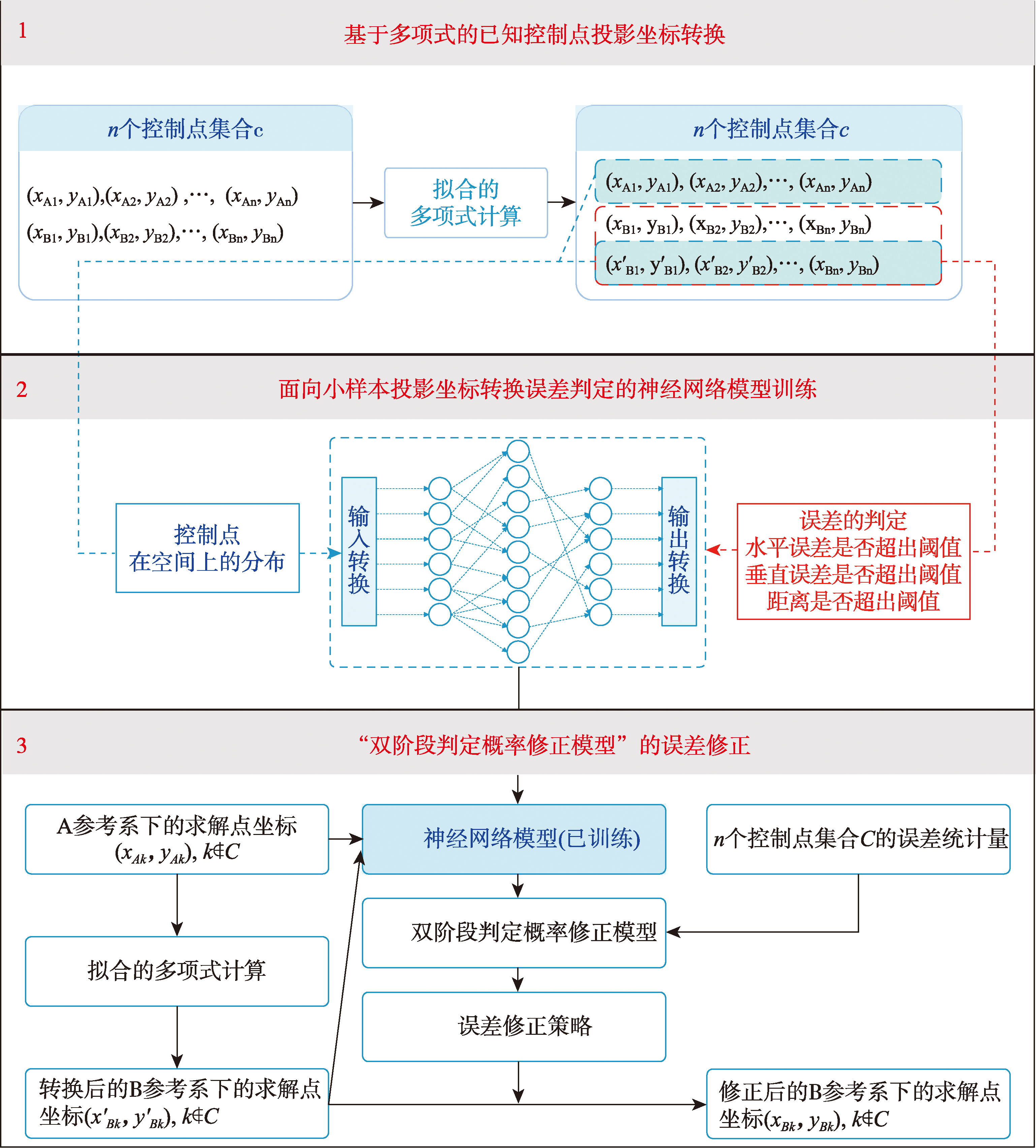
【目的】针对控制点数量有限条件下神经网络投影坐标转换存在精度较低、稳定性和可解释性较差等问题,本文提出了一种基于神经网络双阶段判定的小样本投影坐标转换方法。 【方法】该方法将传统基于神经网络建立坐标系映射关系的回归问题,转化为两类判定问题:一是判定转换后的距离误差是否在阈值范围内,二是判定水平与垂直方向误差是否落在给定分布区域内。针对两类判定结果可能出现的矛盾或一致情况,设计了一种“双阶段判定概率修正模型”以修正转换误差的方法,从而提升投影坐标转换精度与稳定性。 【结果】试验中选择了某一区域(约10万 km2)438个点,随机构造6组训练集与测试集进行验证,与常规神经网络模型进行对照,结果表明本文方法平均精度提升约10%,转换错误率由40.6%降至12.9%。 【结论】本方法解决了传统神经网络方法在小样本控制点条件下,单点和多点坐标转换错误率高、可解释性差等核心问题,同时模型训练简单快速,具备较强的工程扩展性,可根据实际数据特点调整相关方法和参数,可扩展到无人机平台等其他平台坐标转换场景,在测绘工程领域展现出良好的应用潜力。
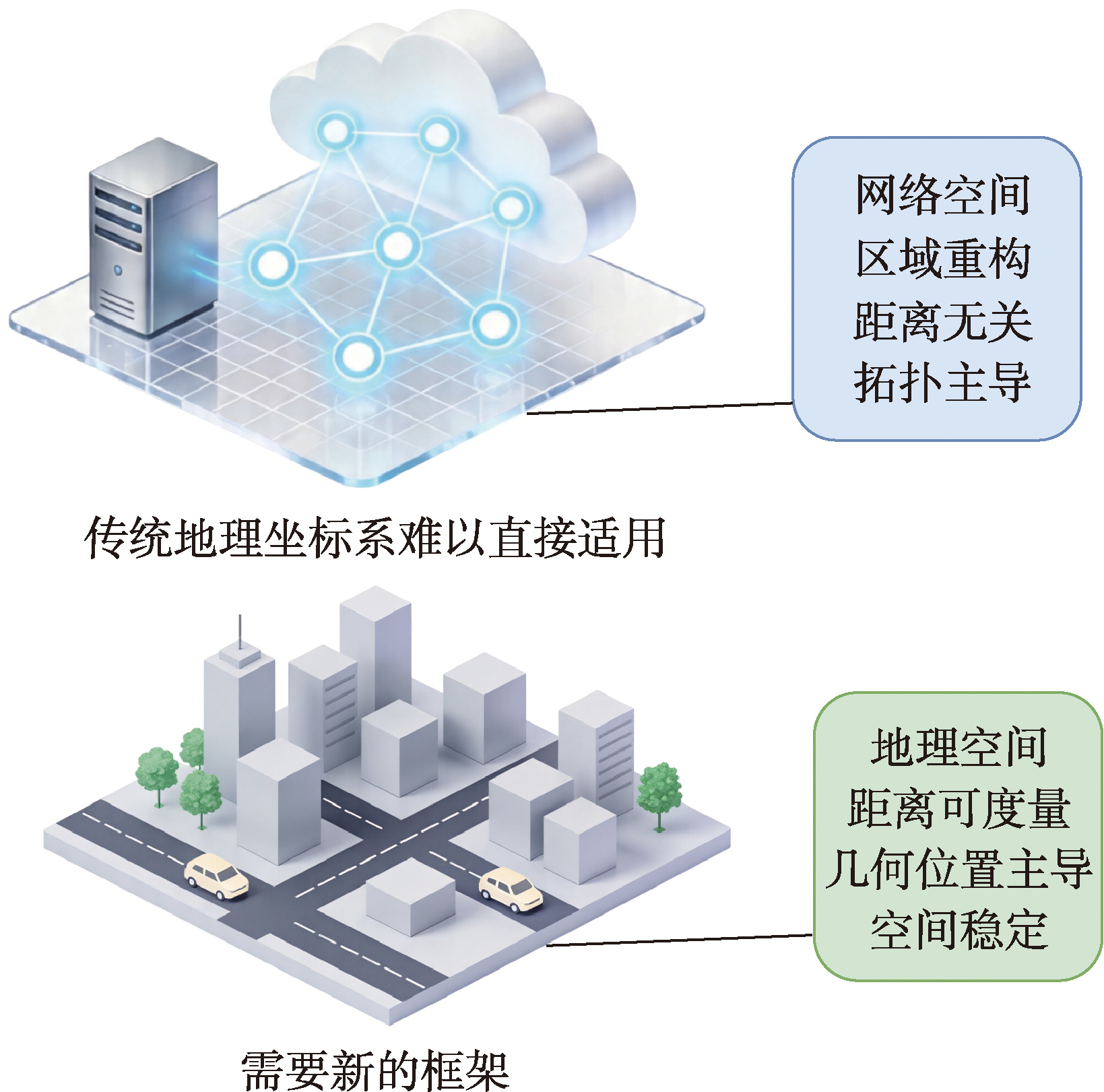
【目的】统一的坐标系是实现网络空间态势感知与精细化分析的基础,但网络空间作为虚拟、动态、非欧空间,其距离无关、拓扑主导等特性使得传统地理坐标系难以直接适用。 【方法】针对现有网络空间要素坐标系跨尺度联动缺失、宏观与微观分析衔接断裂,且微观层面未深入到协议维度、仅停留在端口分析的问题,提出了一种跨尺度网络空间要素坐标建模(Cross-scale Network Space Element Coordinate Modeling,CNSEC-M)框架。该框架借鉴TCP/IP协议栈的分层机制构建标准化基向量库,并通过叠维机制实现坐标系的按需动态实例化,具备统一性、可扩展性与跨尺度联动能力。 【结果】实验基于CTU-13真实攻击数据集中的场景三,该场景涵盖43.5万余个IP地址的真实网络流量。结果表明,CNSEC-M有效支撑了从宏观网络威胁态势感知到微观网络威胁行为溯源的完整分析闭环:在宏观层面,模型精准定位了恶意自治系统AS2852,并识别出其内部利用6667端口部署的混合(Command and Control,C&C)服务;在微观层面,成功溯源至僵尸主机IP与C&C服务器IP,并解析出针对SSH服务的端口扫描行为及TCP SYN Flood攻击模式。此外,性能测试显示模型核心映射算法处理速度达到约 2.3×105IP/s,验证了该框架在大规模网络空间要素映射中的高效性与实用性。
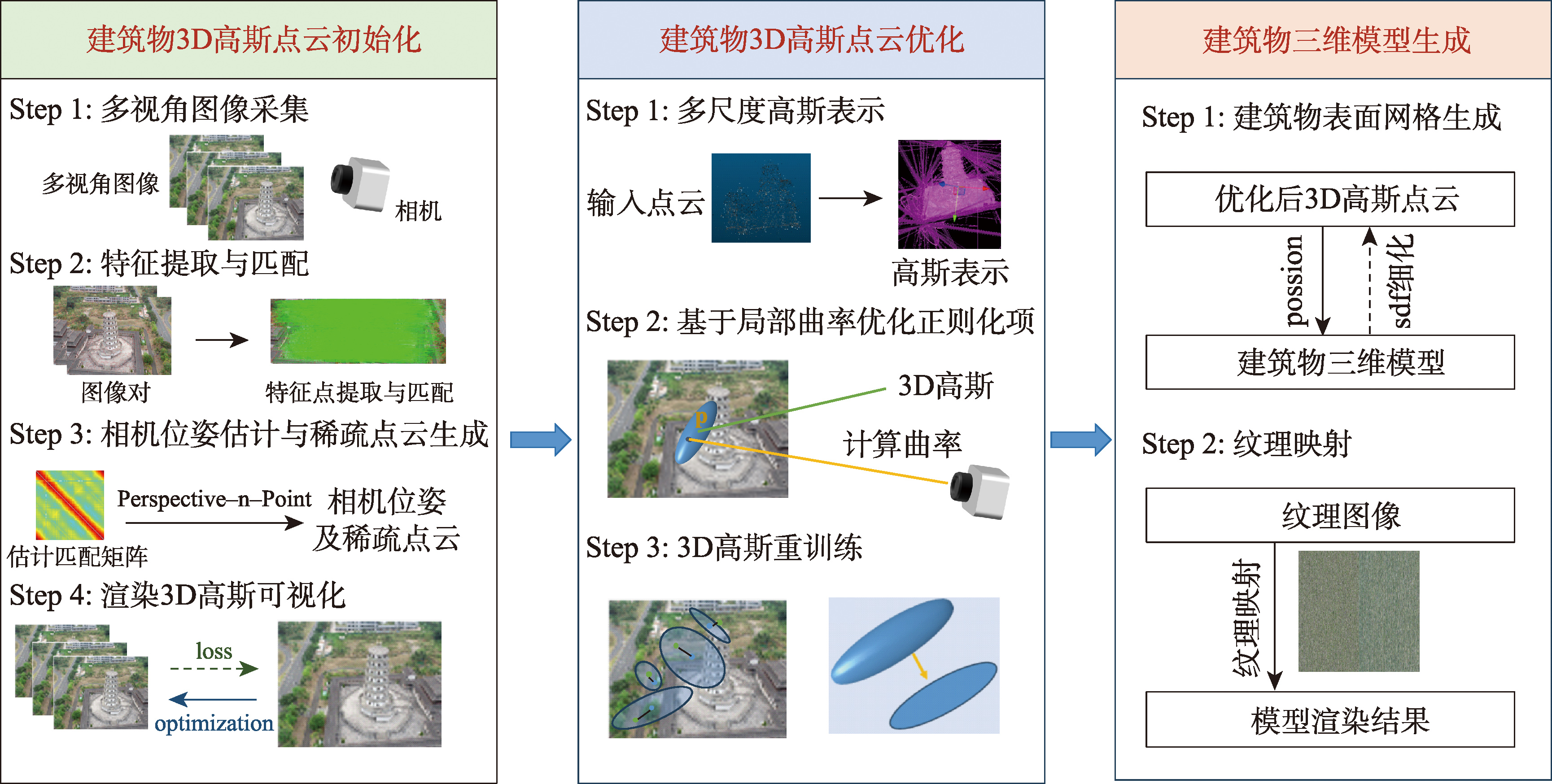
【目的】基于多视角图像的建筑物三维重建技术在城市规划和灾害模拟等领域具有广泛的应用价值。然而,现有方法在视觉效果优化的同时,往往难以兼顾几何精度、细节还原能力以及对复杂场景的适应性。针对复杂场景下建筑物高精度三维重建的挑战,本文提出了一种基于3D高斯溅射(3D Gaussian Splatting,3DGS)引导的多视图建筑物三维重建方法,旨在较好地捕捉建筑物的几何结构与细节特征,生成兼具高几何精度和高细节还原度的三维模型。 【方法】该方法的核心流程分为3个阶段:首先,通过运动恢复结构(Structure from Motion,SfM)从多视角图像数据集中生成建筑物场景稀疏点云,再利用3D高斯溅射技术进行点云平滑和补全,生成连续的3D高斯建筑点云;其次,针对复杂建筑表面设计了3D高斯建筑点云优化策略,通过多尺度高斯表示,并基于局部曲率优化的正则化项,使3D高斯建筑点云更精确地贴合建筑物表面,提升模型的平滑度和视觉一致性;最后,采用Poisson重建从优化后的3D高斯建筑点云生成建筑物初始网格,并结合有符号距离场(Signed Distance Field,SDF)细化表面结构,进一步提高几何精度和细节保真度。