
关闭×

【意义】随着遥感测绘与自动驾驶技术的快速发展,三维点云语义分割作为数字孪生系统的核心基础技术,其研究热度持续升温。航空点云语义分割被认为是有望提升三维地理信息系统的自动化、智能化的关键技术之一。【分析】在深度学习技术和激光雷达(Light Detection and Ranging, LiDAR)、深度相机、三维激光扫描仪等传感器的推动下,点云语义分割技术通过精确的特征提取和高效的模型训练能够实现大规模点云数据的自动分类和高精度识别。然而,相比于高密度、类别均衡的典型点云语义分割数据集(如室内点云数据或自动驾驶和机器人领域的室外点云数据),航空点云由于其特有的数据特性(如大范围三维地形覆盖、动态平台运动误差累积、地物空间尺度差异大、复杂地物遮挡等因素),在点云配准、特征提取等关键环节仍面临显著挑战,目前基于深度学习的航空点云语义分割研究仍处于起步阶段。同时,受限于数据不同获取方式、不同分辨率、不同属性信息,现有研究距离算法落地应用还有一段距离。【进展】本文旨在对这一领域的发展进行全面的分析研究,包括各类适应算法的特点、数据集、性能指标和最新提出的方法,以及它们的优势和局限性。此外,本文还提供与现有技术水平的定量比较,对有代表性的方法进行研究,包括精度分析和适用性能分析。【展望】最后,总结分析航空点云语义分割技术突破亟需在特征表达、多模态融合、小样本学习、点云语义分割算法可解释性及大模型基准构建等多个维度开展系统性研究创新,不仅有助于解决当前算法在实际部署中的瓶颈问题,还可为数字孪生城市、灾害应急响应等重大应用提供可靠的技术支撑。
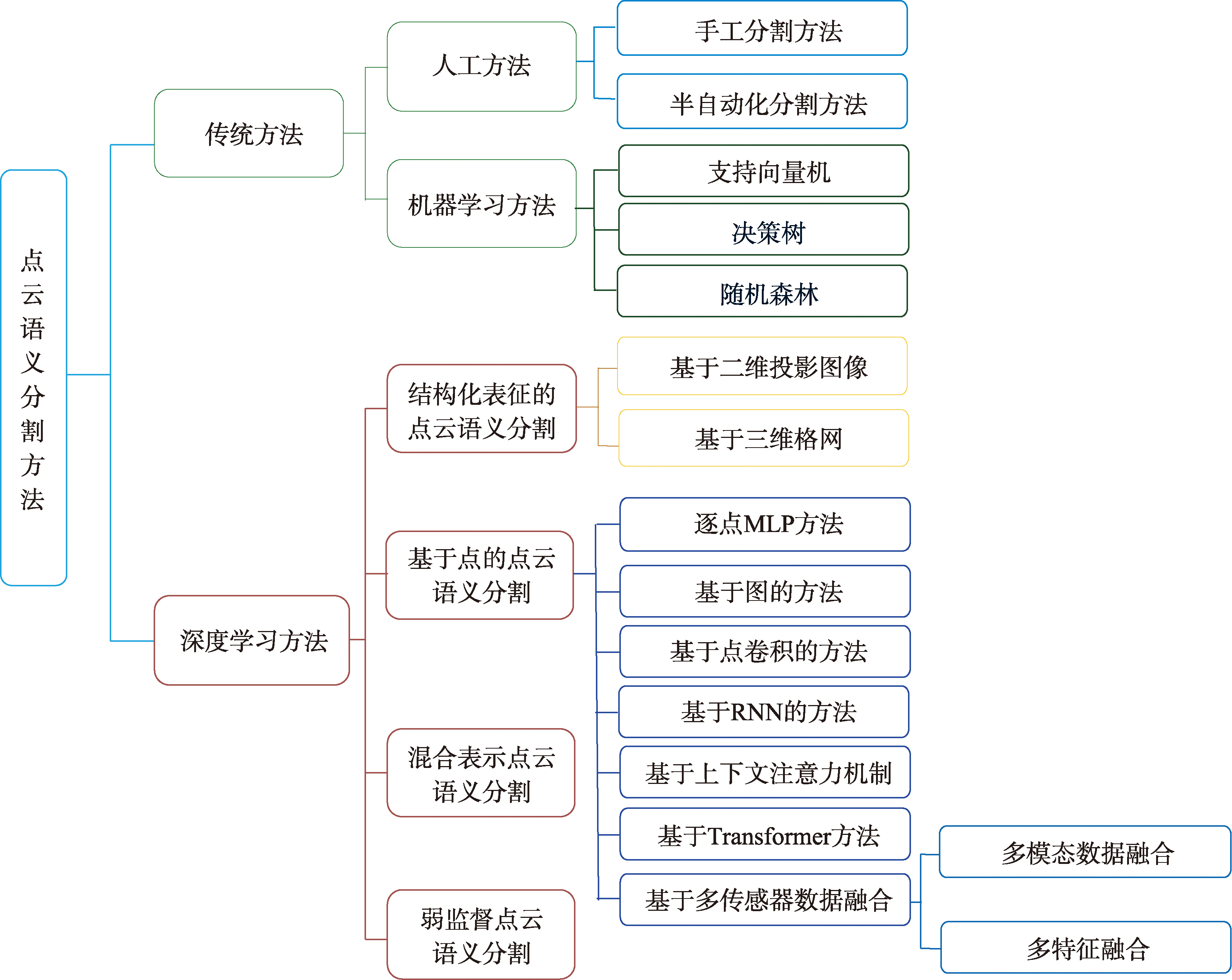
【目的】由于建筑物屋顶结构复杂多样,机载LiDAR点云密度不均且缺乏语义信息,导致现有基于数据驱动的建筑物三维模型重建框架难以准确构建几何基元间的拓扑关系,针对此类问题,本文在现有屋顶面分割及轮廓线提取算法基础上,提出一种基于跨面片线拓扑匹配的建筑物三维模型重建框架。【方法】首先,利用改进的D-P算法简化各屋顶面片轮廓线生成轮廓边,并采用先验的边界特征作为非强制性的几何约束来规则化轮廓边;其次,对于不同面片边界上的轮廓边及其对应的轮廓点集,统计水平方向上相邻点对的数量,根据相邻点对的比例匹配位于不同面片中代表同一内部特征线的同名轮廓边,以确定屋顶面片间的拓扑关系;最后,对相互匹配的同名轮廓边进行缝隙合并及端点优化,生成各屋顶面片紧密排列的建筑物结构化三维模型。【结果】选取Vaihingen、Building3D两组数据集中典型的建筑物点云对本文所提框架进行验证,实验结果表明:改进的D-P算法能够在完整保留初始轮廓线关键结构特征的同时,有效抑制伪轮廓拐点的生成;非强制性的单直角和双直角短边约束,可以兼顾屋顶面片的边界形状以及先验的典型屋顶结构,适用于各种边界类型;采用跨面片线拓扑匹配的拓扑关系构建方式,可以处理同时包含阶跃和相交关系的相邻屋顶面片,确保屋顶几何基元间拓扑关系稳定和完整的构建;最终得到的建筑物三维模型平面与参考平面的原始点云覆盖率之差均小于17%,模型保真度均小于0.168 m。【结论】本文所提框架构建的建筑物三维模型具有屋顶结构完整、适应性强、精度高等特点。
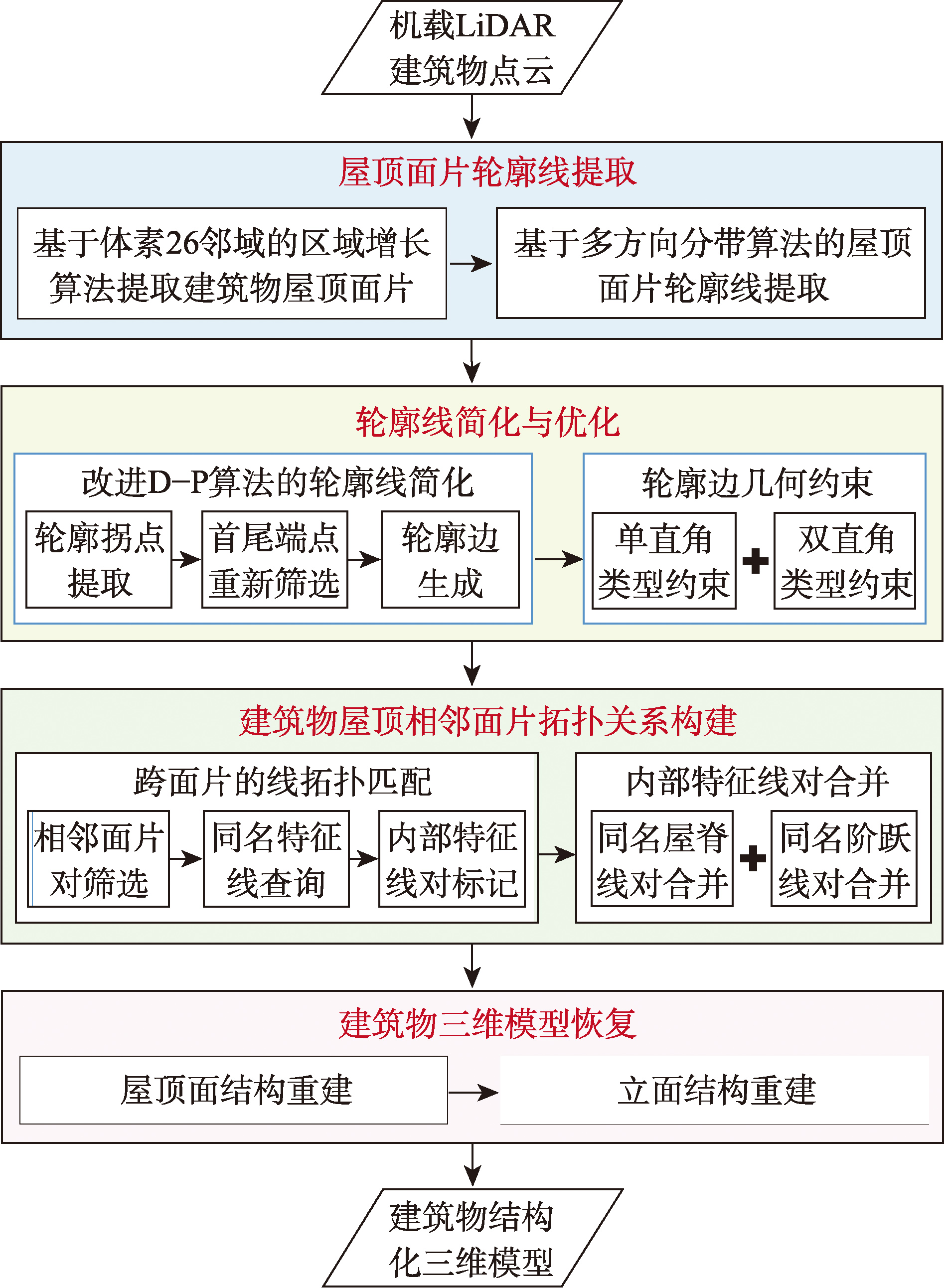
