
融合网格注意力阀门和特征金字塔结构的高分辨率遥感影像建筑物提取
|
于明洋(1978— ),男,山东东阿人,硕士,副教授,主要从事地理信息工程研发、深度学习和大数据分析研究。 E-mail: ymy@sdjzu.edu.cn |
收稿日期: 2021-09-06
修回日期: 2021-10-16
网络出版日期: 2022-11-25
基金资助
国家自然科学基金项目(41801308)
河北省地震动力学重点实验室开放基金项目(FZ212203)
山东省自然科学基金项目(ZR2021QD074)
国家对地观测科学数据中心开放基金项目(NODAOP2020008)
Building Extraction on High-Resolution Remote Sensing Images Using Attention Gates and Feature Pyramid Structure
Received date: 2021-09-06
Revised date: 2021-10-16
Online published: 2022-11-25
Supported by
National Natural Science Foundation of China(41801308)
Hebei Key Laboratory of Earthquake Dynamics,(FZ212203)
Natural Science Foundation of Shandong Province(ZR2021QD074)
Open Research Fund of National Earth Observation Data Center(NODAOP2020008)
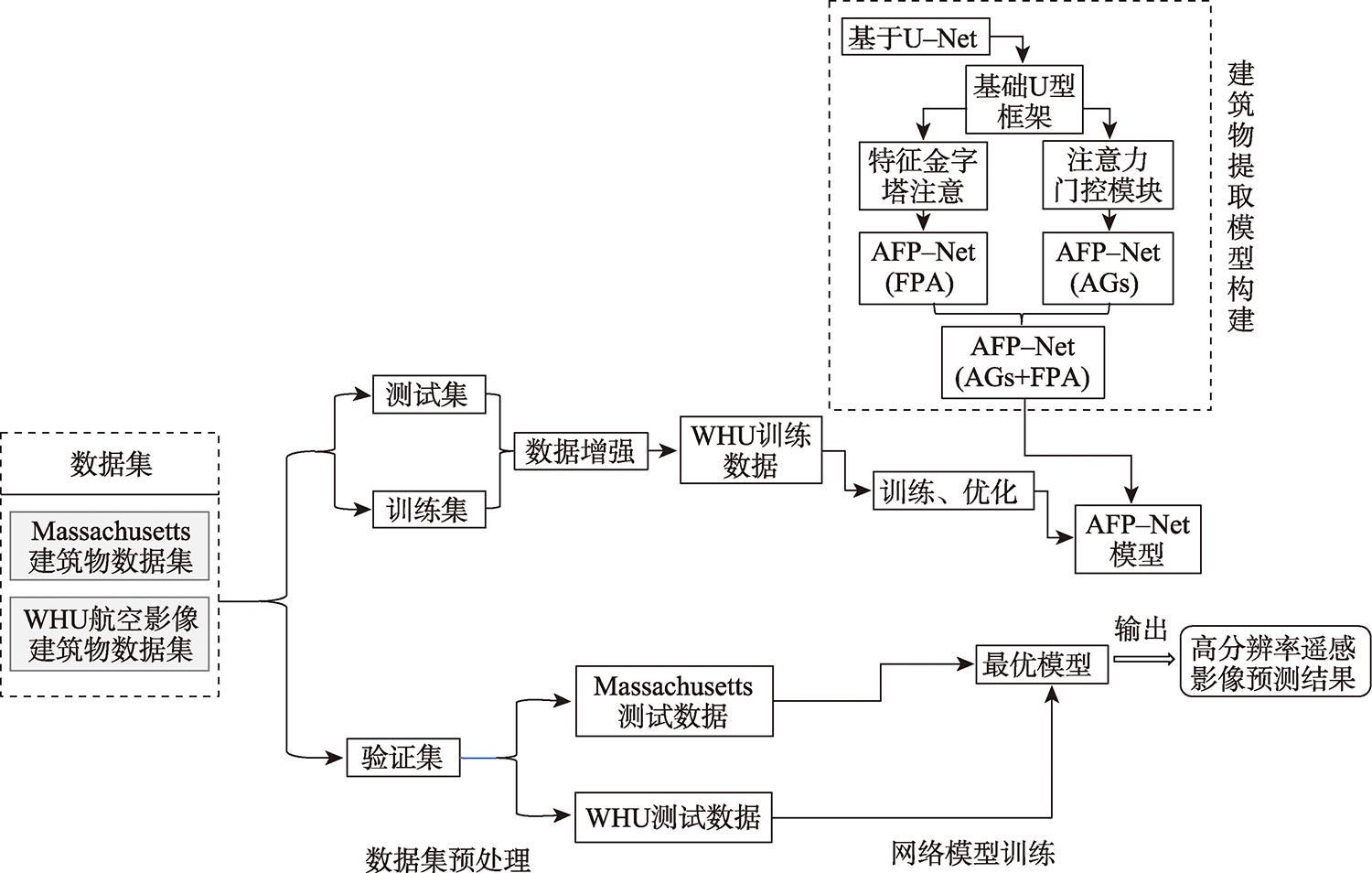
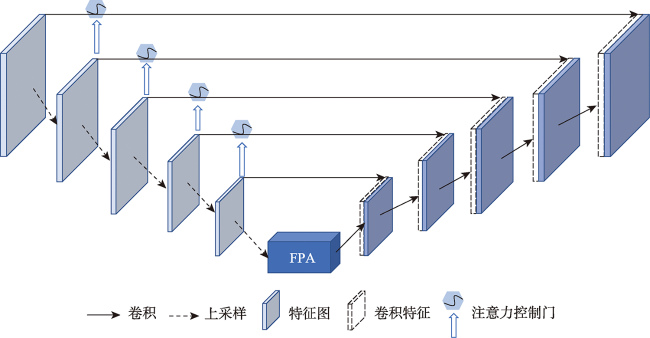
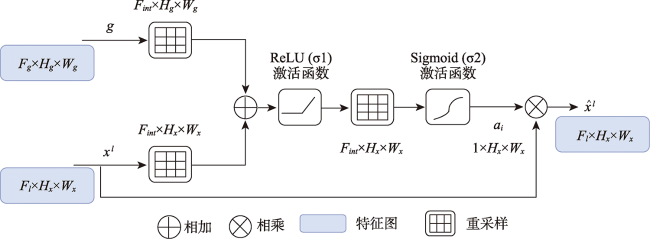
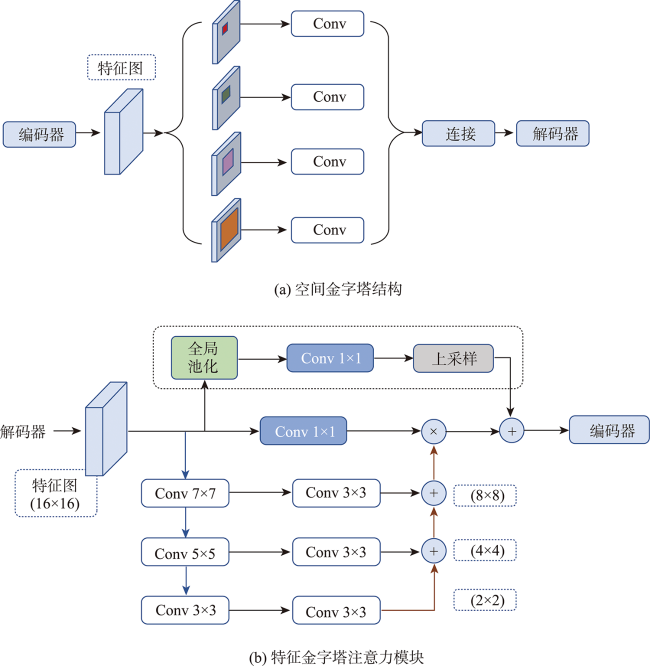
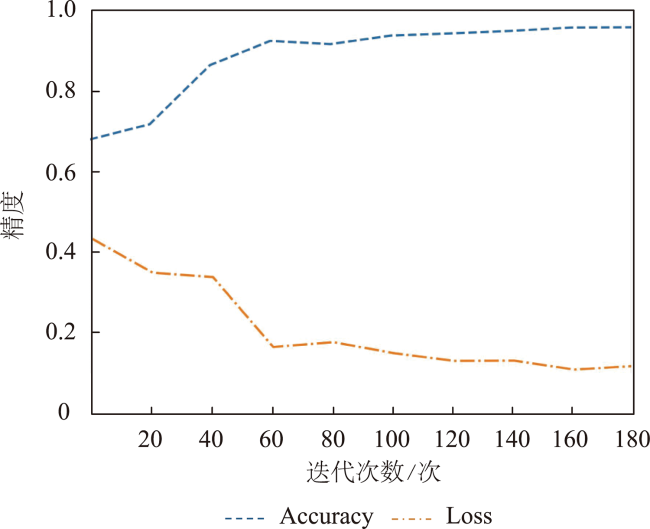
在高分辨率遥感影像中提取建筑物轮廓是地区基础建设信息统计的一项重要任务。适应性较强的深度学习方法已在建筑物提取研究中取得较大进展,受网络模型对影像特征表达的局限性,存在局部建筑轮廓边缘模糊的问题。本研究提出一种基于注意力的U型特征金字塔网络(AFP-Net)可以聚焦高分遥感影像中不同形态的建筑物结构,实现建筑物轮廓的高效提取。AFP-Net模型通过基于网格的注意力阀门Attention Gates模块抑制输入影像中的无关区域,凸出影像中建筑物的显性特征;通过特征金字塔注意力Feature Pyramid Attention模块增加高维特征图的感受野,减少采样中的细节损失。基于WHU建筑物数据集训练优化AFP-Net模型,测试结果表明AFP-Net模型能够较清晰地识别出建筑物轮廓,在预测性能上有更好的目视效果,在测试结果的总体精度和交并比上较U-Net模型分别提高0.67%和1.34%。结果表明,AFP-Net模型实现了高分遥感影像中建筑物提取的结果精度及预测性能的有效提升。
于明洋 , 陈肖娴 , 张文焯 , 刘耀辉 . 融合网格注意力阀门和特征金字塔结构的高分辨率遥感影像建筑物提取[J]. 地球信息科学学报, 2022 , 24(9) : 1785 -1802 . DOI: 10.12082/dqxxkx.2022.210571