基于本文提出的方法,在Tanks and Temples数据集中的Barn场景、ArcGIS公司提供的Small Buildings数据集和自采集的Tower数据集上开展实验,并与Colmap、Neuralangelo和SuGaR等方法进行比较。 【结果】在几何精度方面,本文方法在Barn数据集上的F1分数(F1 Score)达到0.46,点到网格距离(Point-to-Mesh Distance)为0.049,均优于对比方法;在渲染质量方面,峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似性(Structural Similarity Index,SSIM)指标在Barn数据集上分别为27.83和0.92,在Small Buildings数据集上分别为29.67和0.94,在Tower数据集上分别达到32.69和0.96,均优于对比方法。 【结论】本文方法在复杂场景下的建筑三维重建的几何准确性、细节保留能力和渲染质量方面较对比方法有较好提升,能够有效地恢复建筑物整体几何结构,并实现稳定的渲染性能。
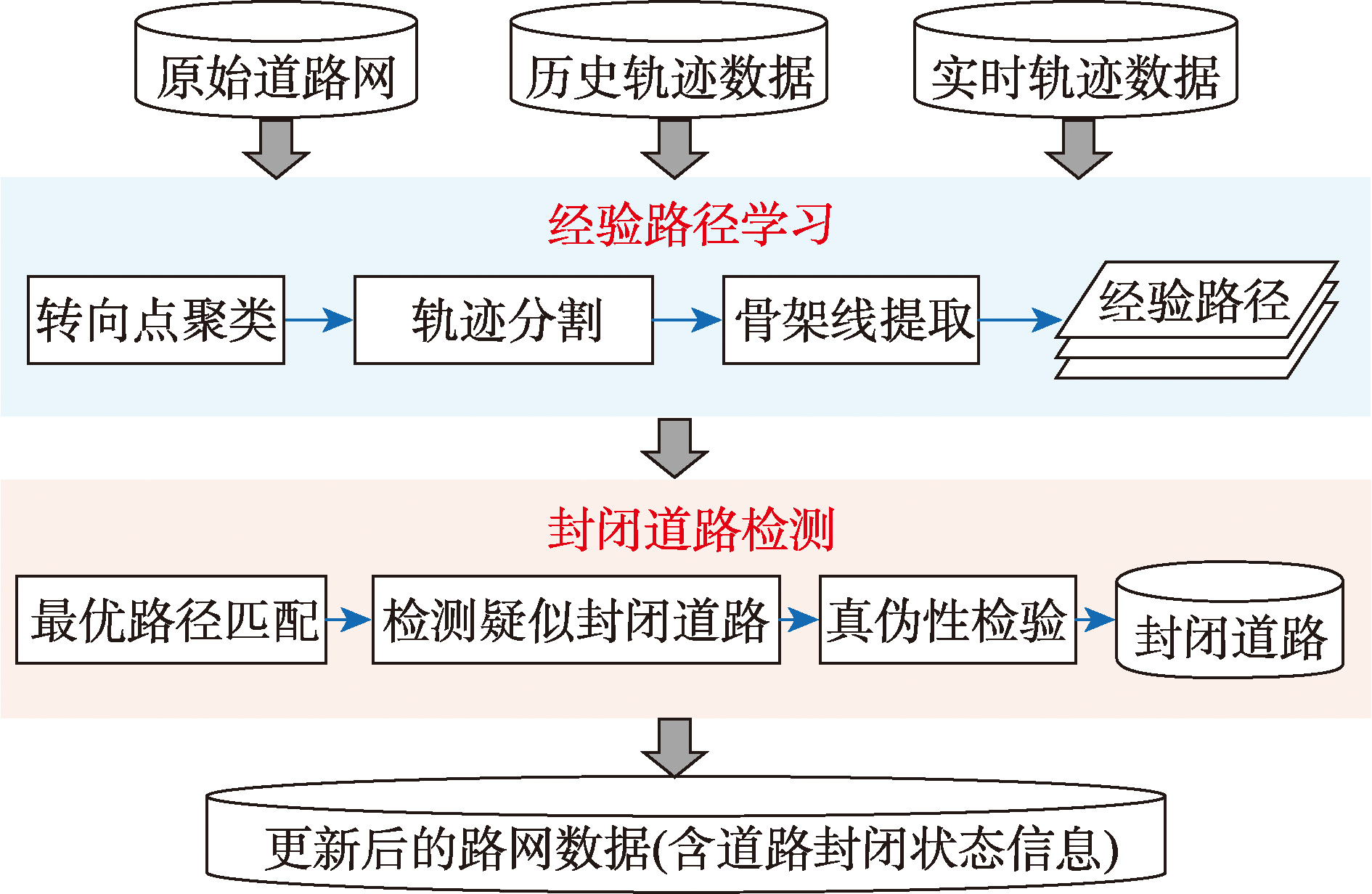
【目的】封闭道路的快速精准识别是保障导航地图信息时效性与路径规划可靠性的关键。然而,目前基于交通流量的传统阈值法与基于统计模型的方法在识别低流量封闭道路时存在漏检率高、检测滞后以及动态适应性不足等问题,难以满足大规模城市路网信息实时更新的需求。 【方法】本文提出一种基于在线车辆轨迹数据的封闭道路快速识别方法。该方法首先从历史车辆轨迹数据中挖掘常态化的出行路径规律,构建区域内车辆通行的经验候选路径,进而结合实时车辆轨迹数据识别异常行驶行为(如掉头、绕道)来识别疑似封闭道路,最后通过多轨迹匹配策略检验和判定真实封闭道路或路段。 【结果】基于武汉市2014年出租车轨迹数据构建的模拟封闭道路实验结果表明,相比目前经典的基于车流量阈值的方法、基于车流量泊松统计模型的方法和基于路网拓扑建模的方法(T-closure),本文方法在封闭道路检测精度和实时性方面表现更优,准确率、召回率和F1得分提升约10%,同时在低流量及数据覆盖不足的情况下具有较好的适应能力与鲁棒性。 【结论】本方法可为城市导航路网更新和智能交通系统服务提供实时的封闭道路信息。
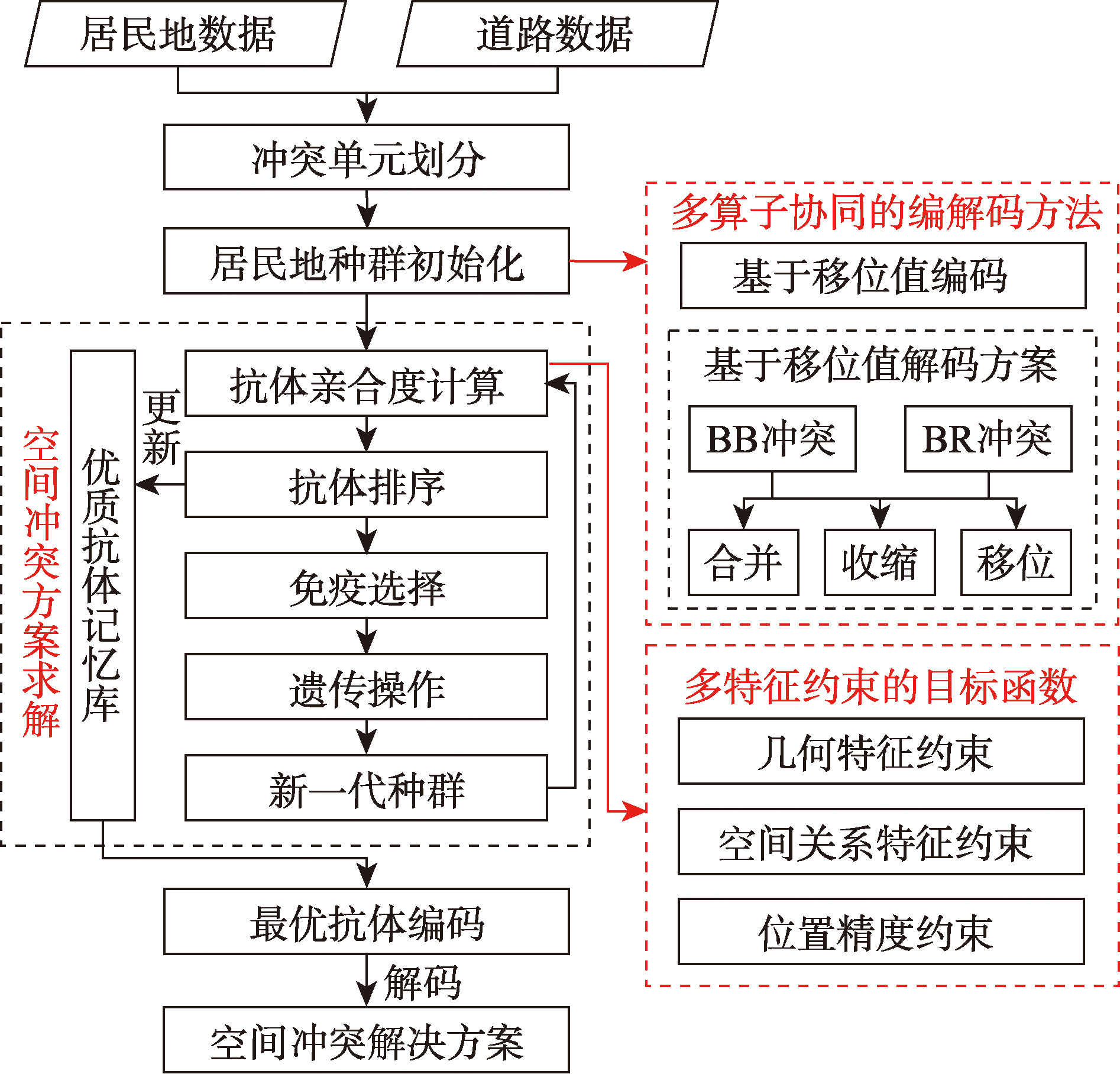
【目的】空间冲突检测与处理作为增量更新中更新信息数据入库的关键环节,是保障地理空间数据质量和可用性的重要前提。增量更新中由尺度差异引发的空间冲突主要表现为拓扑冲突与邻近冲突,需要移位、合并、化简等多种综合算子进行协同消解。现有方法多聚焦于移位单算子的最优方案生成,或者根据预设规则使用多种综合算子进行冲突消解,前者忽视了多算子协同的使用问题,后者难以解决复杂的次生冲突。 【方法】本文提出了一种基于免疫遗传算法的多算子协同空间冲突处理方法。以多特征约束函数作为优化目标,设计了一种融合移位、收缩、合并算子协同的抗体编解码方案,利用免疫遗传算法作为启发式求最优解框架生成最优空间冲突解决方案。 【结果】在浙江省某区域1:5万居民地和道路数据上与现有方法进行对比实验。定量分析结果表明,相较于仅使用移位算子或串行协同的多算子空间冲突处理方法,本文所提出的方法不仅可以将原始冲突个数和冲突严重程度都降低为0,且在空间特征和面积特征变化2个指标上都保持0.95以上的高相似度。