【目的】国家“十四五”规划明确提出实施城市更新行动,特别是以老旧小区为载体的住区更新。但现有的住区更新实践仍缺乏对更新时序的统筹安排与操作指导。【方法】运用PBL-BPNN算法和多源数据构建评价方法和指标体系,并将住区更新敏感度作为更新可能性的度量值量化更新时序的研究内容。该方法综合考虑住区建成环境、人口分布等多重指标,通过对已更新住区的特征提取,实现更新时序的大规模量化分析。【结果】对比传统评价指标模型和加入多源数据后的模型发现,后者在验证集上10折交叉验证的RMSE为0.142 2, F-score为0.750 9,在测试集上的准确度提升了32.78%,证明了该方法和评价指标的有效性。实证分析发现,南京中心城区的住区更新敏感度呈现“内部高,外部低,多点散布”的空间格局;同时,多源数据中的商业资源、公共空间资源、工作日人数、围合度、丰富度和宜人感6条指标对住区更新敏感度的评价产生较大影响。【结论】该方法运用数据挖掘思想和机器学习技术,突破了传统更新时序评价方法中主观性较强的局限,可作为住区更新规划和实施的决策依据,并为住区更新的时序判断提供技术方法支持。
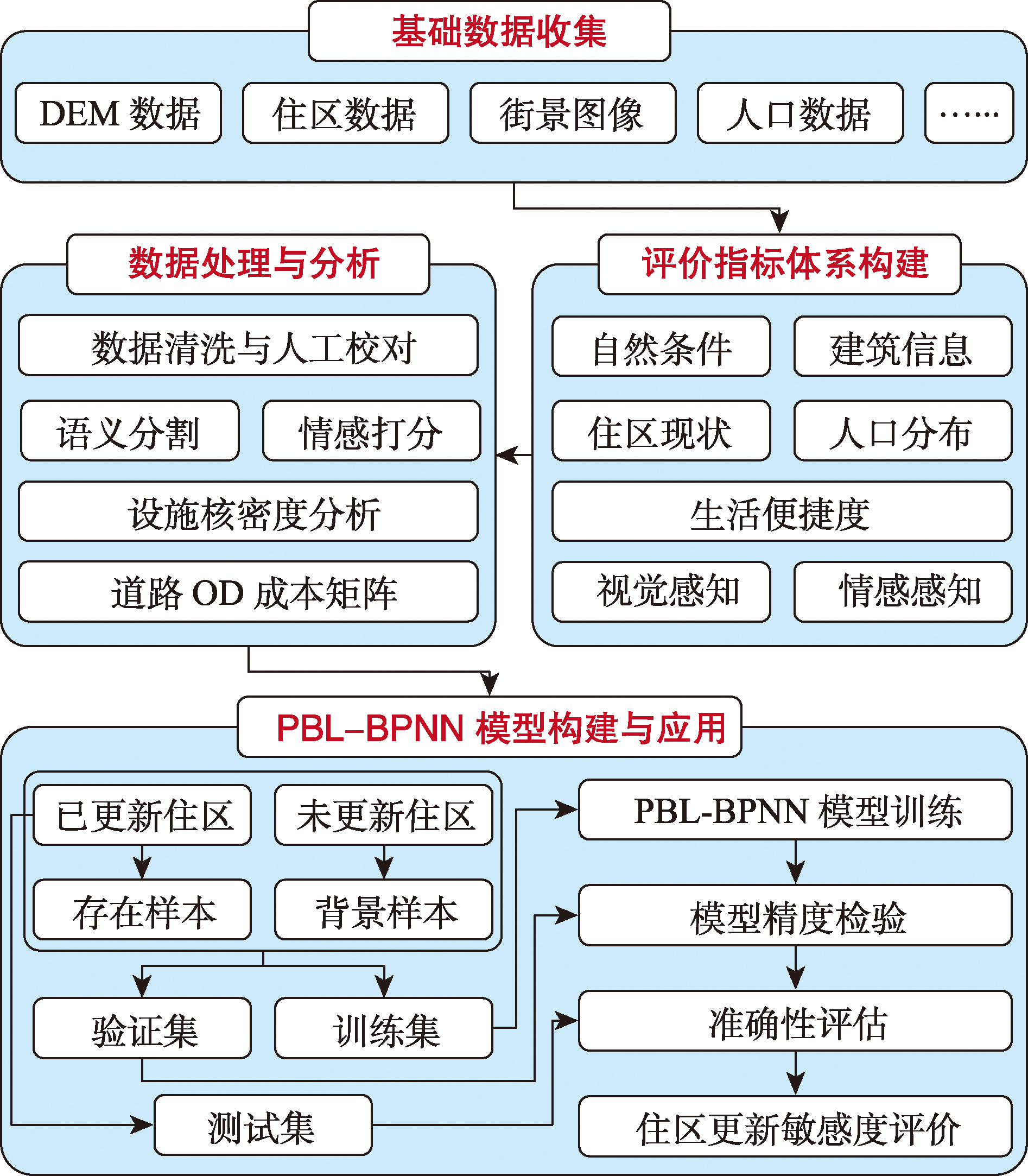
【目的】道路网作为基础地理要素,研究道路网向量表征方法及其在路网模式识别的应用,不仅有助于分析道路网空间结构,也为地球系统数字孪生的信息表征处理提供计算方法。当前,多数路网模式识别方法计算复杂、缺乏智能推理的能力、依赖大量标签数据且泛化能力有限,在复杂路网结构下模式识别表现受限。【方法】本文面向路网模式识别任务,提出了一种基于几何相似性图表示学习的识别方法。首先,通过空间对偶图对道路网进行建模,并基于认知启发设计了图节点特征。然后,采用无监督的方式训练模型,同时在路段嵌入学习阶段引入子图同构计数(SIC)和图嵌入生成阶段引入全局上下文注意力机制(GCA),增强模型表示性能。最后,利用图级嵌入的几何相似性识别路网模式。为验证本文方法的有效性,构建了包含5种路网模式的数据集并开展了充分实验。【结果】本文提出的SUGAR-3模型的分类准确率达到93.18%,相比于经典路网模式识别方法提升12%以上,显著高于GCNN等多类基线模型。此外,对本文模型的图嵌入和表示性能进行了深入分析,结果表明本文模型表征的路网模式能有效聚类且在不同模式之间形成明显边界。【结论】验证了SIC和GCA在提升路网模式识别性能方面的有效性,为进一步提升道路图表示性能提供了新思路。
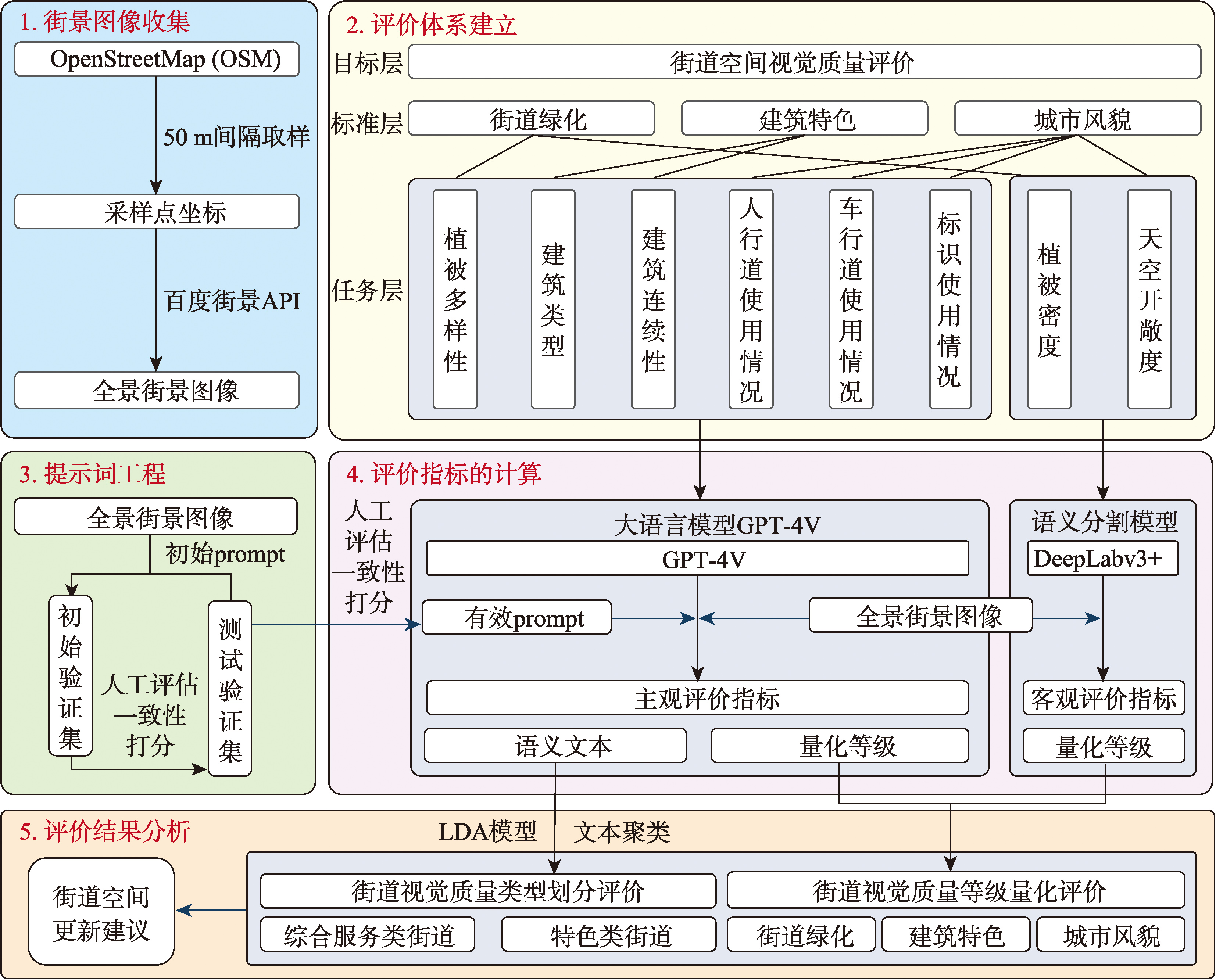
【目的】街道空间是行人在城市环境中的主要感知界面,高品质的街道空间视觉质量对提升街道空间活力具有重要意义。传统方法多依赖单一客观指标进行评价,难以有效衔接客观环境特征与行人主观感知。【方法】本研究提出一种基于大语言模型进行评价的新框架,纳入主观感知的“风格维度”,将传统的单一指标量化分析扩展到数量化与风格化的综合分析。本框架基于百度街景图像,结合语义分割技术评价植被密度与天空开敞度2项客观指标;结合先进的大语言模型能力,通过提示词工程进行优化,评价植被多样性、建筑类型、建筑连续性、人行道使用情况、车行道使用情况及标识使用情况6项主观指标。