Building extraction from high-resolution remote sensing images is an important task of regional infrastructure information statistics. In recent years, due to the rapid development of aviation and aerospace science and technology, the data availability of fine resolution remote sensing images increases. The traditional methods such as manual visual interpretation or expert feature construction cannot balance the high efficiency and high precision for the results generation using high-resolution images. Nowadays, the adaptive deep learning method has gradually made great progress in the study of building extraction. Typically, the U-shaped U-Net network originated from the semantic segmentation model for medical images has been widely used. Its structure has good computational performance and segmentation accuracy and has been used as the basic structure of semantic segmentation for remote sensing images. However, the use of only the basic network model has limitations on the expression of image features, which could cause blurring of local building contour when extracting buildings from high-resolution remote sensing images. This paper proposes an Attention U Feature Pyramid Network (AFP-Net) that can focus on different forms of building structures in high-resolution remote sensing images to efficiently extract the details of buildings. The AFP-Net model suppresses the irrelevant areas in the input image through the grid-based Attention Gates (AGs) module and highlights the dominant features of buildings in the image. The Feature Pyramid Attention (FPA) module increases the receptive field of high dimensional feature map and reduces the loss of detail in sampling. In this paper, the AFP-Net model is trained and optimized based on WHU building dataset. The test results show that, compared with U-Net, the accuracy and Intersection over Union of the proposed method are improved by 0.67 % and 1.34 %, respectively using the test data of WHU dataset. In addition, this paper compares the