定性分析结果表明,该方法可以生成更为合理的顾及多特征的空间冲突解决方案,能够有效解决居民地同要素之间以及与居民地与道路之间的冲突,且适用于不同密度区域、不同道路分布的多场景复杂冲突处理。 【结论】该方法通过多算子协同框架与免疫遗传算法的深度融合,突破了传统单一算子优化或局部规则迭代的局限,实现了冲突消解完整性与地理要素保真度的协同提升,为多尺度居民地增量更新中的空间冲突处理提供了高效可行的技术方案。
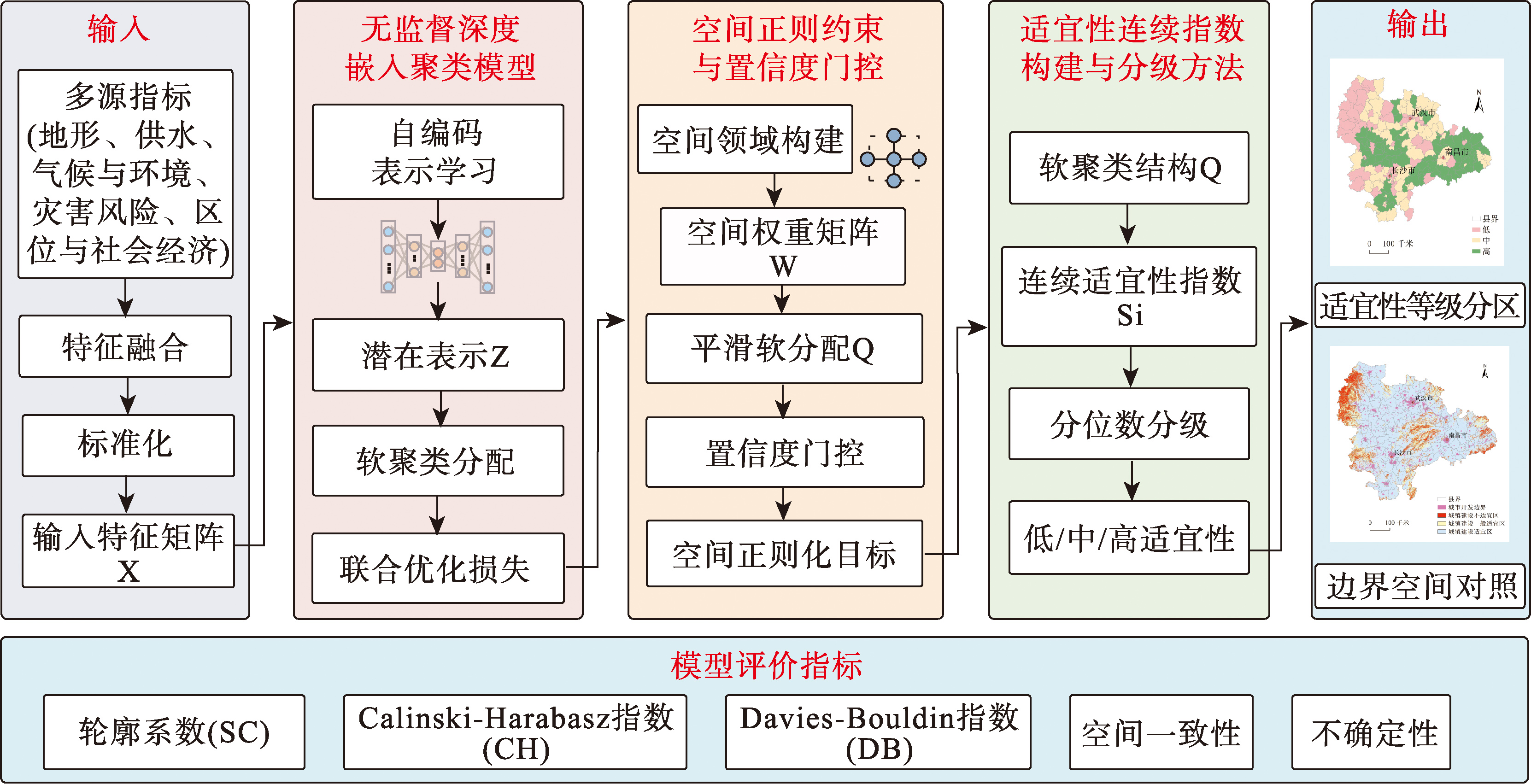
【目的】城镇建设适宜性评价是国土空间规划与城镇发展管控的重要基础,传统方法多依赖指标赋权与规则判别,结果对专家经验和权重设定较为敏感,难以刻画多源指标之间复杂的非线性关系与空间异质性特征。针对多源空间数据快速积累背景下适宜性分区主观性强、空间连续性不足等问题,本文旨在构建一种能够减少人为干预并兼顾空间连续性与规划语义表达的无监督适宜性分区方法。 【方法】提出一种融合空间正则的城镇建设适宜性无监督深度聚类方法(SR-IDEC)。该方法以深度嵌入聚类为核心,通过自编码网络学习多源适宜性指标的低维潜在表示,实现空间单元的无监督分区;在聚类优化过程中引入基于空间邻近关系的正则约束,并结合聚类置信度门控机制自适应调节空间约束强度,以增强空间一致性并避免边界过度平滑;进一步将软聚类结果映射为连续适宜性指数,实现分区结果的量化表达。以长江中游城市群为研究区,选取K-Means、高斯混合模型(GMM)、层次聚类和谱聚类方法作为对比模型,采用轮廓系数(SC)、Calinski-Harabasz指数(CH)和Davies-Bouldin指数(DB)对模型性能进行验证。 【结果】SR-IDEC在聚类结构质量指标上均表现出明显优势,其轮廓系数为0.860,较K-Means(0.651)、GMM(0.696)、层次聚类(0.701)和谱聚类(0.692)分别提高约32.1%、23.6%、22.7%和24.3%;Calinski-Harabasz指数达到357.9,较K-Means(180.5)提高约98.3%;Davies-Bouldin指数为0.217,较K-Means(0.621)降低约65.1%。同时,SR-IDEC生成的适宜性分区在空间上呈现出更高的连续性与更清晰的边界结构,有效减少了局部碎片化现象。 【结论】本文所提出的 SR-IDEC方法能够在无监督条件下有效刻画多源适宜性指标的非线性结构关系,在提升聚类结构质量的同时显著增强空间连续性与分区稳定性,可为城镇建设适宜性分区提供一种具有空间合理性与规划语义支撑的数据驱动方法参考。
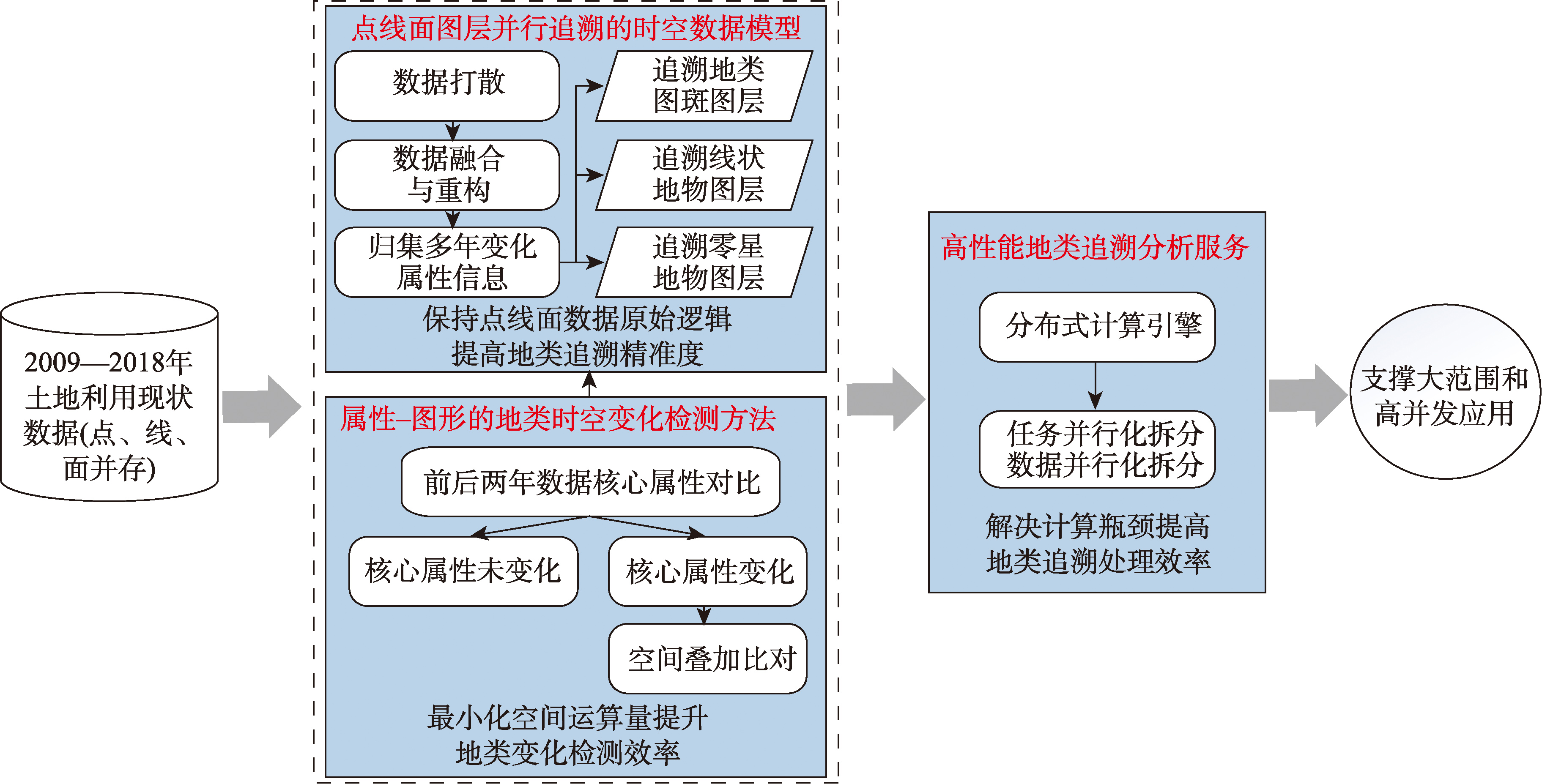
【目的】面向建设用地审批中的建设用地历史地类追溯需求,解决全国海量点线面数据并存下的地类高效、精准追溯难题。 【方法】基于点线面图层并存的2009—2018年全国土地利用调查数据,提出一种适应海量、长时序、高并发应用的地类高效追溯方法:首先,构建点线面图层并行追溯的时空数据模型,保留地类图斑、线状地物、零星地物的原始图形特征和面积计算逻辑,确保地类追溯精准性;其次,建立属性-图形的地类时空变化检测方法,依据属性优先识别未变化图斑,减少冗余空间叠加运算和碎图斑,提高地类变化检测效率;最后,构建基于分布式计算引擎的地类追溯分析服务,实现全国尺度海量数据、高并发应用下的地类追溯高性能计算。 【结果】通过覆盖多个省份的10个线状、面状复杂建设工程项目实例验证,结果表明:本方法地类追溯的结果准确、可靠,涉及跨市级的项目地类追溯计算效率较人工全量构面法从48 h缩短至0.5 h、提升95倍,精度方面追溯前后地类总面积差异率低于万分之零点三、远优于业务精度要求。 【结论】方法在效率、精确度和规模化应用能力上优势显著,可为建设用地审批地类认定提供可靠技术支撑,属-图变化检测策略也可为其他领域的时空大数据长时序变化检测提供借鉴。