最终结合潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)主题模型对研究区的街道类型分类,以探讨不同街道的空间特征及其优化方向。【结果】以北京市西城区为研究区,研究结果揭示了区域内植被密度与天空开敞度的空间分布情况,呈现了行人对植被多样性、建筑类型等指标的主观评价。通过聚类分析识别出以西单北大街为主的综合服务类街道、以西黄城根南街为主的特色类街道以及以灵境胡同为主的混合类型街道。【结论】本研究创新性地引入具有人类感知能力的大语言模型,并结合提示词工程提高模型性能,实现街道视觉质量的高效、主客观融合评价,为大规模街景图像自动化评估提供参考。
【目的】早期的视觉位置识别方法大多采用手工特征来对图像进行表征,无法同时应对图像视角、光照、季节等较为复杂的外观环境变化,其鲁棒性和泛化性往往表现不佳。为此,本文针对现有视觉位置识别方法因图像视角和复杂外观环境变化等因素导致场景识别困难进而导致模型的鲁棒性和泛化性表现不佳的问题,提出一种融合多级特征与关系感知全局注意力的视觉位置识别方法。【方法】首先,利用深层卷积神经网络提取图像不同层次的特征图;其次,利用特征提取过程中产生的多尺度特征并进行融合以弥补单一尺度特征信息表达能力不足的缺陷;然后,使用关系感知全局注意力对融合特征进行增强、抑制冗余噪声信息,以达到着重学习场景图像中关键目标的目的;最后,使用局部聚合向量网络MixVPR对局部特征编码构造鲁棒紧凑的图像描述符并基于多重相似性损失进行训练。【结果】在Pittsburgh250k、 Pittsburgh30k、 SF-XL-Val、 Tokyo 24/7、Nordland、 SF-XL-Testv1共计6个公开街景影像数据集上进行试验,本文方法的召回精度在各个数据集上均有一定程度上的提升, Recall@1最高在各个数据集上分别达到了94.20%、91.56%、85.15%、83.81%、75.43%和73.60%。【结论】试验结果表明本文方法对图像视角和复杂外观环境等场景变化具有一定的鲁棒性和泛化性。

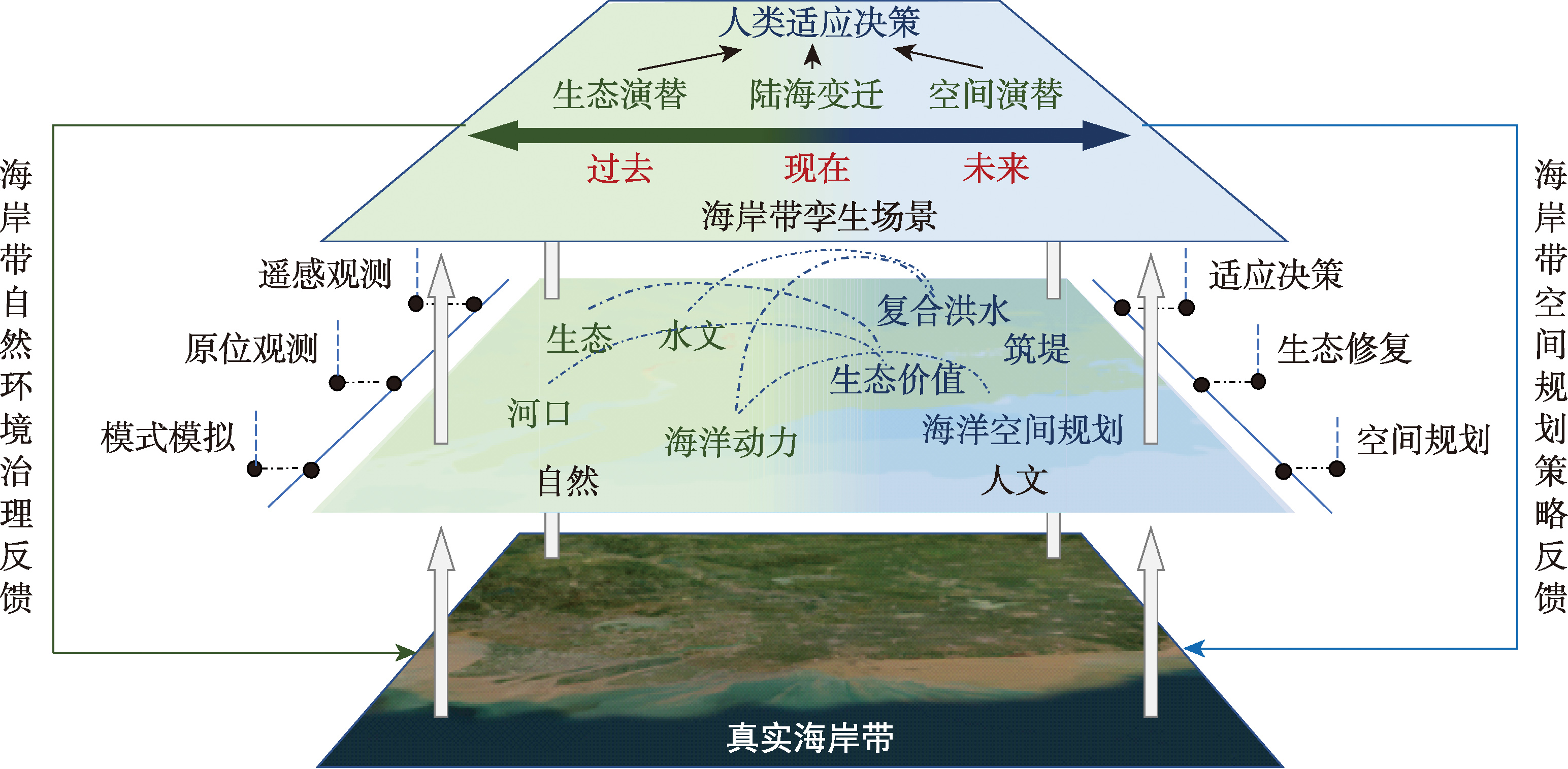
【目的】随着全球气候变化、海平面上升与人类活动不断加强,海岸带人-地-海关系发展呈现出复杂性、敏感性和脆弱性等特征,亟需建立集成环境感知、过程模拟和情景推演的海岸带综合研究体系。数字孪生作为一种融合数据、模型与知识的智能系统新范式,为海岸带复杂系统的精准镜像与智能调控提供了新思路。【分析】本文系统梳理了当前海岸带数字化建设发展脉络,分析了在多重压力下海岸带自然与人文强耦合的数字化建设需求,提出以陆海交互过程为场景基底,人-地-海互馈为演绎主线的数字孪生海岸带建设思路与框架。本文从信息集成与知识聚合、自然过程模拟与人地耦合决策、短期预测与长期监测、真实表达与智能交互4个方面构建系统架构,讨论了海岸带数据治理、场景建模、要素预测、长期监控以及数字孪生系统平台的关键技术。【展望】以多源数据时空融合场景为基础、以推演与干预能力为目标的数字孪生海岸带,将有助于突破传统海岸带数字化系统建设瓶颈,提升海岸带系统的可计算性与可管理性,有望为气候变化背景下的海岸带可持续发展与治理体系现代化提供新工具与新范式。
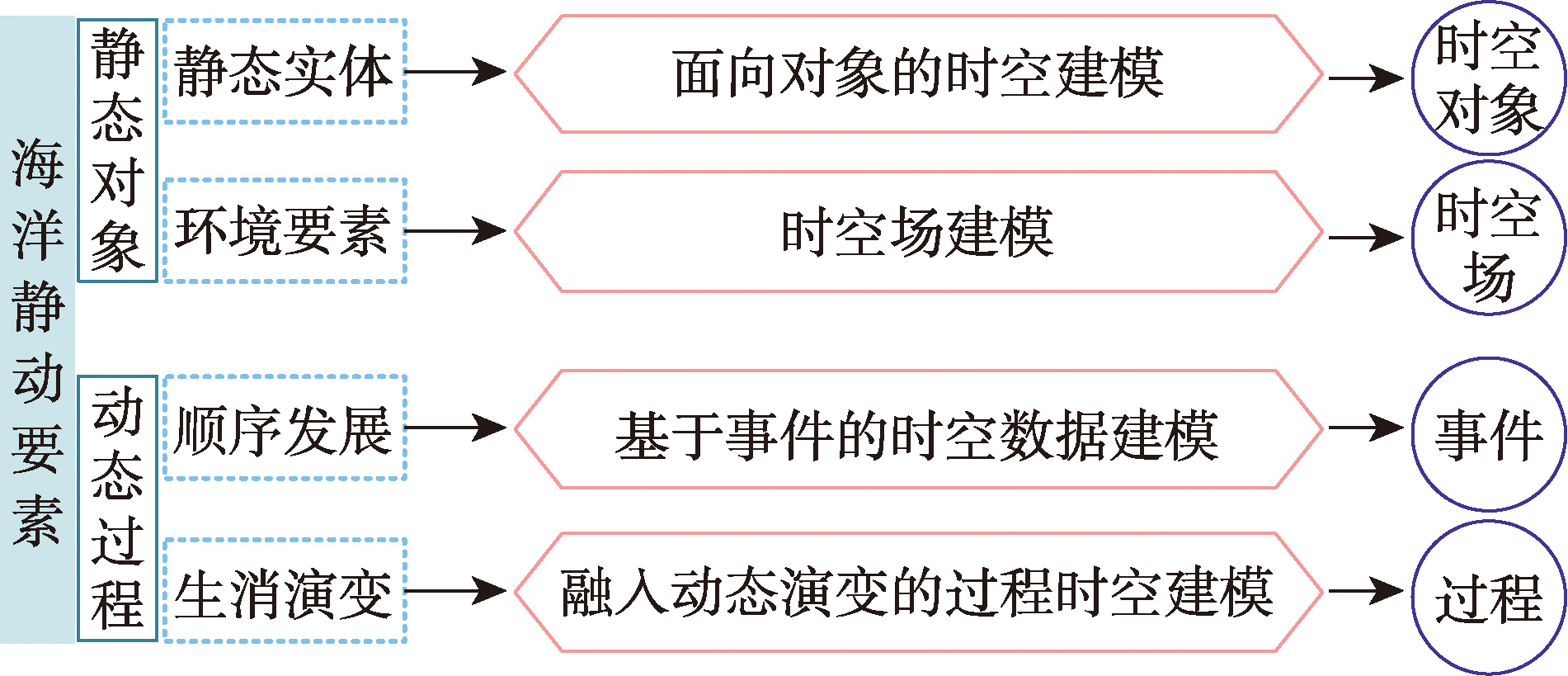