detailed features of different models for convex and concave parts of the building contour, and the AFP-Net model can clearly identify the edge of the building. The results demonstrate that the proposed method can effectively improve the prediction accuracy of building detail extraction.
表1 AFP-Net的参数统计Tab. 1 Parameter statistics of AFP-Net |
| 结构块 | 类别 | 核尺寸 | 输出通道数 | 输出尺寸/pixel |
|---|---|---|---|---|
| Block 1-4 | Conv1 | (3, 3) | 64 | 256×256 |
| Maxpool1 | (2, 2) | 64 | 128×128 | |
| Conv2 | (3, 3) | 128 | 128×128 | |
| Maxpool2 | (2, 2) | 128 | 64×64 | |
| Conv3 | (3, 3) | 256 | 64×64 | |
| Maxpool3 | (2, 2) | 256 | 32×32 | |
| Conv4 | (3, 3) | 512 | 32×32 | |
| Maxpool4 | (2, 2) | 512 | 16×16 | |
| Block 5 | PPM | 1024 | 16×16 | |
| Block 6-9 | Up_conv4 | Up-(3, 3) Conv-(2, 2) | 512 | 32×32 |
| AG4 | 512 | 32×32 | ||
| Up4 | 512 | 32×32 | ||
| Up_conv3 | Up-(3, 3) Conv-(2, 2) | 256 | 64×64 | |
| AG3 | 256 | 64×64 | ||
| Up3 | 256 | 64×64 | ||
| Up_conv2 | Up-(3, 3) Conv-(2, 2) | 128 | 128×128 | |
| AG2 | 512 | 128×128 | ||
| Up2 | 512 | 128×128 | ||
| Up_conv1 | Up-(3, 3) Conv-(2, 2) | 64 | 256×256 | |
| AG 1 | 64 | 256×256 | ||
| Up1 | 64 | 256×256 | ||
| Block 10 | Conv_1x1 | (1, 1) | 1 | 256×256 |
| Sigmoid | 1 | 256×256 |
表2 各模型定量指标的验证集精度统计Tab. 2 Validation set precision statistics table of models quantitative indexes(%) |
| 模型 | 总体精度 | 精密度 | 交并比 |
|---|---|---|---|
| FCN8s | 0.9574 | 0.9439 | 0.7857 |
| SegNet | 0.9487 | 0.9102 | 0.7761 |
| DANet | 0.9207 | 0.9555 | 0.7519 |
| PSPNet | 0.9661 | 0.9491 | 0.8681 |
| U-Net | 0.9601 | 0.9582 | 0.8568 |
| AFP-Net | 0.9668 | 0.9490 | 0.8702 |
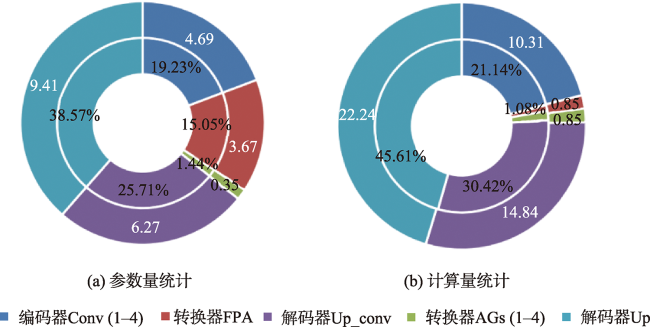
表3 不同模型的参数量、计算量和训练时间的统计Tab. 3 Statistical table of parameters, calculation and training time of six models |