【目的】随着地理信息科学向人工智能驱动的新阶段迈进,地图形态与功能日益泛化,用户对地图的认知需求也从“看见信息”转向“高效理解”。传统地图认知负荷评估方法存在主观性、静态性以及只注重结果没有关注过程,不能满足实时评估需求,无法为动态调整提供依据,缺少定量化分析等局限。 【方法】本文融合眼动追踪技术与机器学习,构建了不同地图定位任务下的认知负荷评估模型,流程涵盖数据采集、数据处理与模型构建3个阶段。通过组间实验采集30名受试者在2D、3D、卫星影像地图中的眼动数据,经清洗分窗后,结合Kruskal-Wallis检验与随机森林特征重要性完成两轮特征筛选;最终构建逻辑回归、随机森林、支持向量机、长短期记忆网络与卷积神经网络5种分类模型,对比分析各模型的认知负荷分类性能,验证方法的有效性。 【结果】眼动实验结果表明,不同地图的认知负荷存在显著差异:影像地图的认知负荷最高,三维地图次之,二维地图最低;同时,性别间认知负荷水平存在差异,男性受试者的认知负荷高于女性。本研究提取的绝大多数眼动特征在不同认知负荷水平间均呈现出统计学显著性差异,验证了所提出的特征构建方法对于地图定位认知负荷评估的有效性。10折交叉验证结果显示,随机森林模型在5种对比模型中取得最优分类性能,平均准确率0.743±0.029, AUC值为0.874 8;经Friedman检验证实,该模型性能显著优于其他模型(p<0.001),充分验证了基于眼动数据的机器学习方法在地图定位认知负荷量化评估中的可行性与有效性。 【结论】本研究提出的融合眼动追踪技术与机器学习的地图定位认知负荷评估方法,可有效量化地图使用过程中的认知负荷水平;其中随机森林模型在特征判别能力与分类稳定性上表现最优,为构建自适应地图系统以及人机交互与导航辅助、个性化地理信息服务、虚拟现实/增强现实地理环境的体验优化等应用提供了重要的方法支持与实证依据。
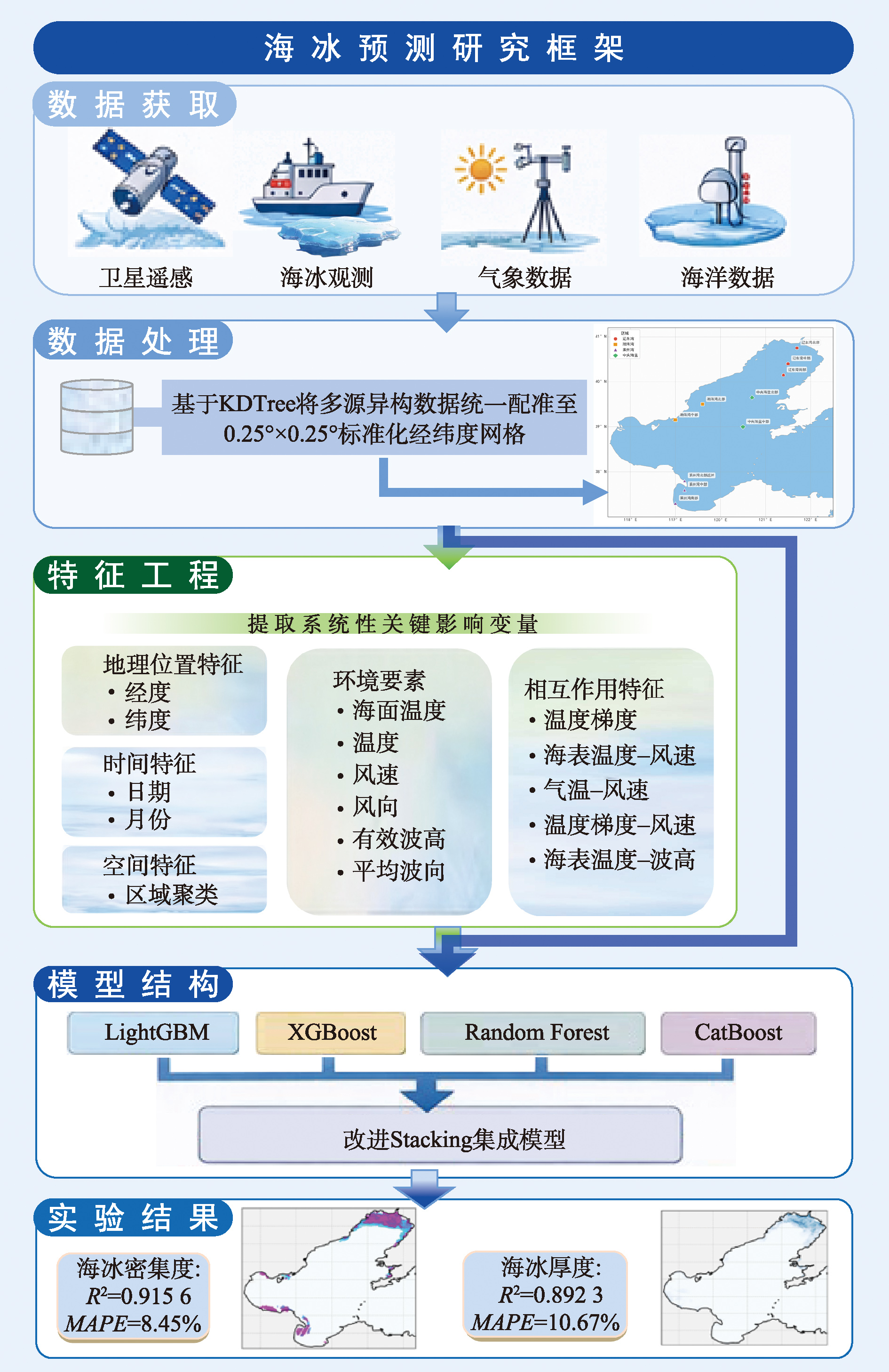
【目的】海冰是海洋环境中的重要自然现象之一,在全球海域广泛分布,其形成对海洋生态、航运、能源开发等活动具有重要影响。海冰预测对于防灾减灾措施制定和风险评估具有重要意义。 【方法】针对海冰环境监测数据来源多样、时空分辨率差异显著的特点,本文建立了涵盖海冰密集度、海冰厚度、大气海洋环境要素等多维度信息的多源异构数据库。采用基于KDTree空间索引优化的k近邻反距离加权插值算法,将多源异构数据统一配准至0.25°×0.25°标准化经纬度网格,实现数据的时空一致性处理。通过系统化特征工程方法提取海冰演变的关键影响因子,包括时空特征、气象特征、海洋动力学特征等多维度变量。针对海冰系统的复杂非线性特征,结合LightGBM、XGBoost、Random Forest、CatBoost多种机器学习算法,构建融合原始特征的改进Stacking集成预测模型,实现海冰厚度与密集度的精准预测。 【结果】将上述方法应用于2021/2022年和2022/2023年冬季渤海海域,实验结果表明,改进Stacking集成模型在海冰密集度预测中R²达0.915 6,MAPE为8.45%;在海冰厚度预测中R²达0.892 3,MAPE为10.67%,显著优于传统单一模型和固定权重的投票集成方法。与最优单一模型LightGBM相比,海冰密集度预测R²提升24.32%,RMSE降低约89.79%;海冰厚度预测R²提升19.70%,RMSE降低约71.80%。 【结论】本研究构建的海冰预测框架突破了传统数值模拟和单一机器学习模型的局限性,为海洋环境智能监测和气候变化预警提供了理论基础和技术支撑。