【目的】海洋孪生空间由真实海洋、虚拟海洋与它们之间的双向链接组成。面向孪生空间的海洋时空建模方法需要对研究区内所有海洋对象、现象以及它们之间的关系同时进行表达与建模。然而,目前的时空模型(面向对象的、时空场、基于事件的以及融入动态演变的过程时空模型)侧重于单一海洋现象(对象、场、事件、过程)的建模,由于缺乏统一的组织结构,难以全面实现海洋环境的综合建模。【方法】本文在面向对象的、时空场、基于事件的、融入动态演变的过程时空模型基础上,设计了统一的时空数据组织结构,提出了一种面向孪生空间的海洋静动一体图模型。该模型的核心内容包括: ① 通过对实体对象的层次设计和属性设计,建立了“实体对象-数据描述-数据序列”的统一组织结构,从而实现了时空对象、时空场、事件、过程四类对象的统一组织; ② 分析了海洋环境要素从真实海洋向虚拟海洋的映射过程,设计了在孪生空间中海洋静动要素之间的关系表达; ③ 融合四类对象的统一结构与静动要素间的关系表达,提炼出时间、实体对象、孪生对象、孪生场景和关系5个核心元素,并将核心元素中的实体和关系抽象成节点和边,构建了“孪生场景-孪生对象-实体对象-数据序列-时间”的5层图表达框架。【结果】以海南省三沙市西沙群岛永乐环礁东北部的银屿及其周边海洋要素的组织管理为案例,验证了面向海洋孪生的静动一体图模型的可行性和有效性。与对象和场的混合模型、GeoKG、GEKG的模型对比表明,该模型不仅实现了静动要素的统一组织,而且能更为全面地表达海洋对象间的关系。【结论】面向孪生空间的海洋静动一体图模型解决了孪生空间中静动数据割裂的问题,提升了海洋数据管理与利用效率,有助于海洋管理从数字化到智能化发展。
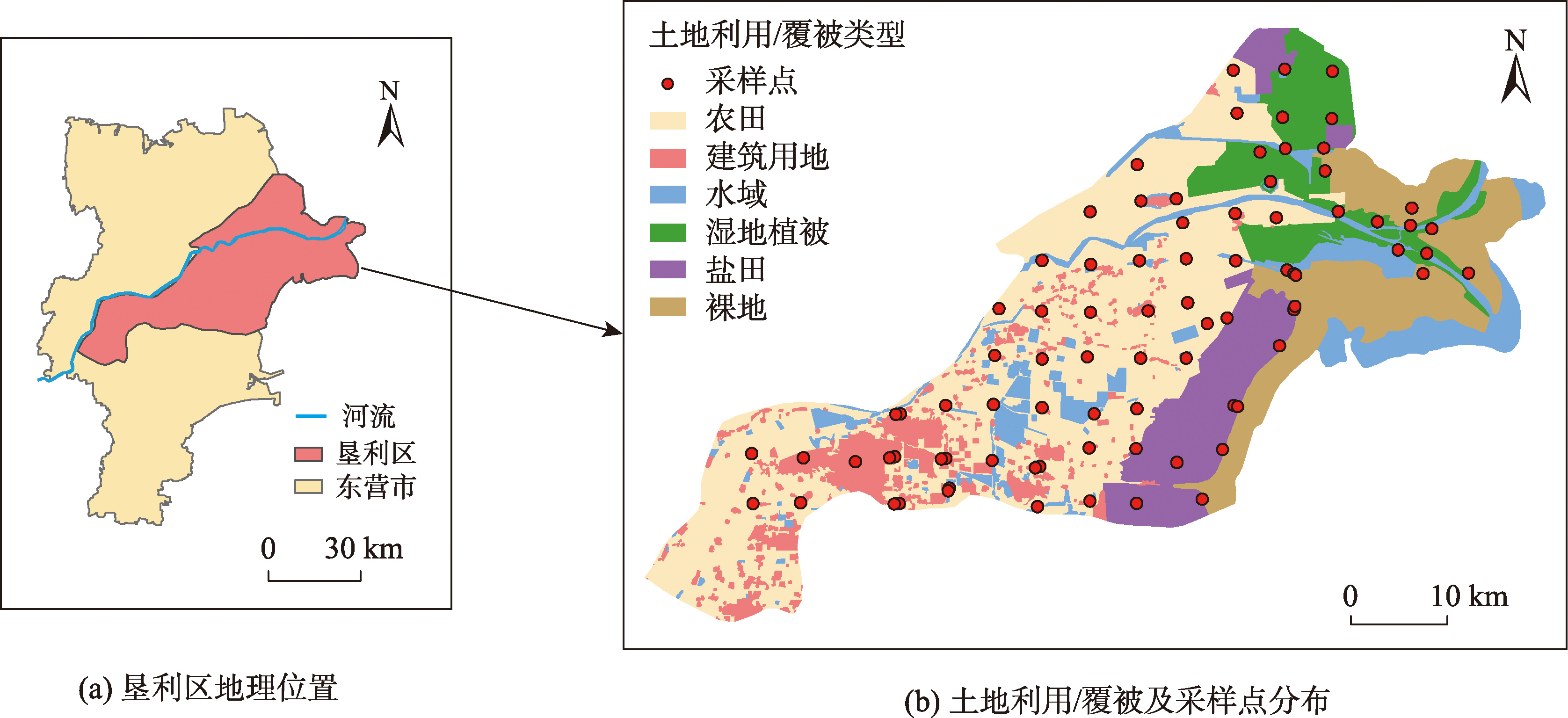
【目的】土壤盐渍化严重制约了农业可持续发展和生态安全,土壤盐渍化的精确评价分析,对土壤盐渍化的改善和治理具有重要意义。【方法】针对滨海盐渍区土壤盐分三维空间分布情况不清晰问题,本文选取黄河三角洲盐渍区0~100 cm土体范围垂向分层819个有效野外土样为对象,综合运用传统地统计法、3D经验贝叶斯克里金插值等方法,从不同视角揭示滨海盐渍土区土壤盐分的三维空间分异规律,采用地理探测器系统地定量分析各影响因素对土壤盐分空间分异的影响。【结果】结果表明,整个土体范围及垂向各分层土壤盐分空间分布均属强变异,不同深度土壤盐分空间自相关的尺度存在差异性。文中引入3D经验贝叶斯克里金插值法,有效地揭示了土壤盐分垂向精细尺度的三维空间特征。土壤盐分呈现显著的三维空间分异,剖面分布类型多样,整体上以均质型和表聚型为主,局部存在底聚型、波动型。所选影响因子对土壤盐分三维空间分异均具有显著影响,但各因子影响程度不一,各因子解释力大小排序依次为土地利用/覆被>到海岸线距离>地下水埋深>地下水电导率>高程>地表温度>土壤容重>黏粒含量。无论0~100 cm整个土体范围还是垂向各土壤分层来看,与单因子相比,任意因子两两交互作用均对土壤盐分空间分异产生更大影响,但不同因子交互作用强度有所差异。土地利用/覆被、地下水埋深、地表温度和土壤容重等因子与研究区土壤盐分的空间分布具有密不可分的关系。整个土体范围,地下水埋深∩土地利用/覆被(GWD ∩ LULC)的交互作用影响最大,其值为0.443,地表温度∩土地利用/覆被(LST ∩ LULC)次之,其值为0.326。【结论】虽然地表温度和土壤容重的单因子q值均不高,但是与土地利用/覆被交互作用后对土壤盐分的解释力大幅提高,能够较好地解释研究区整个土体的土壤盐分变化。研究成果为后期该区域制定盐碱地精细尺度的综合改良举措与管理制度提供了理论依据和技术支持。