| 模型 | 参数量/M | 计算量/(G Mac) | 训练时间(s/epoch) |
|---|---|---|---|
| SegNet | 16.31 | 23.77 | 222 |
| FCN8s | 134.27 | 62.81 | 393 |
| DANet | 49.48 | 10.93 | 335 |
| PSPNet | 31.2 | 11.03 | 225 |
| U-Net | 13.4 | 23.77 | 212 |
| AFP-Net | 27.95 | 48.76 | 295 |
注:加粗值为各列最优值。 |
表4 模型实验结果对比Tab. 4 Comparison of models' experiment results |
| 模型 | 总体精度/% | 精密度/% | 交并比/% | 参数量/M | 计算量/(G Mac) | 训练时间/(s/epoch) |
|---|---|---|---|---|---|---|
| U型基础架构 | 0.9410 | 0.9745 | 0.8336 | 34.53 | 50.65 | 312 |
| AFP-Net (AGs) | 0.9701 | 0.9616 | 0.9034 | 34.88 | 51.76 | 316 |
| AFP-Net (FPA) | 0.9613 | 0.9862 | 0.8811 | 27.6 | 47.65 | 287 |
| AFP-Net (AGs + FPA) | 0.9731 | 0.9723 | 0.9112 | 27.95 | 48.76 | 295 |
注:加粗值为各列最优值。 |
| [1] |
吴炜, 骆剑承, 沈占锋, 等. 光谱和形状特征相结合的高分辨率遥感图像的建筑物提取方法[J]. 武汉大学学报·信息科学版, 2012, 37(7):800-805.
[
|
| [2] |
|
| [3] |
杜培军, 夏俊士, 薛朝辉, 等. 高光谱遥感影像分类研究进展[J]. 遥感学报, 2016, 20(2):236-256.
[
|
| [4] |
|
| [5] |
|
| [6] |
黄金库, 冯险峰, 徐秀莉, 等. 基于知识规则构建和形态学修复的建筑物提取研究[J]. 地理与地理信息科学, 2011, 27(4):28-31.
[
|
| [7] |
方鑫, 陈善雄. 密集城区高分辨率遥感影像建筑物提取[J]. 测绘通报, 2019(4):79-83.
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
陈凯强, 高鑫, 闫梦龙, 等. 基于编解码网络的航空影像像素级建筑物提取[J]. 遥感学报, 2020, 24(9):1134-1142.
[
|
| [22] |
|
| [23] |
朱盼盼, 李帅朋, 张立强, 等. 基于多任务学习的高分辨率遥感影像建筑提取[J]. 地球信息科学学报, 2021, 23(3):514-523.
[
|
| [24] |
|
| [25] |
谢跃辉, 李百寿, 刘聪娜. 结合多种影像特征与CNN的城市建筑物提取[J]. 遥感信息, 2020, 35(5):80-88.
[
|
| [26] |
刘亦凡, 张秋昭, 王光辉, 等. 利用深度残差网络的遥感影像建筑物提取[J]. 遥感信息, 2020, 35(2):59-64.
[
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
唐璎, 刘正军, 杨懿, 等. 基于特征增强和ELU的神经网络建筑物提取研究[J]. 地球信息科学学报, 2021, 23(4):692-709.
[
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
刘耀辉. 面向地震风险评估的高分辨率遥感影像建筑物信息提取与研究[D]. 北京: 中国地震局地质研究所, 2020.
[
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}