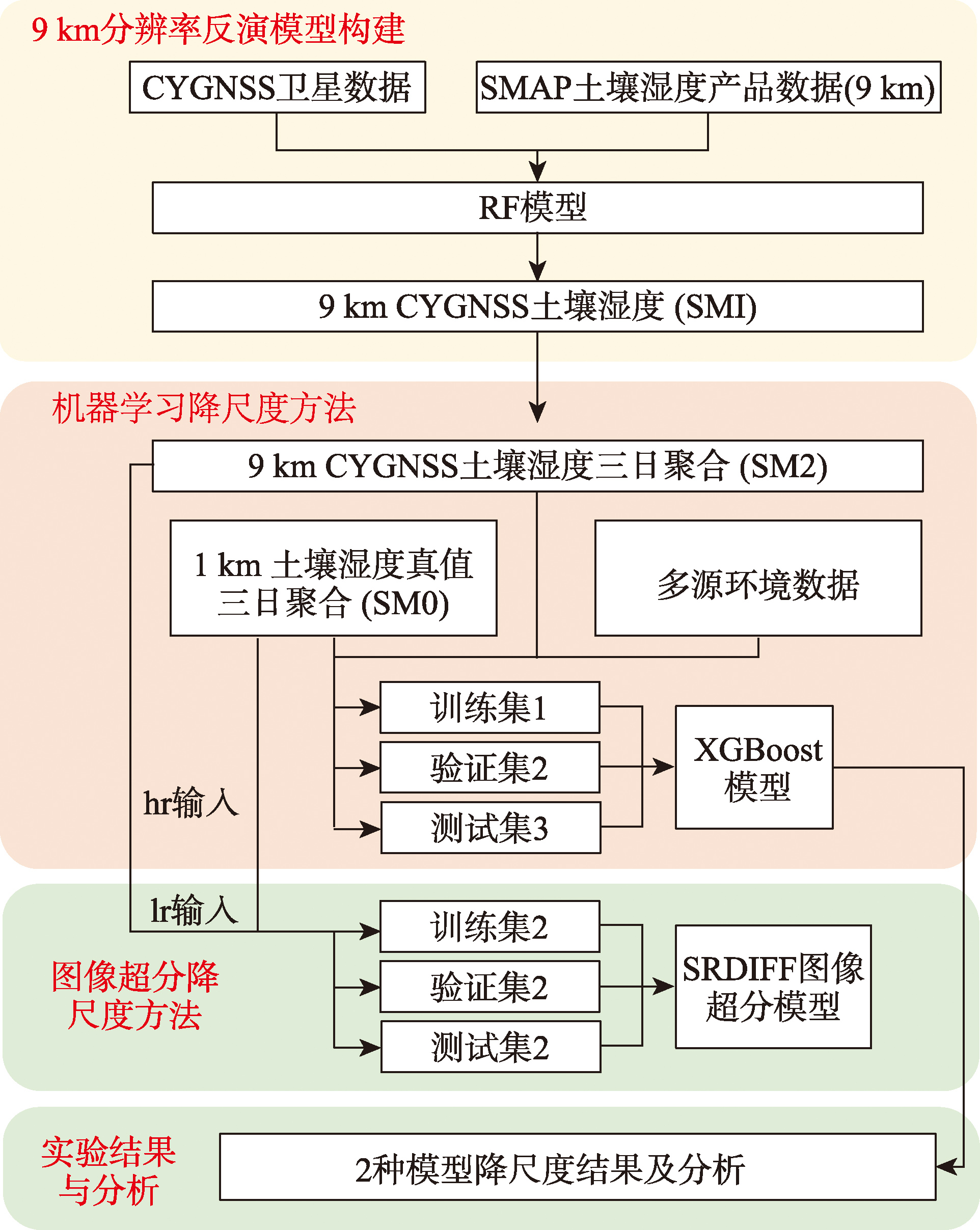
【目的】高分辨率土壤湿度数据是精细化农业灌溉调度、干旱灾害监测及生态环境评估等气象业务服务的核心支撑数据,对提升区域尺度水文与气象过程研究精度具有重要意义。针对当前星载 GNSSR 土壤湿度反演主流分辨率集中在9~36 km,难以满足精细化应用需求的问题,开展高分辨率土壤湿度反演与降尺度研究。 【方法】以2022年和2023年CYGNSS卫星观测数据为基础,融合多源环境与地形因子,采用随机森林模型实现9 km分辨率土壤湿度反演;在此基础上,分别利用机器学习与图像超分2种降尺度方法,生成1 km分辨率土壤湿度数据。 【结果】与中国1 km分辨率逐日全天候地表土壤水分数据对比,XGBoost模型生成的1 km土壤湿度均方根误差为0.063 9 cm³/cm³,SRDIFF模型降尺度结果的均方根误差为0.071 3 cm³/cm³。 【结论】本文提出的先反演再降尺度框架,既可结合原始卫星数据与环境辅助数据产出优质高分辨率土壤湿度产品,又能在环境辅助数据缺失时,通过SRDIFF图像超分模型迁移应用生成高分辨率土壤湿度产品,对GNSSR高分辨率数据产品研制及区域精细观测与管理具有重要参考意义。
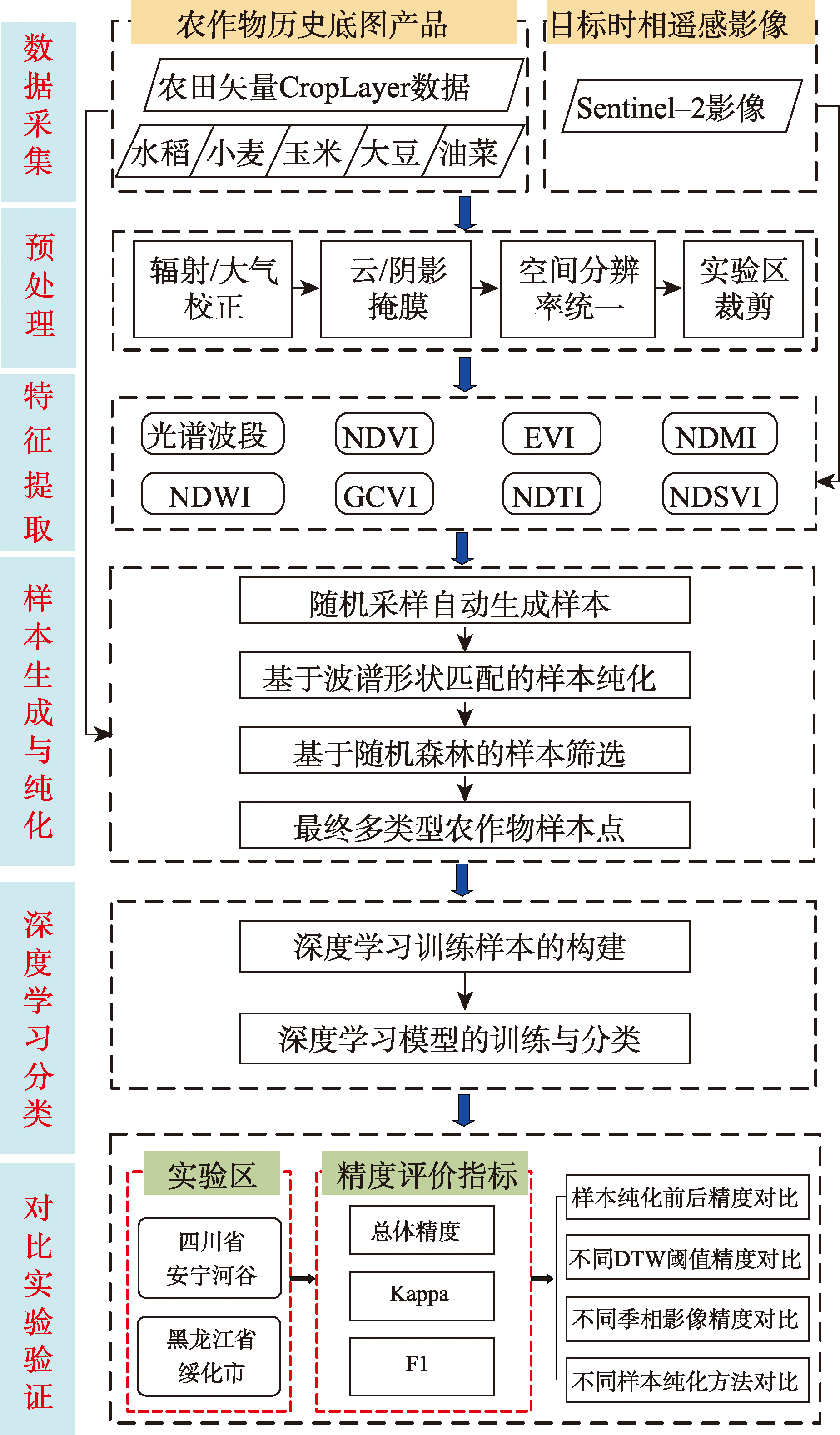
【目的】随着高分辨率遥感与智能算法的发展,农作物精细分类已成为提升现代农业管理的关键环节。 【方法】针对农作物精细分类中样本获取困难的问题,本研究以历史农田矢量数据与多源农作物栅格数据为基础,以Sentinel-2多季相影像为目标时相影像,提出一种基于波谱形状匹配与随机森林的样本纯化方法,用于目标时相影像的农作物分类。该方法首先基于历史农作物底图产品自动生成初始样本点,进而通过综合评估初始样本点的光谱聚集度以及对目标时相分类任务的置信度,对初始样本点进行筛选优化,最终得到多类型农作物纯化样本点。在波谱形状匹配的样本纯化阶段,通过DTW算法量化初始样本点光谱曲线与均值光谱之间的相似度,筛选出光谱特征集中且具有代表性的样本点;在随机森林样本筛选阶段,采用随机森林分类器评估样本点的分类置信度。 【结果】以四川省安宁河谷复杂农作物种植区和黑龙江省绥化市大田种植区为实验区开展实验,结果表明与采用初始样本点相比,样本纯化后2个实验区农作物分类总体精度分别提升14.18%与22.78%;DTW相似度阈值为60%,全生长季合成影像的农作物分类效果最优,与秋季合成影像相比总体精度提升22.83%;与现有3种样本纯化方法相比,本文方法在2个实验区的农作物分类总体精度分别为90.16%与93.16%,在复杂农作物种植区明显优于对比方法,表明本文方法在处理不同场景的农作物精细分类中具有鲁棒性。 【结论】本研究为利用现有农作物底图产品进行农作物精细分类提供了一种技术手段。
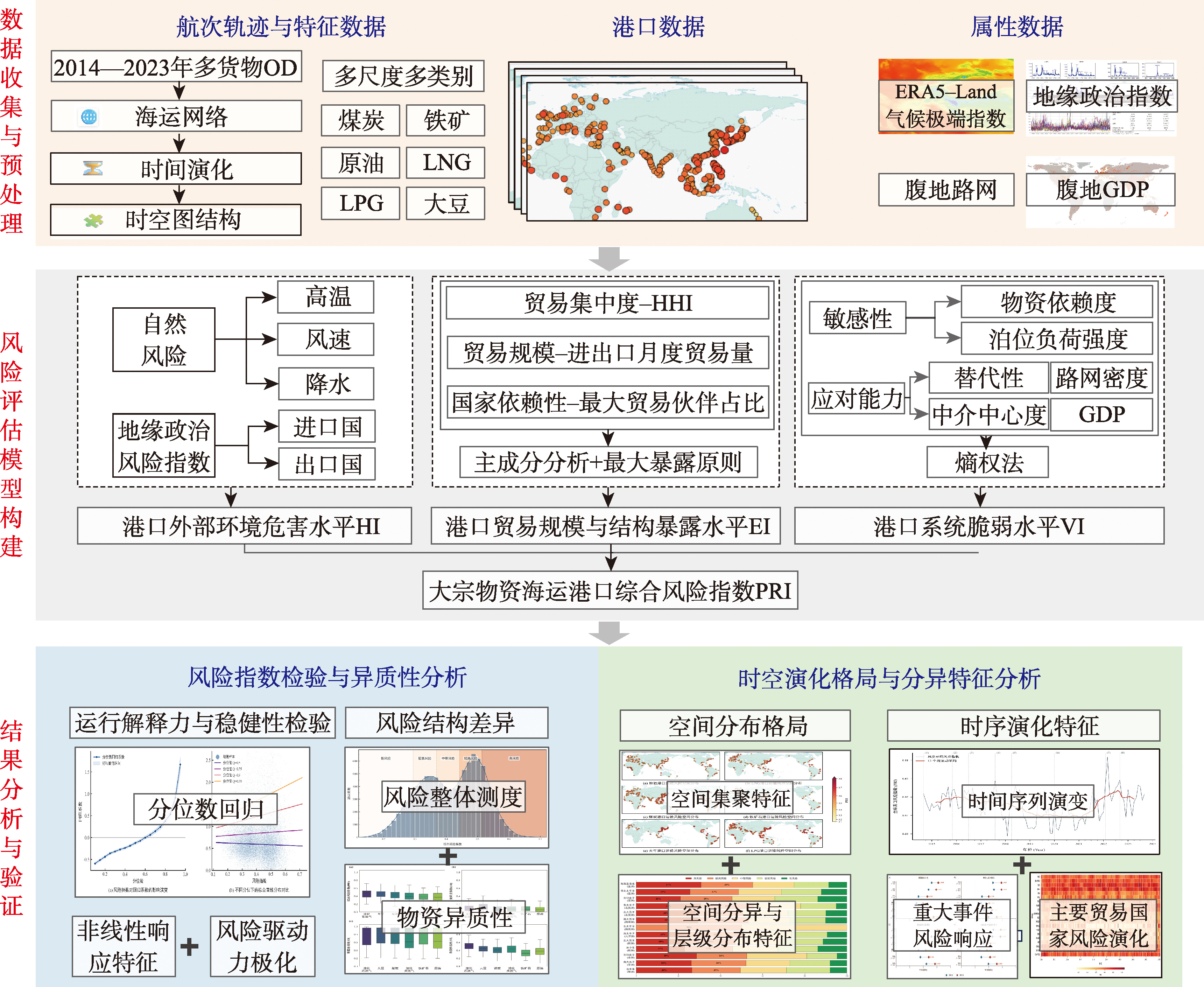