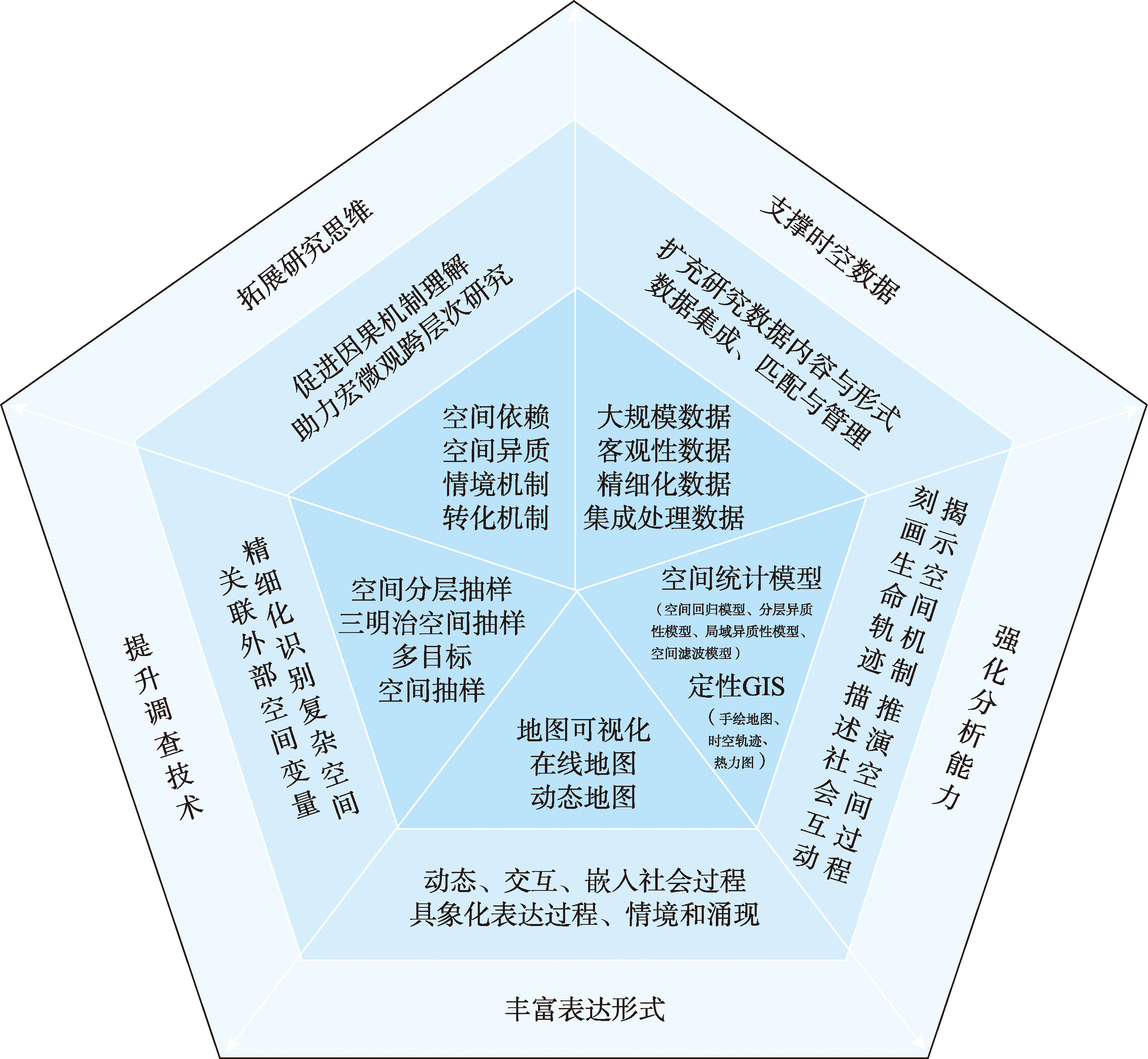
【意义】社会现象本质上具有内在空间属性,空间视角为解析复杂社会问题提供了关键路径。随着社会科学“空间转向”的不断深化,以及地理信息系统(GIS)在数据获取、空间分析与建模、空间可视化等方面的持续进步, GIS已成为社会问题求解的重要工具。然而,地理学与社会科学在理论范式、方法逻辑与尺度认知上的差异,制约了二者的深度融合。亟需系统厘清其融合路径,辨识核心挑战与潜在机遇。【进展】本文提炼GIS赋能社会科学研究的五大优势:拓展研究思维、支撑时空数据、提升调查技术、丰富表达形式、强化分析能力;综述其在经济学、政治学与社会学中的典型应用,揭示跨学科共性与学科差异;深入剖析融合过程中的三重挑战——数据与问题的匹配难题、方法与机制的整合困境以及地点与尺度的情境错位,并提出针对性的应对路径。【展望】人工智能,特别是大模型的发展,为GIS空间分析注入新方法论动能。未来应构建“大模型-空间分析”协同范式,推动GIS从工具应用向理论支撑跃升,提升其在社会问题求解中的科学价值与实践效能。
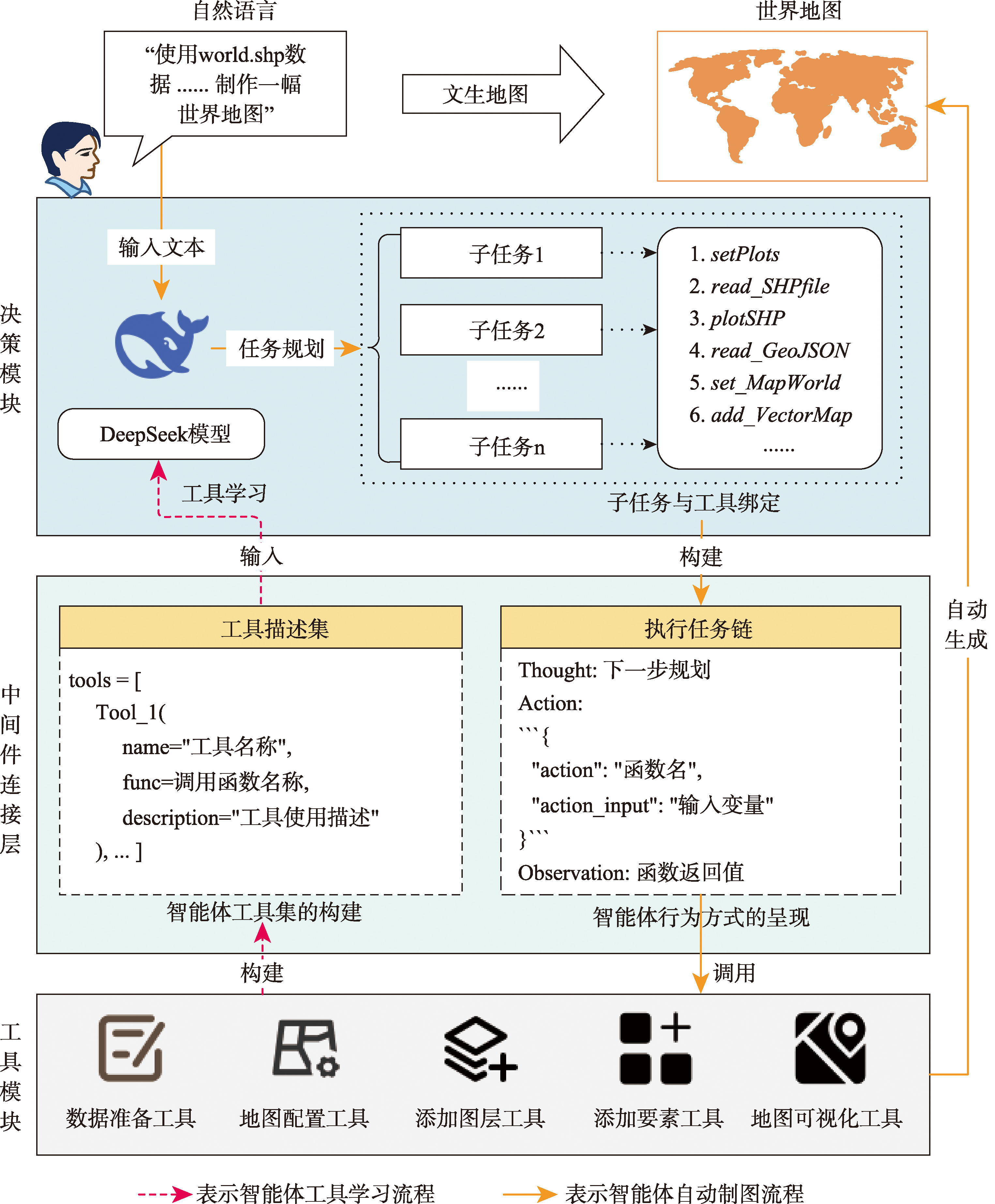
【目的】地图编制涉及要素选取、符号化与注记配置等专业操作,存在制图过程复杂、效率不高等问题。基于大语言模型(LLM)的文生地图制图技术可以大大简化制图过程,提高了制图效率,但仍存在人工调试依赖度高、工具调用流程碎片化等问题。【方法】本文提出基于DeepSeek的文生地图智能体构建方法,通过对自然语言指令的任务分解与工具自主适配,实现了从用户输入到可视化输出流程的自动化处理。研究以DeepSeek模型为核心,为地图要素配备制图工具及使用描述,分析模块结构及协作机理,构建了5类工具集,通过理解指令推理生成任务思维链,调用可视化工具实现自然语言到地图的跨模态映射。【结果】为检验智能体的有效性,分别以基于本地地图数据和网络地图服务的制图任务为对象,以DeepSeek-V3-0324和R1模型作为决策核心,完成了基于自然语言的自动制图任务。实验表明文生地图智能体可以在低工具复杂度任务中实现工具复用,并具备通过多工具链式调用完成高复杂度生成任务的能力。【结论】基于DeepSeek构建的智能体可以较好地完成文生地图任务,且通过40次重复实验发现: V3的执行效率是R1的6.56倍,平均执行效率约为6.29 s/step,对LangChain Agent的模块化适配性更优。
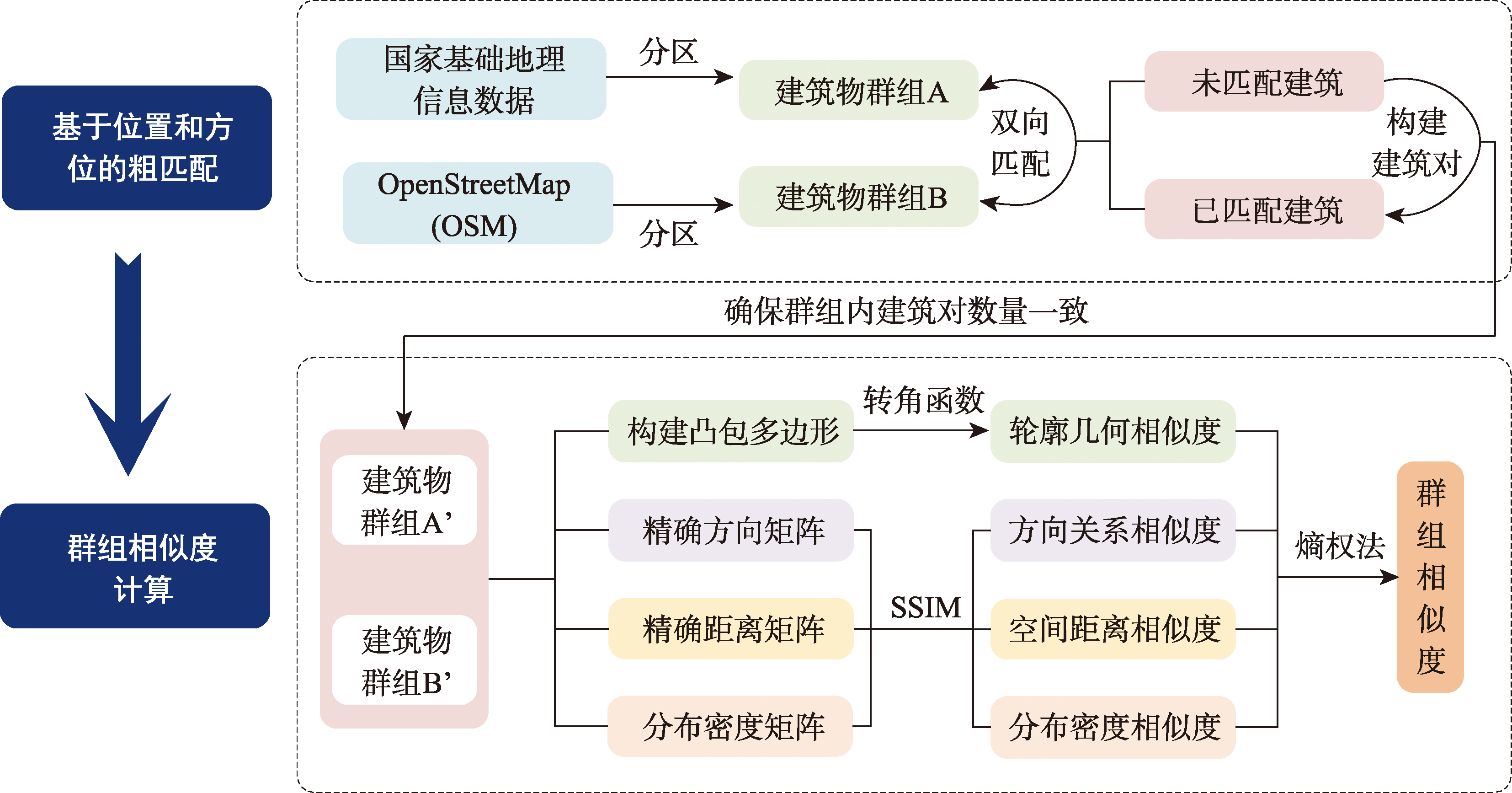