【目的】大宗物资全球海运贸易高度依赖港口节点的稳定性。在全球地缘冲突与极端气候频发的背景下,系统评估全球关键大宗物资运输港口的复合风险格局,识别高脆弱性节点与时空演化规律,对保障国家能源安全、提升供应链韧性具有重要现实意义。 【方法】基于IPCC灾害风险理论框架构建适用于海运体系的港口风险时空评估模型,极端气象与地缘冲突等外生冲击刻画为危险源,枢纽地位与贸易规模表征暴露度,腹地经济水平与基础设施条件反映脆弱性。基于2014—2023年全球主要港口的航次轨迹数据,融合气候与地缘政治等多源风险因子,构建涵盖煤炭、原油、铁矿石、液化天然气(LNG)、液化石油气(LPG)、大豆6类大宗物资的多维面板数据集。在此基础上,采用主成分分析与熵权法进行客观赋权,并结合空间自相关分析、STL时间序列分解和分位数回归方法,对港口风险指数的有效性、异质性及时空演化特征进行系统分析。 【结果】研究表明: ① 港口风险指数对运输失稳具有显著解释力,在τ=0.95极端异常区间,风险对航行延误的放大效应约为中位数水平的13倍; ② 全球港口风险呈双峰分布,形成了稳定的中低与中高风险分层格局;风险构成中高暴露度与低频危险源的耦合是驱动中高风险聚集的主要机制,其中LNG、LPG等能源物资风险水平整体高于铁矿石等干散货; ③ 风险分布呈现显著空间正相关。高风险主要集中于东南亚、北印度洋及西北太平洋海域,东南亚海域高风险港口占比高达30.7%; ④ 港口风险呈长期稳定、阶段性下降、突发抬升的阶段性演化,2021年后受地缘事件驱动风险中枢发生趋势性上移;相较于贸易结构多元化国家,能源出口依赖型国家在风险演化过程中表现出更高的敏感性与更弱的缓冲能力。 【结论】本文构建的多尺度风险评估框架系统揭示了全球大宗物资港口海运风险形成机制与时空演化规律,并验证了风险指数对运输异常与系统脆弱性的解释能力,可为港口风险分级管控、关键节点识别及供应链安全治理提供重要参考。
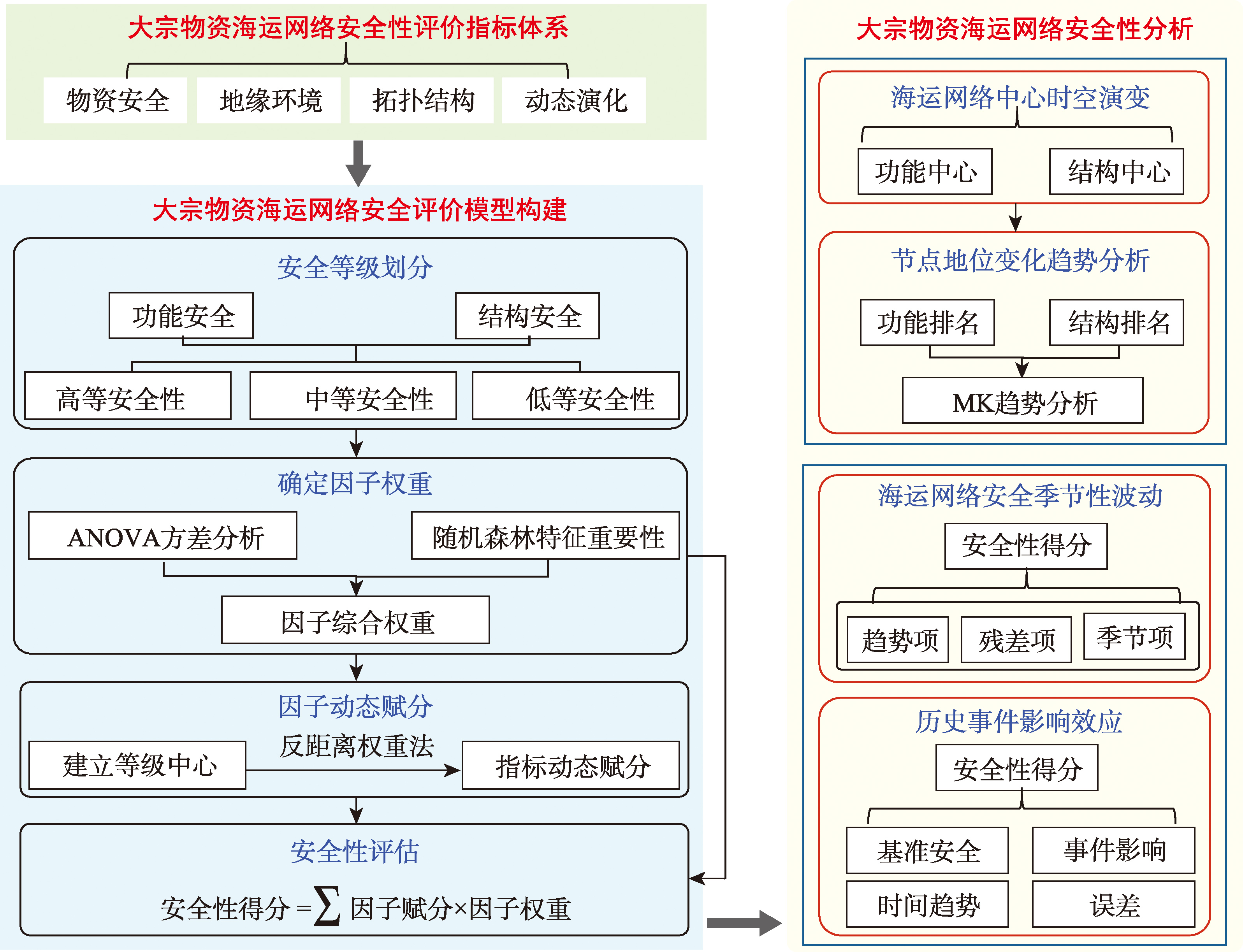
【目的】大宗物资海运网络作为连接各国经济命脉的关键纽带,其安全性关乎国家经济的稳定发展。现有研究涉及的海运网络物资类型单一、评价指标体系维度单薄、评价方法模型难以适应复杂环境下的动态安全评估需求。 【方法】本文使用AIS船舶轨迹大数据和复杂网络理论,以2014—2023年煤炭、原油、铁矿石、液化天然气(LNG)、液化石油气(LPG)、粮食6类大宗物资海运网络作为研究对象,构建了多维多层级大宗物资海运网络安全性评价指标体系,提出了基于方差分析统计显著性结合随机森林模型量化特征重要性的组合权重与反距离中心聚合的大宗物资海运网络安全性动态评价模型;开展了多视角多尺度的大宗物资海运网络演变规律分析。 【结果】① 亚洲国家长期主导功能中心,而结构枢纽节点更替频繁。贸易重心向资源生产国和亚太消费市场加速转移; ② 2014—2023年煤炭(月均提升0.005 1)、原油(月均提升0.005 9)、LNG(月均提升0.005 4)、LPG(月均提升0.007 1)及粮食(月均提升0.003 1)海运网络安全性呈上升趋势,铁矿石海运网络安全性先升后降; ③ 9月(煤炭、原油)、2月(LNG、LPG、粮食)为大宗物资海运网络风险高发期,4月是铁矿石、液化石油气和粮食海运网络安全性的共同优势月份; ④ 俄乌冲突、英国脱欧以及COVID-19的流行对大宗物资海运网络安全性整体呈负面冲击但网络在部分维度展现出适应性弹性。 【结论】本研究表明近10年来全球大宗物资海运网络安全性明显提高但维度不均且存在风险期,研究可为大宗物资海运安全决策与布局优化提供依据。
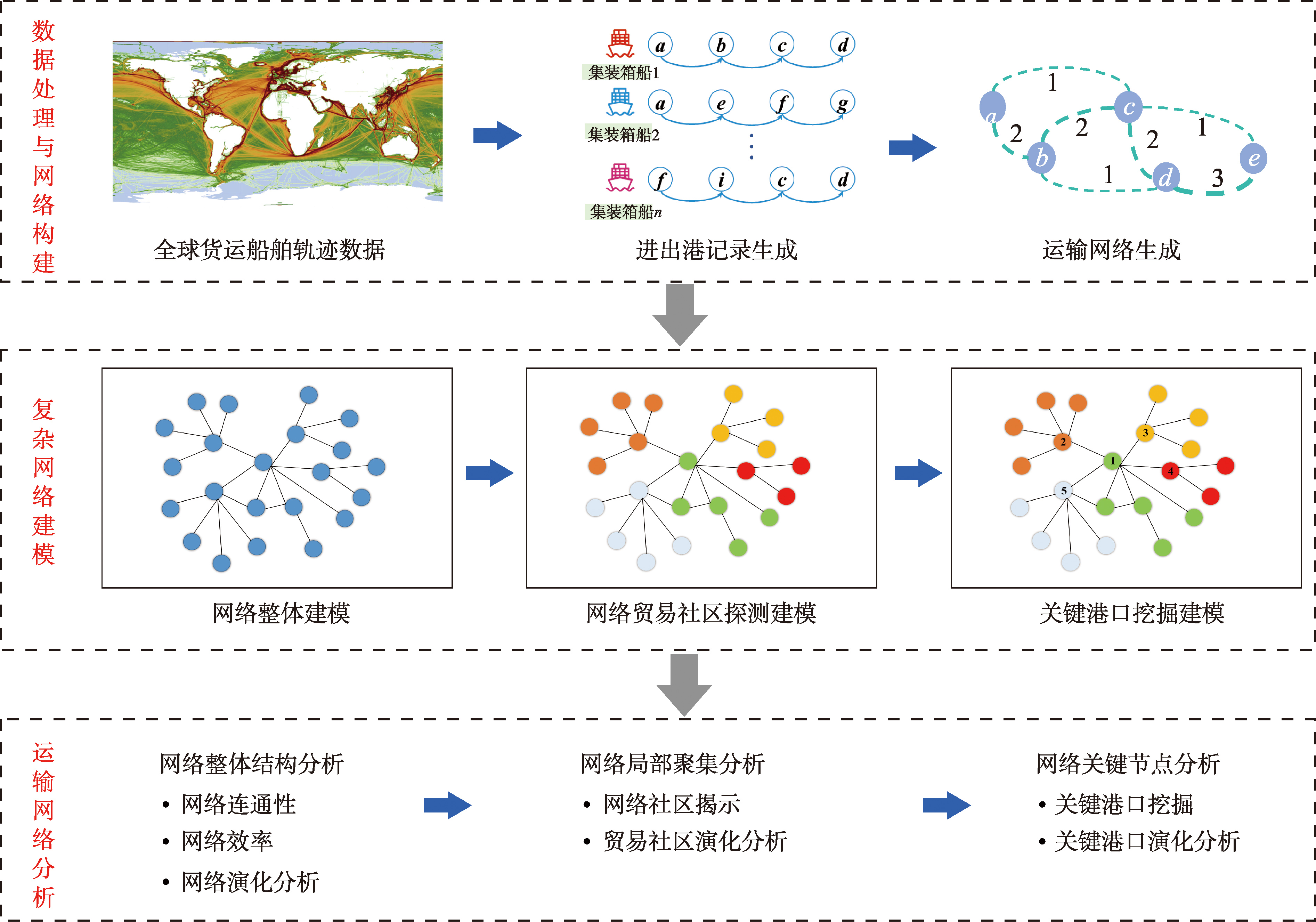
【目的】中国作为全球最大的集装箱运输国和关键贸易参与方,在全球海运网络中占据着日益重要的地位。深入分析中国集装箱运输网络的结构特征与动态演化,不仅有助于把握国内物流格局的演变,也对理解全球贸易流动的时空状态具有重要意义。 【方法】基于此,本文构建了一套复杂地理网络分析框架,基于2013年与2023年全球集装箱船舶轨迹数据,分别从宏观整体结构、中观贸易社区和微观关键港口3个层面,系统构建并分析了近10年来中国集装箱海运网络的演变特征。 【结果】① 中国集装箱海运网络经历了从“广覆盖”向“核心聚焦”的战略转型,整体结构逐步向枢纽集约化、连通高效化方向发展; ② 网络在10年间始终保持5个贸易社区,但其核心港口、地理分布与社区规模呈现从区域集聚向空间分散的转变,反映出国际贸易流向与区域合作态势的动态调整; ③ 中国主要港口格局发生显著重构,青岛港在航线与航次规模上超越宁波-舟山港位列第一;粤港澳大湾区港口群内部分工日益明晰,而高雄港的国际中转地位因大陆港口竞争力提升而相对弱化。 【结论】本研究的重要价值在于,它能从海事大数据视角,深入揭示中国集装箱运输网络的结构演化、贸易聚集特征与港口发展态势,为理解行业动态提供关键依据。
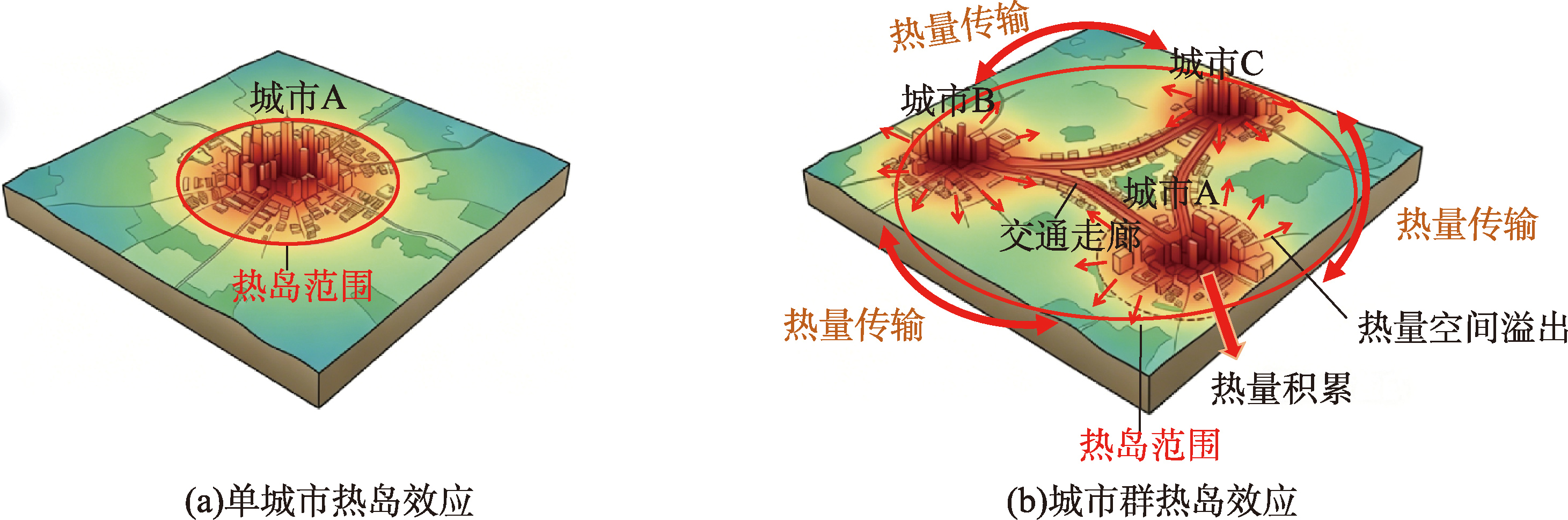
【意义】随着全球城市化进程的加速,城市群作为区域经济发展的核心载体,其热岛(Urban Heat Island,UHI)效应已成为影响生态环境可持续发展的关键问题。城市群尺度的热岛效应不仅呈现出空间分异,还体现跨城市的耦合与协同特征。系统认识城市群热岛效应的时空演变特征与形成机制,对于深化区域气候过程认知、优化热环境调控及支撑可持续发展具有重要意义。 【分析】本文梳理了中国8个典型城市群热岛效应的研究进展,重点分析其时空特征、形成机制、影响因素及调控措施,并展望未来研究方向。综合已有文献,在所选典型城市群研究中,城市群热岛效应在空间上普遍表现出明显的区域差异和等级分异特征,核心城市和周边城市之间存在梯度变化,并呈现出沿建成区扩展和功能轴带集聚发展的空间格局,在时间尺度上,城市群热岛效应具有复杂的昼夜变化与季节差异特征,自然因素与人为因素的相互作用主导了城市群热岛效应的演变过程。 【目的】本综述旨在系统整合中国典型城市群热岛效应的研究成果,揭示其时空特征与形成机制;在影响因素与调控策略的对比分析的基础上,为城市群热环境调控提供决策依据;并分析关键科学问题和发展趋势,识别研究不足与潜在突破方向,促进城市群尺度热环境协同治理研究的深化。
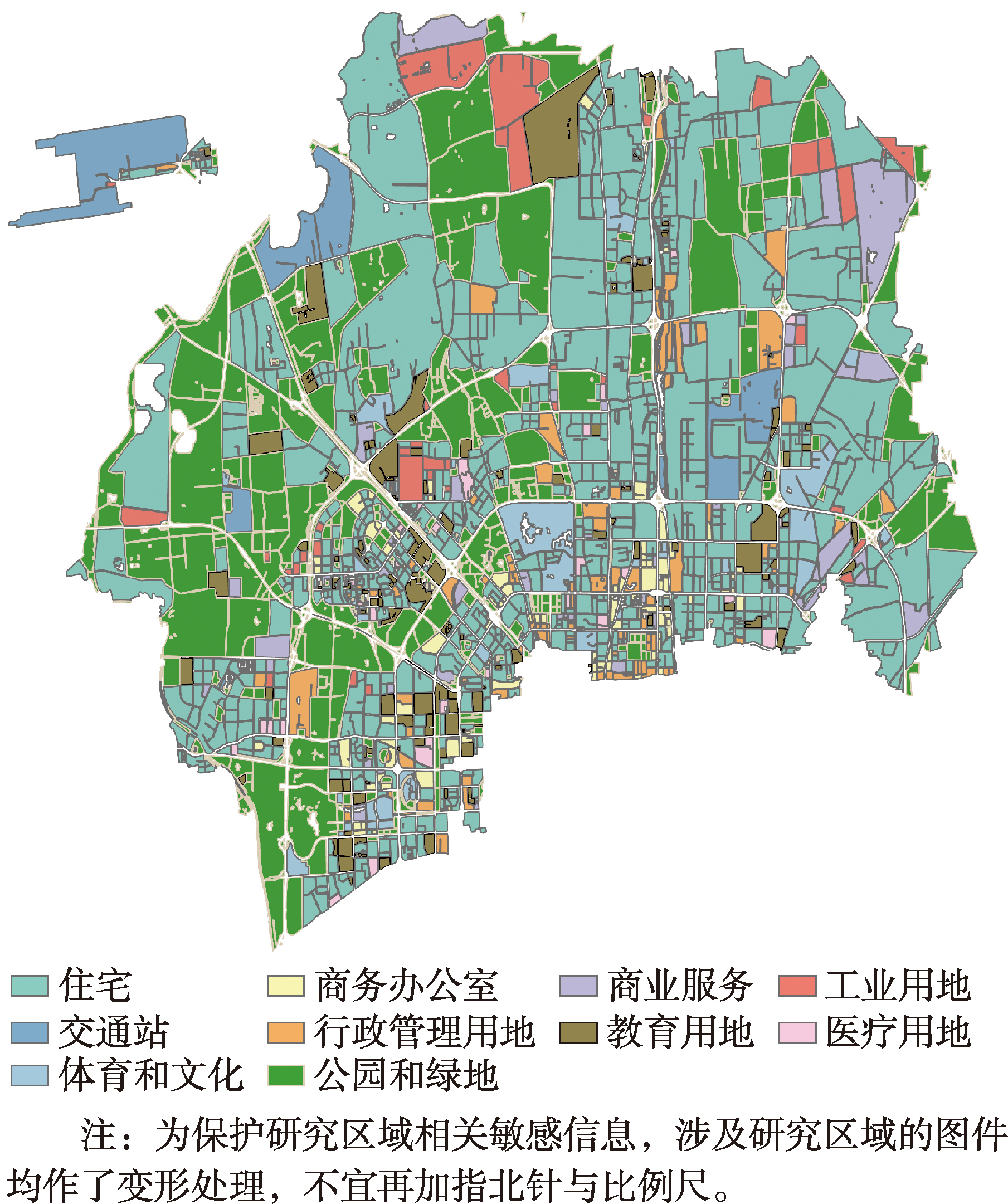
【目的】城市功能与街景特征共同塑造盗窃犯罪的时空格局。然而,现有研究多依赖单一数据源测度城市功能,且较 少将其空间溢出效应纳入分析。为此,本研究构建多维分析框架,探究城市功能与街景特征的交互作用对盗窃犯罪的影响。 【方法】本文以某市YC区为研究区域,融合2019年盗窃犯罪、POI、土地利用、街景及社会经济等数据开展分析。首先,融合土地利用与POI数据,构建互补的城市功能测度体系,识别影响盗窃犯罪的核心功能变量;其次,测算核心功能的空间溢出效应,构建涵盖城市功能溢出与街景特征的多维指标体系;最后,结合XGBoost模型与SHAP解释器,解析城市功能与街景特征的交互作用及其对盗窃犯罪的影响。 【结果】土地利用与POI数据在功能强度刻画上展现出显著互补性,前者适合表征大规模功能区,后者适合刻画小规模设施;商业服务设施(0.212)与功能混合度(0.485)及其空间滞后项(0.236、0.437)均显著促进盗窃犯罪,而工业用地则表现为本地抑制(-0.200)与邻域促进(0.104);城市功能对街景特征与盗窃犯罪关系具有明显的调节作用,空间溢出项的调节强度整体高于本地项,且两者的调节方式具有显著差异;商业服务溢出与功能混合溢出能够显著改变街景特征对盗窃犯罪的边际影响,且该交互作用在建筑视觉指数、街道峡谷围合度、绿色视觉指数、天空视觉指数以及路权指数等关键微观指标上表现尤为突出。 【结论】在研究街景特征与盗窃犯罪关系时,应重视城市功能及功能溢出对该关系的调节作用,避免因忽略周边功能影响而误判街景特征对盗窃犯罪的作用。