【目的】建筑物匹配一般通过计算建筑的几何相似度来判断是否为同名实体。现有的建筑物群组匹配方法主要顾及了群组外部轮廓相似性,忽视了群组内部个体之间的空间关系和分布特征,当群组轮廓相似但内部结构差别较大时则无法实现精确匹配。【方法】本文提出了一种空间相似关系支持下的建筑物群组匹配方法。首先,该方法利用建筑物坐标和方位角对包含不同数目建筑物的群组进行初步匹配;然后,以精确方向关系矩阵计算各建筑在建筑群中的具体方向,以质心点的间距构造距离矩阵,引入结构相似性指数计算矩阵的相似度来定量描述方向及距离相似程度;并结合群组轮廓的几何特性和建筑在群组中的分布区域,利用熵权法确定各项指标的权重,最终得到综合考虑多种因素的建筑物群组相似度结果。【结果】实验选取了兰州市6个建筑物群组对应的国家基础地理数据及195个OSM建筑物群组数据进行匹配试验,实现了精确匹配;并选取了包含1 511个建筑的城市区域,将其基础地理数据与2023年及2024年OSM数据进行质量评价实验,计算得到相似度依次为78.35%、79.12%, OSM数据完整度呈现出逐年提高的趋势。【结论】该方法能够综合度量群组中个体的方向、距离、分布密度相似性以及整体的几何相似性,提供了一种全面的定量计算思路来兼顾整体布局与内部空间关系,不仅可以实现同名群组精确匹配,而且可以用于局部区域的数据质量评价。
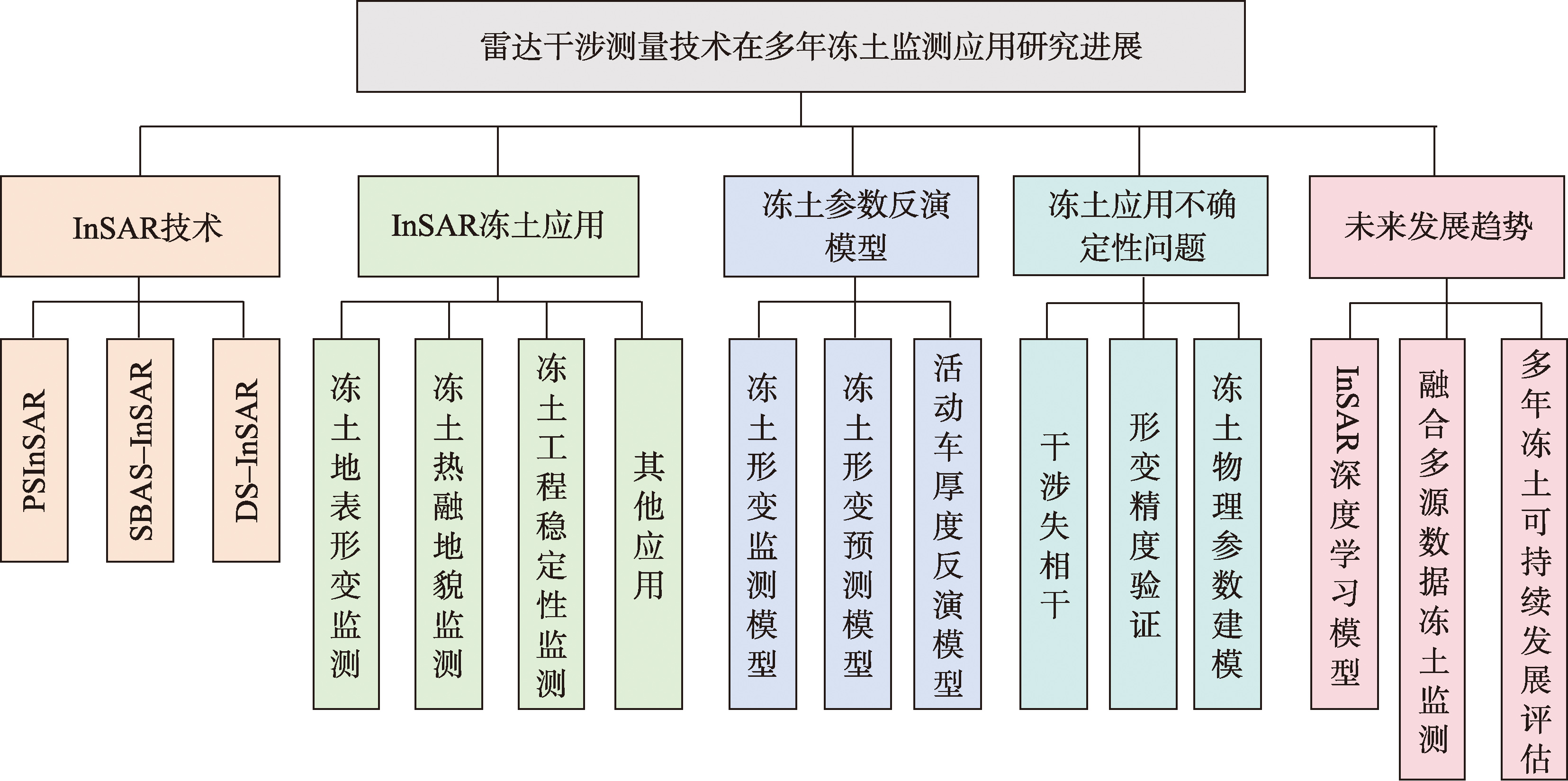
【意义】多年冻土监测是合成孔径雷达干涉测量(Synthetic Aperture Radar Interferometry, InSAR)技术重要的应用领域之一。近年来,随着SAR卫星系统的升级、InSAR技术算法的发展以及多源遥感技术的深度融合,多年冻土监测InSAR监测应用取得了重要的进展,为监测和评估气候变暖背景下的冻土退化提供了有效的技术手段。【进展】本文系统梳理了InSAR冻土监测研究的创新性进展,并挖掘其学科交叉潜力。介绍了常用的合成孔径雷达(Synthetic Aperture Radar, SAR)卫星系统,InSAR方法的基本原理与发展,梳理了已有多年冻土研究区的地理分布特征及多年冻土InSAR领域文章数量统计。全面评述了InSAR在冻土形变监测、物理机制驱动模型构建、形变预测及活动层厚度反演中的前沿成果,重点探讨了如何通过融合多模式雷达遥感与冻土模型突破干涉失相干、冻土参数建模不完善等长期瓶颈问题。【展望】面向多年冻土区可持续发展需求,分析了InSAR研究多年冻土在深度学习、多源数据融合以及多年冻土地区的可持续发展评估等方面的发展趋势。本文不仅为冻土InSAR研究提供了方法集成与挑战应对的路线图,也为北极工程安全、生态系统稳定性评估等重大应用研究奠定了技术理论基础。
【目的】无监督变化检测是合成孔径雷达(Synthetic Aperture Radar,SAR)影像信息提取领域的研究热点之一。然而,现有研究通常使用单一方法获取伪标签,致使伪标签可靠性不足。此外,现有方法主要利用多时相影像的空间域特征提取变化信息,在空间-频率双域特征融合利用方面的探索研究较少。为此,本文提出了一种基于Mamba的空间-频率双域特征融合UNet模型,用于SAR影像无监督变化检测。【方法】首先,该方法利用本文提出的差异影像分割-聚簇融合的伪标签生成方法,获得高质量的伪标签样本数据,以克服深度学习变化检测模型对人工标注样本数据的依赖。然后,构建了基于Mamba和小波卷积的空间-频率双域特征融合UNet变化检测模型,用于提取变化信息。该模型一方面利用Mamba高效提取全局特征,并与卷积网络提取的局部空间特征相融合,另一方面利用小波卷积增强频率域特征提取,进而在类UNet模型上采样过程中实现空间-频率双域特征的互补融合。【结果】为了验证本文提出方法的有效性,在2个SAR影像数据集上进行了实验,并与传统方法和深度学习方法进行了定性和定量比较。与前述对比方法中最好的变化检测结果相比,本文方法在2个数据集上的平均F1_Score提高了2.35%, Kappa系数提高了2.65%,有效提高了变化检测结果的可靠性。【结论】本文提出的方法有效提高了SAR影像变化检测的自动化程度和变化检测结果的可靠性,可为环境监测、城市扩张和灾害评估等研究提供技术支撑。

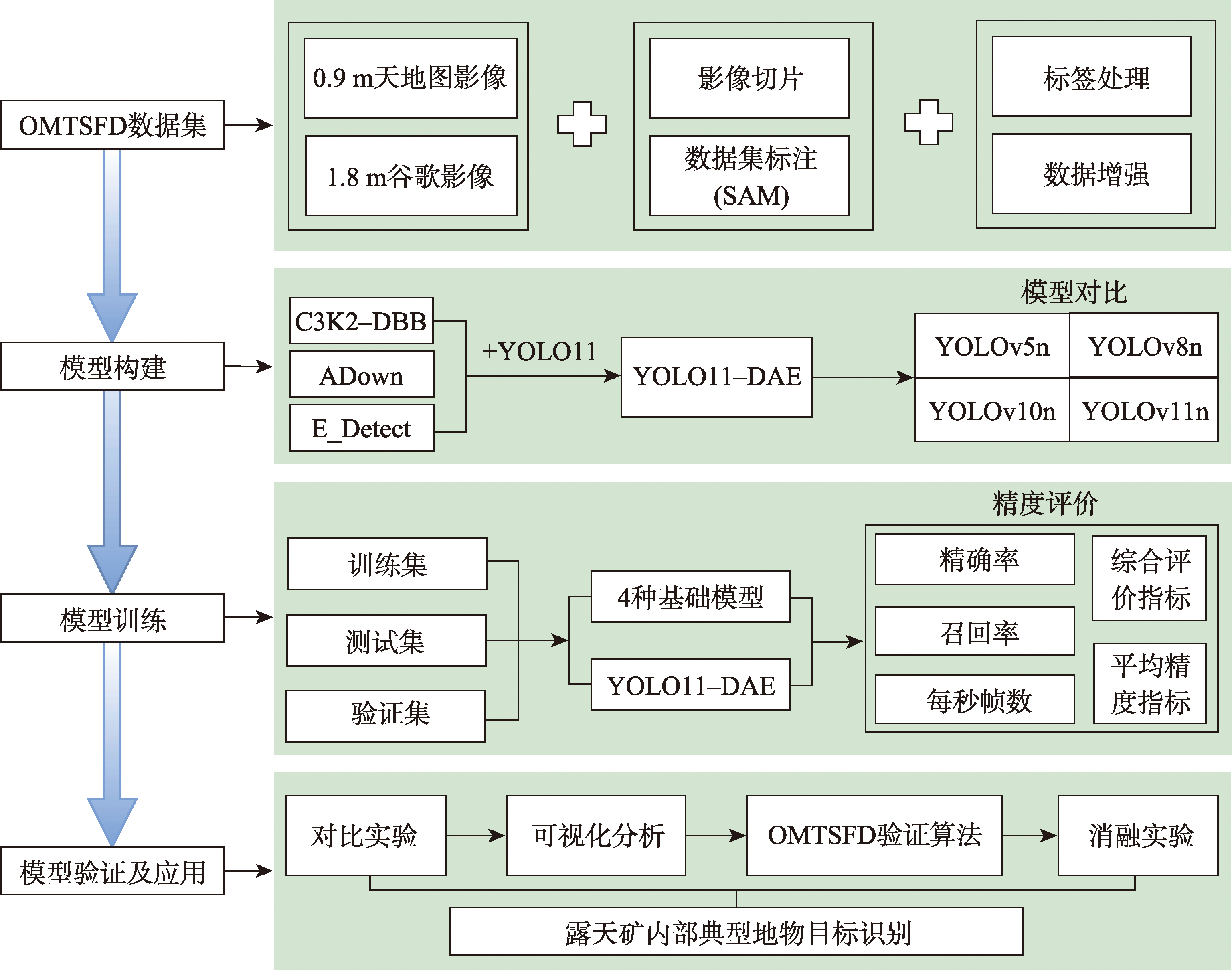
【目的】矿产资源是人类生存和经济发展的重要物质基础,开展矿山监测、建立矿山监测模型对矿产资源的高效开发和矿区环境保护具有重要意义。针对露天矿区背景复杂、目标尺度多样且小目标聚集的特点,本研究旨在构建兼顾监测精度与效率的轻量化模型,以提升矿区目标地物监测的准确性和效率。【方法】现有遥感数据集存在的样本单一、地域局限等问题,因此本文基于0.9 m天地图与1.8 m谷歌影像构建了不同气候背景、大范围和多种地物的六大露天煤矿基地OMTSFD(Open-pit Mine Typical Surface Features Dataset)数据集,提出改进的YOLO11-DAE算法进行模型训练与验证。首先,在骨干网络和特征金字塔中引入C3K2-DBB模块以增强多尺度特征捕获能力;其次,采用ADown模块替换网络下采样卷积,增强了模块对不同特征的表征能力,减少了低对比度场景的细节丢失;最后,采用E_Detect高效检测头降低模型复杂度和参数量,实现模型轻量化。【结果】实验表明,YOLO11-DAE的每秒帧数(Frames Per Second, FPS)为528.100,模型推理速度较快,精确率(Precision,P)、召回率(Recall,R)、综合评价指标(F1-Score, F1)、平均精度均值(Mean Average Precision, mAP)分别达到0.932、0.894、0.913和0.950,显著优于YOLOv5n、YOLOv8n和YOLOv10n算法,相较于YOLOv11n各项指标分别提高7.600%、10.000%、8.800%、8.000%。【结论】YOLO11-DAE算法能够满足矿区实时监测,并适用于多尺度、多背景等复杂场景的目标识别,实现了高精度、低漏检率的监测目标,达到了模型可应用性与实时性的平衡。
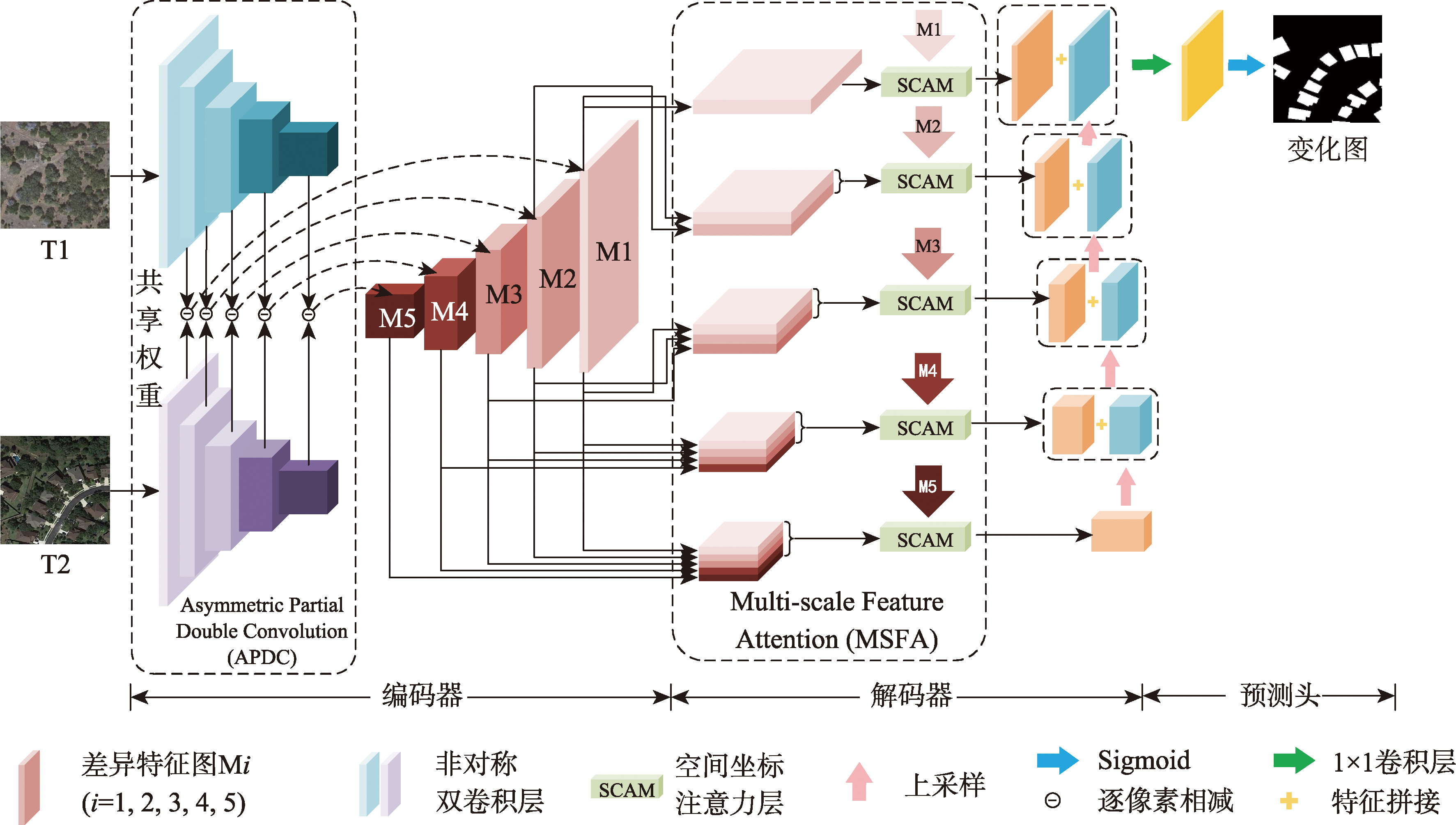
【目的】传统光学遥感变化检测方法步骤繁琐、自动化程度低,而深度学习变化检测方法具有启发继承式特征表达能力,可自动学习变化模式、实现端到端变化检测,显著提升变化检测算法的精度与自动化程度,是遥感大数据时代主流变化检测方法。然而,高分遥感影像地物时空分布复杂度高,现有深度学习变化检测方法往往采用孪生编码器架构提取多时相影像特征并通过特征差值方式提取差异信息,导致差异信息建模能力不足且容易受到复杂背景、阴影和光照等因素干扰。【方法】针对以上问题,本文提出一种基于多尺度差异特征增强的全卷积变化检测网络(Multi-Scale Differential Feature Enhancement Network,MSDFENet),MSDFENet采用孪生编码器架构从双时相遥感影像中提取多尺度特征,通过引入非对称部分双卷积模块(Asymmetric Partial Double Convolution,APDC)降低参数数量、减少冗余信息。