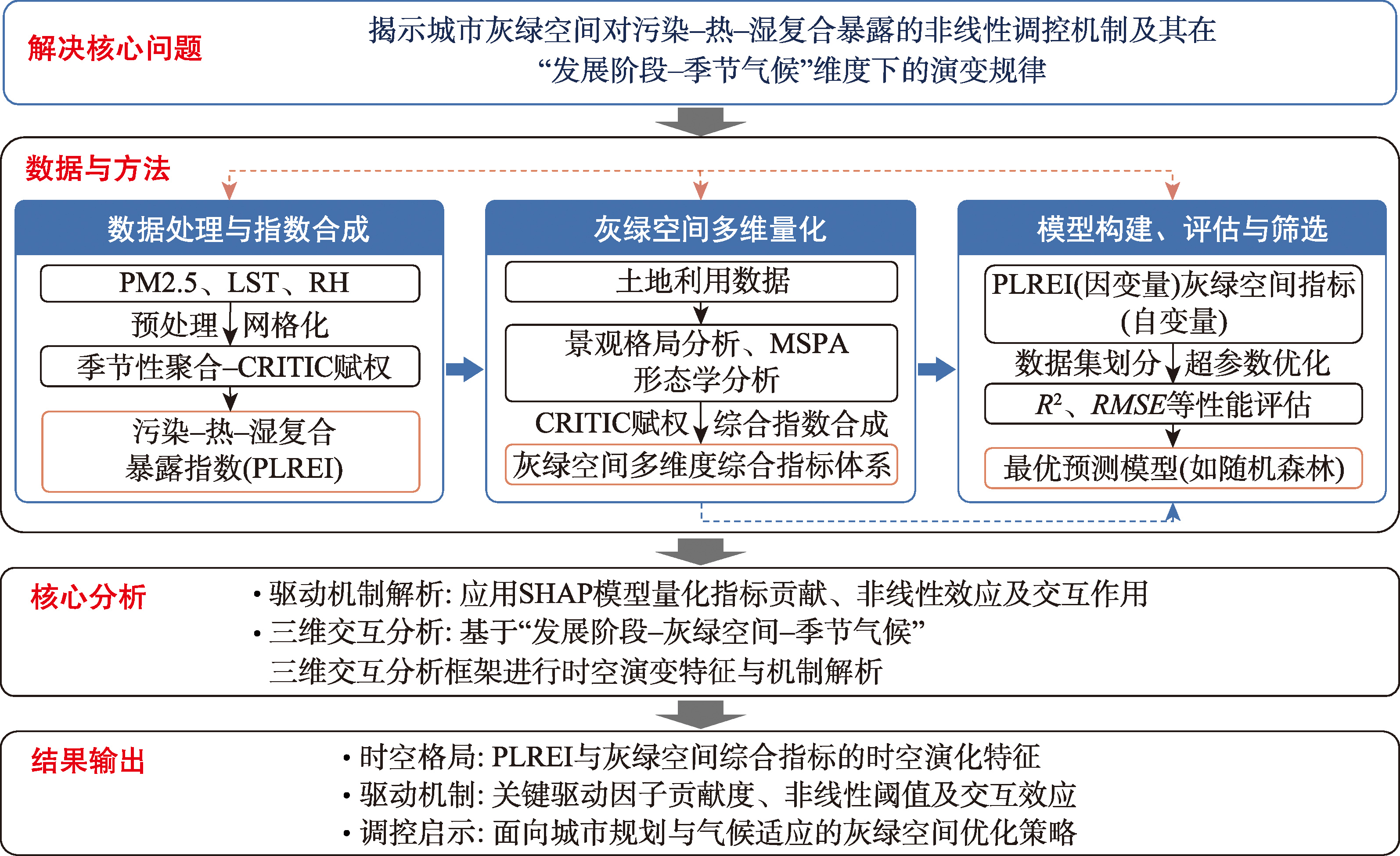
【目的】全球城市化与生态危机并行背景下,城市发展形态对污染-热-湿复合暴露管控提出差异化需求。传统空间量化评估方法因依赖同质化指标、忽视灰绿空间多维度属性及非线性交互效应,难以精准刻画复合暴露的时空分异与驱动机制。本文旨在构建一套集成形态学空间格局分析(MSPA)、客观赋权(CRITIC)与可解释性机器学习(ML-SHAP)的量化分析框架,系统解析灰绿空间对污染-热-湿复合暴露的调控机制。 【方法】本研究构建涵盖规模、复杂性、连通性与结构完整性4个维度的灰绿空间综合指标体系,将MSPA方法从绿色空间拓展至灰色空间,采用CRITIC客观赋权法替代主观评价,并集成ML-SHAP模型以量化非线性影响、阈值效应及交互作用机制。在此基础上,构建“发展阶段-灰绿空间-季节气候”三维交互分析框架,揭示城市发展阶段转型背景下灰绿空间污染-热-湿复合暴露调控机制的结构性演变规律。 【结果】应用该框架对扩张型资源城市进行实证分析,结果表明:① 该方法能够识别灰绿空间指标的非线性影响规律,建筑覆盖强度呈现S型阈值效应,阈值点由2010年的0.5~1.0个标准差前移至2020年的0.3~0.6个标准差; ② 该方法能够量化绿色空间调控效能的年际质变,夏季由“先正向后负向”转为全程稳定负向,冬季由弱正向转为稳定负向; ③ 该方法能够揭示灰绿空间交互作用的演变特征,灰色指标间的协同推升效应由春季偶发扩展至四季普适,交互强度由0.02~0.10提升至0.05~0.20。上述结果表明,复合暴露的演变由灰绿空间耦合模式而非单一要素决定,其调控本质在于耦合模式与城市发展阶段的动态适配。 【结论】本研究构建的MSPA-CRITIC-ML-SHAP集成方法,突破了传统单要素、线性假设的量化局限,实现了对灰绿空间多维度属性、非线性影响轨迹及交互作用机制的系统刻画,为解析城市生态系统的非线性响应机制提供了可拓展的分析工具,可应用于温室效应、热环境等其他城市生态问题的机制解析。
【目的】社交媒体已成为游客分享旅游体验、感知旅游地形象的重要平台。海滨旅游地作为热门旅游目的地类型,其形象的科学挖掘与呈现对目的地高质量发展具有重要意义。现有研究对旅游地形象挖掘多聚焦单一维度分析,缺乏统一的分析框架,且鲜有研究从淡旺季视角开展对比分析,存在明显研究空白。 【方法】本研究基于“认知-情感”模型和网络文本分析法构建了包含数据输入、分析处理、输出结果三大层面的多源社交媒体数据旅游地形象分析框架,明确了文本采集、语义提取、情感识别与结构呈现等技术路径,为旅游地形象的标准化、系统化挖掘提供了可借鉴范式。研究以三亚湾度假区为案例地,选取携程、去哪儿、马蜂窝及微博平台的21 598条有效游客评论为数据来源,运用上述方法开展实证验证,并以淡旺季形象差异为切入点,深入探讨游客对三亚湾度假区的旅游形象感知特征。 【结果】三亚湾度假区旅游形象在淡旺季情境下形成差异化的感知结构与情感取向,旺季游客偏好标志性景观与家庭游等,淡季则侧重休闲消费与深度体验等;情感形象整体积极正面,积极情绪均值达63.3%,显著高于消极情绪均值的15.5%。三亚湾度假区内部存在内部空间异质性,受资源类型与游客预期的共同影响,四大片区构成兼具不同吸引物与体验功能的“微目的地”感知单元。 【结论】本文构建的分析框架能够系统识别旅游地形象的认知要素、情感属性与语义结构,具备良好的可迁移性与可扩展性,可为海量游客文本的动态化形象提取提供规范的技术路径。实证部分进一步揭示了三亚湾旅游形象的季节性差异与空间异质性特征,为海滨旅游地的形象塑造、分区管理与策略优化提供了方法支持与经验参考。

{kind=link}