进一步地,通过差分运算提取差异特征以捕捉变化信息的多尺度细节。在解码阶段,设计多尺度特征注意力模块(Multi-scale Feature Attention, MSFA),通过引入空间坐标注意力机制实现深层语义特征与浅层几何特征的协同优化。最后,通过渐进式上采样逐级恢复变化区细节信息,并利用简单卷积层输出变化图。【结果】为验证本文方法的有效性,在 LEVIR-CD、CDD和WHU-CD数据集上与主流深度学习变化检测方法进行对比实验与分析,定量结果表明,MSDFENet在3个数据集上均取得更优精度指标,其F1分数分别达到90.68%、94.65%和91.64%, IoU分别达到82.96%、89.78%和84.56%。目视结果显示MSDFENet可有效抑制复杂背景干扰,提高边缘定位精度,取得最优目视效果。模型复杂度分析表明,MSDFENet实现了精度与效率的最佳平衡。【结论】本文提出的MSDFENet可有效增强差异特征表达,在有效抑制复杂背景噪声干扰的同时,显著提升多尺度变化捕捉能力、改善变化检测效果。
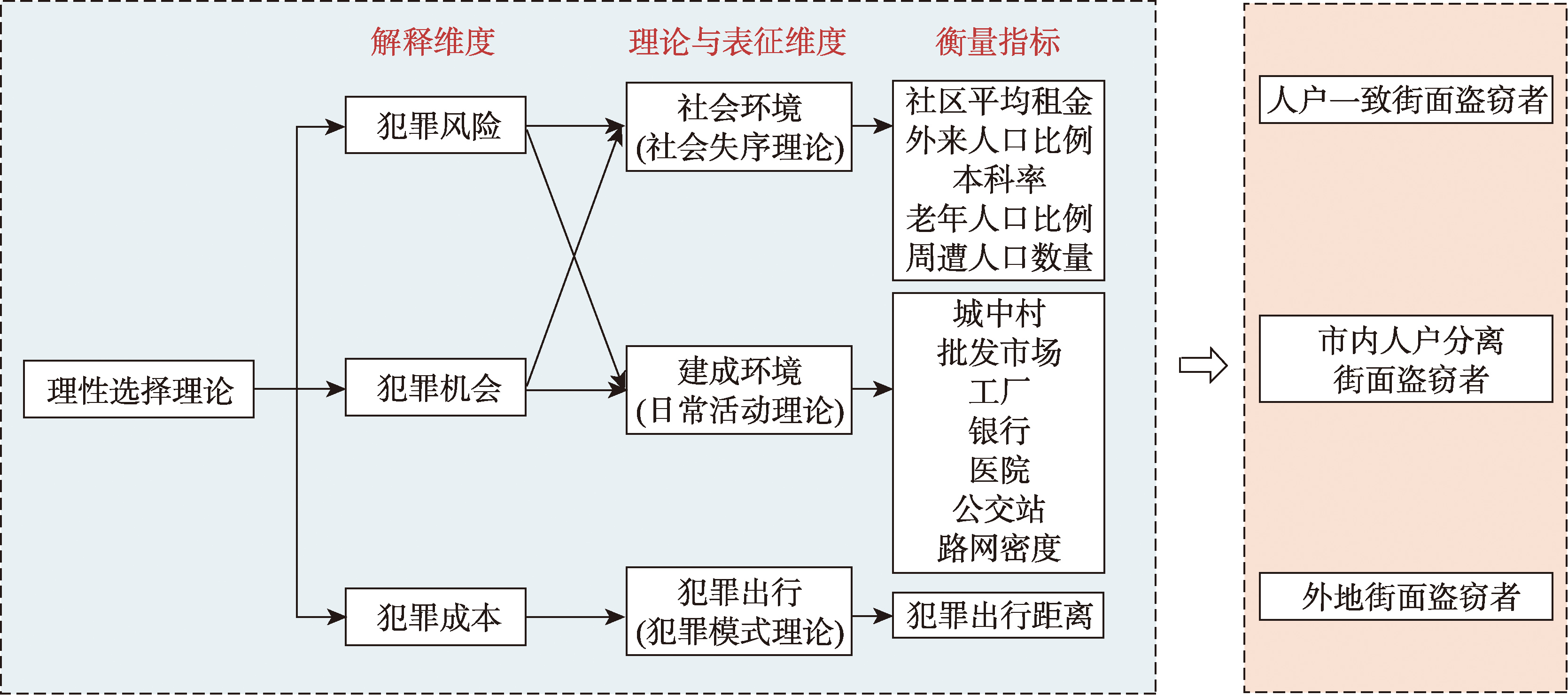
【目的】在中国快速城市化进程中,人口流动性增强,不同户籍犯罪者作案地选择的空间分布差异日益受到关注。但已有研究主要关注本地与外地犯罪者的差异,未能对本地犯罪者进一步细分。本研究旨在将本地犯罪者进行区分——“人户一致”的本地犯罪者与“市内人户分离”的本地犯罪者,揭示不同户籍类型街面盗窃者的犯罪率差异,探究其作案地选择空间分布特征及其影响因素。【方法】本研究以中国ZG市为例,结合犯罪数据、人口普查数据、POI数据、手机信令数据及遥感影像数据,将犯罪者细分为3类:人户一致街面盗窃者、市内人户分离街面盗窃者和外地街面盗窃者,利用核密度估计法和离散选择模型解释不同户籍类型街面盗窃者作案地选择的差异。【结果】① 外地户籍街面盗窃者占同类户籍居民的比例最高,其次是市内人户分离群体,再次是人户一致群体。 ② 人户一致街面盗窃者平均出行距离最远,其次是市内人户分离街面盗窃者,最后是外地街面盗窃者。 ③ 3类街面盗窃者作案热点均在环城高速以内,但仍存在显著的空间差异。人户一致街面盗窃者倾向在老城区作案;市内人户分离街面盗窃者倾向于老城区和中央商务区;外地街面盗窃者的作案地偏向于中央商务区。 ④ 作案地选择偏好呈现户籍差异。关键发现是外来人口比例的影响因街面盗窃者户籍类型而异:对外地街面盗窃者呈正向影响,对市内人户分离街面盗窃者的影响不显著,但对人户一致街面盗窃者则呈负向影响。其他差异具体表现为:人户一致街面盗窃者倾向于避开本科率高的社区,城中村、医院和公交站对其有显著正向影响;老年人口比例高和工厂对市内人户分离街面盗窃者有显著正向影响;老年人口比例、城中村和工厂对外地街面盗窃者有显著正向影响。【结论】本研究通过细分本地街面盗窃者,发现不同户籍街面盗窃者的作案地选择空间分布及其影响因素存在差异,为城市安全规划的优化、执法效率提升以及针对性犯罪预防措施的制定提供了科学依据。
 sciengine
sciengine{kind=link}